Решение задачи "Разработка алгоритмов решения основных задач АСУ"
Как было показано в разделе 3.2, решение задачи 3 предполагает решение следующих подзадач.
Решение подзадачи 3.1: "Расчет влияния факторов на переход объекта управления в различные состояния (обучение, адаптация)"
При изменении объема обучающей выборки или изменении экспертных оценок прежде всего пересчитывается матрица абсолютных частот, а затем, на ее основании и в соответствии с выражением (3.28), - матрица информативностей. Таким образом, предложенная модель обеспечивает отображение динамических взаимосвязей, с одной стороны, между входными и выходными параметрами, а с другой, - между параметрами и состояниями объекта управления. Конкретно, это отображение осуществляется в форме так называемых векторов факторов и состояний.
В профиле (векторе) i–го фактора (строка матрицы информативностей) отображается, какое количество информации о переходе АОУ в каждое из возможных состояний содержится в том факте, что данный фактор действует.
В профиле (векторе) j–го состояния АОУ (столбец матрицы информативностей) отображается, какое количество информации о переходе АОУ в данное состояние содержится в каждом из факторов.
Решение подзадачи 3.2: "Прогнозирование поведения объекта управления при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (обратная задача прогнозирования)"
Прогнозирование состояния АОУ осуществляется следующим образом:
1. Собирается информация о действующих факторах, характеризующих состояние предметной области (активный объект управления описывается факторами, характеризующими его текущее и прошлые состояния; управляющая система характеризуется технологическими факторами, с помощью которых она оказывает управляющее воздействие на активный объект управления; окружающая среда характеризуется прошлыми, текущими и прогнозируемыми факторами, которые также оказывают воздействие на активный объект управления).
2. Для каждого возможного будущего состояния АОУ подсчитывается суммарное количество информации, содержащееся во всей системе факторов (согласно п.1), о наступлении этого состояния.
3. Все будущие состояния АОУ ранжируются в порядке убывания количества информации об их осуществлении.
Этот ранжированный список будущих состояний АОУ и представляет собой первичный результат прогнозирования.
Если задано некоторое определенное целевое состояние, то выбор управляющих воздействий для фактического применения производится из списка, в котором все возможные управляющие воздействия расположены в порядке убывания их влияния на перевод АОУ в данное целевое состояние. Такой список называется информационным портретом состояния АОУ [64].
Управляющие воздействия могут быть объединены в группы, внутри каждой из которых они альтернативны (несовместны), а между которыми - нет (совместны). В этом случае внутри каждой группы выбирают одно из фактически доступных управляющих воздействий с максимальным влиянием на достижение заданного целевого состояния АОУ.
Однако выбор многофакторного управляющего воздействия нельзя считать завершенным без прогнозирования результатов его применения. Описание АОУ в актуальном состоянии состоит из списка факторов окружающей среды, предыстории АОУ, описания его актуального (исходного) состояния, а также выбранных управляющих воздействий. Имея эту информацию по каждому из факторов в соответствии с выражением (3.39), нетрудно подсчитать, какое количество информации о переходе в каждое из состояний содержится суммарно во всей системе факторов. Данный метод соответствует фундаментальной лемме Неймана–Пирсона, содержащей доказательство оптимальности метода выбора той из двух статистических гипотез, о которой в системе факторов содержится больше информации. В то же время он является обобщением леммы Неймана–Пирсона, так как вместо информационной меры Шеннона используется системное обобщение семантической меры целесообразности информации Харкевича.
Предлагается еще одно обобщение этой фундаментальной леммы, основанное на косвенном учете корреляций между информативностями в профиле состояния при использовании среднего по профилю. Соответственно, вместо простой суммы количеств информации предлагается использовать ковариацию между векторами состояния и АОУ, которая количественно измеряет степень сходства формы этих векторов.
Результат прогнозирования поведения АОУ, описанного данной системой факторов, представляет собой список состояний, в котором они расположены в порядке убывания суммарного количества информации о переходе АОУ в каждое из них.
Решение подзадачи 3.3: "Выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; снижение размерности модели при заданных ограничениях"
Естественно считать, что некоторый фактор является тем более ценным, чем больше среднее количество информации, содержащееся в этом факторе о поведении АОУ [64]. Но так как в предложенной модели количество информации может быть и отрицательным (если фактор уменьшает вероятность перехода АОУ в некоторое состояние), то простое среднее арифметическое информативностей может быть близко к нулю. При этом среднее будет равно нулю и в случае, когда все информативности равны нулю, и тогда, когда они будут велики по модулю, но с разными знаками. Следовательно, более адекватной оценкой полезности фактора является среднее модулей или, что наиболее точно, исправленное (несмещенное) среднеквадратичное отклонение информативностей по профилю признака.
Ценность фактора по сути дела определяется его полезностью для различения состояний АОУ, т.е. является его дифференцирующей способностью или селективностью.
Необходимо также отметить, что различные состояния АОУ обладают различной степенью обусловленности, т.е. в различной степени детерминированы факторами: некоторые слабо зависят от учтенных факторов, тогда как другие определяются ими практически однозначно. Количественно детерминируемость состояния АОУ предлагается оценивать стандартным отклонением информативностей вектора обобщенного образа данного состояния.
Предложено и реализовано несколько итерационных алгоритмов корректного удаления малозначимых факторов и слабодетерминированных состояний АОУ при заданных граничных условиях [64]. Решение задачи снижения размерности модели АОУ при заданных граничных условиях позволяет снизить эксплуатационные затраты и повысить эффективность РАСУ АО.
Решение подзадачи 3.4: " Сравнение влияния факторов. Сравнение состояний объекта управления"
Факторы могут сравниваться друг с другом по тому влиянию, которое они оказывают на поведение АОУ. Сами состояния могут сравниваться друг с другом по тем факторам, которые способствуют или препятствуют переходу АОУ в эти состояния. Это сравнение может содержать лишь результат, т.е. различные степени сходства/различия (в кластерном анализе), или содержать также причины этого сходства/различия (в когнитивных диаграммах).
Эти задачи играют важную роль в теории и практике РАСУ АО при необходимости замены одних управляющих воздействий другими, но аналогичными по эффекту, а также при изучении вопросов семантической устойчивости управления (различимости состояний АОУ по детерминирующим их факторам).
Этот анализ проводится над классами распознавания и над признаками. Он включает: информационный (ранговый) анализ; кластерный и конструктивный анализ, семантические сети; содержательное сравнение информационных портретов, когнитивные диаграммы.
Семантический информационный анализ
Предложенная математическая модель позволяет сформировать информационные портреты обобщенных эталонных образов классов распознавания и признаков.
Портреты классов распознавания представляют собой списки признаков в порядке убывания содержащегося в них количества информации о принадлежности к этим классам.
Информационный портрет класса распознавания показывает нам, каков информационный вклад каждого признака в общий объем информации, содержащейся в обобщенном образе этого класса.
В подходе к решению задач рефлексивных АСУ АО, основанном на применении методов распознавания образов, классам распознавания соответствуют, во–первых, исходные, а во–вторых, результирующие, в том числе целевые состояния объекта управления. Это значит, что в первом случае портреты классов используются для идентификации исходного состояния АОУ, потому что именно с ними сравнивается состояние объекта управления, а во втором – для выработки управляющего воздействия, так как его выбирают в форме суперпозиции неальтернативных факторов из информационного портрета целевого состояния, оказывающих наибольшее влияние на перевод АОУ в это состояние.
Портреты признаков представляют собой списки классов распознавания в порядке убывания количества информации о них, которое содержит данный признак. По своей сути информационный портрет признака раскрывает нам смысл данного признака, т.е. его семантическую нагрузку. В теории и практике рефлексивных АСУАО информационный портрет фактора является развернутой количественной характеристикой, содержащей информацию о силе и характере его влияния на перевод АОУ в каждое из возможных результирующих состояний, в том числе в целевые. Информационные портреты классов и признаков допускают наглядную графическую интерпретацию в виде двухмерных (2d) и трехмерных (3d) диаграмм.
Кластерно-конструктивный анализ и семантические сети
Кластеры представляют собой такие группы классов распознавания (или признаков), внутри которых эти классы наиболее схожи друг с другом, а между которыми наиболее различны [64]. В данной работе, в качестве классов распознавания рассматриваются как исходные, так и результирующие, в том числе целевые состояния объекта управления, а в качестве признаков – факторы, влияющие на переход АОУ в результирующие состояния.
Исходные состояния АОУ, объединенные в кластер, характеризуются общими или сходными методами перевода в целевые состояния. Результирующие состояния АОУ, объединенные в кластер, являются слаборазличимыми по факторам, детерминирующим перевод АОУ в эти состояния. Это означает, что одно и то же управляющее воздействие при одних и тех же предпосылках (исходном состоянии и предыстории объекта управления и среды) могут привести к переводу АОУ в одно из результирующих состояний, относящихся к одному кластеру. Поэтому кластерный анализ результирующих состояний АОУ является инструментом, позволяющим изучать вопросы устойчивости управления сложными объектами.
При выборе управляющего воздействия как суперпозиции неальтернативных факторов часто возникает вопрос о замене одних управляющих факторов другими, имеющими сходное влияние на перевод АОУ из данного текущего состояния в заданное целевое состояние.
Кластерный анализ факторов как раз и позволяет решить эту задачу: при невозможности применить некоторый управляющий фактор его можно заменить другим фактором из того же кластера.
При формировании кластеров используются матрицы сходства объектов и признаков, формируемые на основе матрицы информативностей.
В соответствии с предлагаемой математической моделью могут быть сформированы кластеры для заданного диапазона кодов классов распознавания (признаков) или заданных диапазонов уровней системной организации с различными критериями включения объекта (признака) в кластер.
Эти критерии могут быть сформированы автоматически либо заданы непосредственно. В последнем уровне кластеризации, в частности при задании одного уровня, в кластеры включаются не только похожие, но и все непохожие объекты (признаки), и, таким образом, формируются конструкты классов распознавания и признаков.
В данной работе под конструктом понимается система противоположных (наиболее сильно отличающихся) кластеров, которые называются "полюсами" конструкта, а также спектр промежуточных кластеров, к которым применима количественная шкала измерения степени их сходства или различия [64].
Понятия "кластер" и "конструкт" тесно взаимосвязаны:
– так как положительный и отрицательный полюса конструкта представляют собой кластеры, в наибольшей степени отличающиеся друг от друга, то конструкты могут быть получены как результат кластерного анализа кластеров;
– конструкт может рассматриваться как кластер с нечеткими границами, включающий в различной степени, причем не только в положительной, но и отрицательной, все классы (признаки).
В теории рефлексивных АСУ АО, конструктивный анализ позволяет решить такие задачи, как:
1. Определение в принципе совместимых и в принципе несовместимых целевых состояний АОУ. Совместимыми называются целевые состояния, для достижения которых необходимы сходные предпосылки и управляющие воздействия, а несовместимыми – для которых они должны быть диаметрально противоположными.
Например, обычно сложно совмещаются такие целевые состояния, как очень высокое качество продукции и очень большое ее количество.
2. Определение факторов, имеющих не только сходное (это возможно и на уровне кластерного анализа), но и совершенно противоположное влияние на поведение сложного объекта управления.
Современный интеллект имеет дуальную структуру и, по сути дела, мыслит в системе кластеров и конструктов. Поэтому инструмент автоматизированного кластерно–конструктивного анализа может быть успешно применен для рефлексивного управления активными объектами.
Необходимо отметить, что формирование кластеров затруднено из-за проблемы комбинаторного взрыва, так как требует полного перебора и проверки "из n по m" сочетаний элементов (классов или признаков) в кластеры. Конструкты же формируются непосредственно из матрицы сходства прямой выборкой и сортировкой, что значительно проще в вычислительном отношении, так как конструктов значительно меньше, чем кластеров (всего n2). Поэтому учитывая, что при формировании конструктов автоматически формируются и их полюса, т.е. кластеры, в предложенной математической модели реализован не кластерный анализ, а сразу конструктивный (как более простой в вычислительном отношении и более ценный по получаемым результатам).
Диаграммы смыслового сходства–различия классов (признаков) соответствуют определению семантических сетей [64], т.е. представляют собой ориентированные графы, в которых признаки соединены линиями, соответствующими их смысловому сходству–различию.
Когнитивные диаграммы классов и признаков
В предложенной в настоящем исследовании математической модели в обобщенной постановке реализована возможность содержательного сравнения обобщенных образов классов распознавания и признаков, т.е. построения когнитивных диаграмм [64].
В информационных портретах классов
распознавания мы видим, какое количество информации о принадлежности (или не принадлежности) к данному классу мы получаем, обнаружив у некоторого объекта признаки, содержащиеся в информационном портрете.
В кластерно- конструктивном анализе мы получаем результаты сравнения классов распознавания друг с другом, т.е. мы видим, насколько они сходны и насколько отличаются. Но мы не видим, какими признаками они похожи и какими отличаются, и какой вклад каждый признак вносит в сходство или различие некоторых двух классов.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили два информационных портрета. Эту работу и осуществляет режим содержательного сравнения классов распознавания.
Аналогично, в информационных портретах признаков
мы видим, какое количество информации о принадлежности (или не принадлежности) к различным классам распознавания мы получаем, обнаружив у некоторого объекта данный признак. В кластерно-конструктивном анализе мы получаем результаты сравнения признаков друг с другом, т.е. мы видим, насколько они сходны и насколько отличаются. Но мы не видим, какими классами они похожи и какими отличаются, и какой вклад каждый класс вносит в смысловое сходство или различие некоторых двух признаков.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили информационные портреты двух признаков. Эту работу и осуществляет режим содержательного (смыслового) сравнения признаков.
Содержательное (смысловое) сравнение классов
Обобщим математическую модель, предложенную и развиваемую в данной главе, на случай содержательного сравнения двух классов распознавания: J–го и L–го.
Признаки, которые есть по крайней мере в одном из классов, будем называть связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие по смыслу, они вносят определенный вклад в отношения сходства/различия между классами.
Список выявленных связей сортируется в порядке убывания модуля силы связи, причем учитывается не более заданного количества связей.
Пусть, например:
у J–го класса обнаружен i–й признак,
у L–го класса обнаружен k–й признак.
Используем те же обозначения, что и в разделе 3.1.
На основе обучающей выборки системой рассчитывается матрица абсолютных частот встреч признаков по классам (таблица 15).
В разделе 3.1. получено выражение (3.28) для расчета количества информации в i–м признаке о принадлежности некоторого конкретного объекта к j–му классу (плотность информации), которое имеет вид:
 |
(3.28) |
Аналогично, формула для количества информации в k–м признаке о принадлежности к L–му классу имеет вид:
 |
(3. 42) |
Вклад некоторого признака i в сходство/различие двух классов j и l равен соответствующему слагаемому корреляции образов этих классов, т.е. просто произведению информативностей
 |
(3. 43) |
Классический коэффициент корреляции Пирсона, количественно определяющий степень сходства векторов двух классов: j и l, на основе учета вклада каждой связи, образованной i–м признаком, рассчитывается по формуле
 |
(3. 44) |
где:
 |
– средняя информативность признаков j–го класса; |
 |
– средняя информативность признаков L–го класса; |
 |
– среднеквадратичное отклонение информативностей признаков j–го класса; |
 |
– среднеквадратичное отклонение информативностей признаков L–го класса. |
Проанализируем, насколько классический коэффициент корреляции Пирсона (3.62) пригоден для решения важных задач:
– содержательного сравнения классов;
– изучения внутренней многоуровневой структуры класса.
Упростим анализ, считая, что средние информативности признаков по обоим классам близки к нулю, что при достаточно больших выборках (более 400 примеров в обучающей выборке) практически близко к истине.
Каждое слагаемое (3.43) суммы (3.44) отражает связь между классами, образованную одним i–м признаком. I–я связь существует в том и только в том случае, если i–й признак есть у обоих классов. Поэтому эти связи уместно называть одно–однозначными.
Этот подход можно назвать классическим для когнитивного анализа. Рассмотрим когнитивную диаграмму, приведенную на стр. 222 работы основной работы классика когнитивной психологии Р.Солсо (Когнитивная психология. /Пер. с англ. - М.: Тривола, 1996. - 600с.) (рисунок 31).
 |
|
Рисунок 31. Когнитивная диаграмма из классической работы Роберта Солсо. |
В приведенной когнитивной диаграмме наглядно в графической форме показано сравнение классов (обобщенных образов) "Малиновка" и "Птица" разных уровней общности по их атрибутам (признакам). Как видно из диаграммы, в ней:
1. Все атрибуты имеют одинаковый вес, т.е. не учитывается, что некоторые атрибуты более важны для идентификации класса, чем другие. Это соответствует предположению, что этот вес равен по модулю 1 для всех атрибутов.
2. Все признаки имеют одинаковый знак, т.е. они все характерны для классов и нет атрибутов нехарактерных. Это соответствует предположению, что вес всех признаков положительный, т.е. все признаки вносят вклад в сходство и нет признаков, вносящих вклад в различие.
3. Классы сравниваются только по тем атрибутам, которые есть одновременно у них обоих, т.е. признаки, имеющиеся у обоих классов вносят вклад в сходство классов, а признаки, которые есть только у одного из классов не вносят никакого вклада ни в сходство классов, ни в различие. Это соответствует предположению, что атрибуты ортонормированы, т.е. корреляция их друг с другом равна 0 (атрибуты семантически не связаны).
Каждое из этих трех допущений является довольно сильным и желательно их снять и, тем самым, обобщить принцип построения когнитивных диаграмм, приведенный в данном примере.
Но это означает, что данный подход не позволяет сравнивать классы, описанные различными, т.е. непересекающимися наборами признаков. Но даже если общие признаки и есть, то невозможность учета вклада остальных признаков является недостатком классического подхода, так как из содержательного анализа связей неконтролируемо исключается потенциально существенная информация. Таким образом, классический подход имеет ограниченную применимость при решении задачи №1. Для решения задачи №2 подход, основанный на формуле (3.44), вообще не применим, так как различные уровни системной организации классов образованы различными признаками и, следовательно, между уровнями не будет ни одной одно–однозначной связи.
Основываясь на этих соображениях, предлагается в общем случае учитывать вклад в сходство/различие двух классов, который вносят не только общие, но и остальные признаки. Логично предположить, что этот вклад (при прочих равных условиях) будет тем меньше, чем меньше корреляция между этими признаками.
Следовательно, для обобщения выражения для силы связи (3.43) необходимо умножить произведение информативностей признаков на коэффициент корреляции между ними, отражающий степень сходства или различия признаков по смыслу.
Таким образом, будем считать, что любые два признака (i,k) вносят определенный вклад в сходство/различие двух классов (j,l), определяемый сходством/различием признаков и количеством информации о принадлежности к этим классам, которое содержится в данных признаках:
 |
(3. 45) |
где:

 |
(3. 46) |
где
 |
– средняя информативность координат вектора i–го признака; |
 |
– средняя информативность координат вектора k–го признака; |
 |
– среднеквадратичное отклонение координат вектора i–го признака; |
 |
– среднеквадратичное отклонение координат вектора k–го признака. |
Коэффициент корреляции между признаками (3.46) рассчитывается на основе всей обучающей выборки, а не только объектов двух сравниваемых классов. Так как коэффициент корреляции между признаками (3.46) практически всегда не равен нулю, то каждый признак i образует связи со всеми признаками k, где k={1,...,A}, а каждый признак k в свою очередь связан со всеми остальными признаками. Это означает, что выражение (3.45) является обобщением (3.43) с учетом много-многозначных связей.
На основе этих представлений сформулируем выражение для обобщенного коэффициента корреляции Пирсона между двумя классами: j и l, учитывающего вклад в их сходство/различие не только одно–однозначных, но и много–многозначных связей, образуемых коррелирующими признаками.
Когнитивные диаграммы с много–многозначными связями предлагается называть обобщенными когнитивными диаграммами.
 |
(3. 47) |
где Kik определяется выражением (3.46).
Сравним классический (3.44) и обобщенный (3.47) коэффициенты корреляции Пирсона друг с другом. Очевидно, при i=k (3.47) преобразуется в (3.44), т.е. соблюдается принцип соответствия. Отметим, что модель позволяет задавать минимальный коэффициент корреляции (порог) между признаками, образующими учитываемые связи. При пороге 100% отображаются только одно–однозначные связи, учитываемые в классическом коэффициенте корреляции (3.44). Из выражений (3.47) и (3.44) видно, что
 |
(3. 48) |
так как в обобщенном коэффициенте корреляции учитываются связи между классами, образованные за счет учета корреляций между различными признаками. Ясно, что отношение
 |
(3. 49) |
отражает степень избыточности описания классов. В модели имеется возможность исключения из системы признаков наименее ценных из них для идентификации классов. При этом в первую очередь удаляются сильно коррелирующие друг с другом признаки. В результате степень избыточности системы признаков уменьшается, и она становится ближе к ортонормированной.
Рассмотрим вопрос о единицах измерения, в которых количественно выражаются связи между классами.
Сходство двух признаков

Максимальная теоретически возможная информативность признака в Bit выражается формулой
 |
(3. 50) |
Таким образом, учитывая выражения (3.45) и (3.50) получаем, что максимальная теоретически возможная сила связи Rmax
равна
 |
(3. 51) |
В разработанном инструментарии СК-анализа, реализующем данную модель (описанном в лекции 6), реализован режим отображения когнитивной графики, где фактическая сила связи (3.45) в когнитивных диаграммах выражается в процентах от максимальной теоретически возможной силы связи (3.50). На графической диаграмме (рисунок 32) отображается 8 наиболее сильных по модулю связей, рассчитанных согласно формулы (3.47), причем знак связи изображается цветом (красный +, синий – ), а величина – толщиной линии.
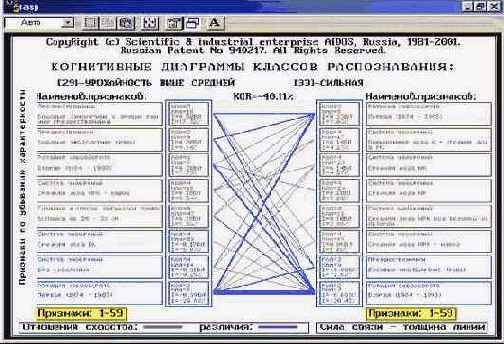 |
|
Рисунок 32. Когнитивная диаграмма конструкта классов "Качество-количество" |
Имеется возможность выводить диаграммы только с положительными или только с отрицательными связями (для не цветных принтеров).
Частным случаем предложенных в данной работе обобщенных когнитивных диаграмм являются известные диаграммы В.С.Мерлина (Очерк интегрального исследования индивидуальности. - М., 1986. - 187с.). Эти диаграммы представляют обобщенные когнитивные диаграммы, формируемые в соответствии с предложенной моделью при следующих граничных условиях:
1. Класс сравнивается сам с собой.
2. Фильтрация левого и правого информационных портретов выбрана по уровням системной организации признаков (в данном случае – уровням Мерлина, терм. авт.).
3. Левый класс отображается с фильтрацией по одному уровню системной организации, а правый – по другому.
4. Диалог задания вида диаграмм предоставляет пользователю возможность задать следующие параметры:
– способ нормирования толщины линий, отображающих связи: нормирование по текущей диаграмме или по всем диаграммам;
– способ фильтрации признаков в информационных портретах диаграммы: по диапазону признаков или по диапазону уровней системной организации (уровням Мерлина);
– сами диапазоны признаков или уровней для левого и правого информационных портретов;
– максимальное количество связей, отображаемых на диаграмме;
– уровень сходства признаков, образующих одну связь, отображаемую на диаграмме: от 0 до 100%. При уровне сходства 100% в диаграммах отображаются только связи, образованные теми признаками, которые есть в обоих портретах одновременно, т.е. взаимно–однозначные связи. При уровне сходства менее 100% вообще говоря связи становятся много–многозначными, так как каждый признак корреляционно связан со всеми остальными;
– уровень сходства классов, отображаемых на диаграмме.
Таким образом, в предлагаемой математической модели в общем виде реализована возможность содержательного сравнения обобщенных образов состояний АОУ и факторов, т.е.
построения когнитивных диаграмм [64], веса атрибутов определяются автоматически на основе исходных данных в соответствии с математической моделью и могут принимать различные по величине положительные и отрицательные значения. Кроме того на основе кластерного анализа атрибутов определяются корреляции между ними, которые учитываются при определении вклада атрибутов в сходство или различие классов. Поэтому отношения между атрибутами разных классов в когнитивной диаграмме не "один к одному", как в диаграмме на рисунке 31, а "многие ко многим" (рисунок 32).
В информационном портрете состояния АОУ показано, какое количество информации о принадлежности (не принадлежности) АОУ к данному состоянию, а также о переходе (не переходе) АОУ в данное состояние содержится в том факте, что на АОУ действуют факторы, содержащиеся в данном информационном портрете.
Кластерно-конструктивный анализ дает результат сравнения состояний АОУ друг с другом, т.е. показывает, насколько эти состояния сходны друг с другом и насколько отличаются друг от друга. Но он не показывает, какими факторами эти состояния АОУ похожи и какими отличаются, и какой вклад
каждый фактор вносит в сходство или различие каждых двух состояний. Чтобы получить эту информацию, необходимо проанализировать два информационных портрета, что и делается при содержательном сравнении состояний АОУ .
Смысл и значение диаграмм Мерлина применительно к проблематике АСУ состоит в том, что они наглядно представляют внутреннюю структуру детерминации состояний АОУ, т.е. показывают, каким образом связаны друг с другом факторы и будущие состояния АОУ.
Таким образом:
– для моделирования процессов принятия решений в рефлесивных АСУ активными системами целесообразно применение многокритериального подхода с аддитивным интегральным критерием, в котором в качестве частных критериев используется семантическая мера целесообразности информации (Харкевич, 1960);
– предложенная математическая модель обеспечивает эффективное решение следующих задач, возникающих при синтезе адаптивных АСУ АОУ: разработка абстрактной информационной модели АОУ; адаптация и конкретизация абстрактной модели на основе апостериорной информации о реальном поведении АОУ; расчет влияния факторов на переход АОУ в различные возможные состояния; прогнозирование поведения АОУ при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (основная задача АСУ); выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; контролируемое удаление второстепенных факторов с низкой дифференцирующей способностью, т.е.
снижение размерности модели при заданных ограничениях; сравнение влияния факторов, сравнение целевых и других состояний АОУ.
Предложенная методология, основанная на теории информации, обеспечивает эффективное моделирование задач принятия решений в адаптивных АСУ сложными системами.
Содержательное (смысловое) сравнение признаков
Предложенная математическая модель позволяет осуществить содержательное сравнение информационных портретов двух признаков.
Выявляются классы, которые есть по крайней мере в одном из векторов. Такие классы называются связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие, они вносят определенный вклад в отношения сходства/различия между признаками по смыслу.
Все связи между признаками сортируются в порядке убывания модуля, в соответствии с определенными ограничениями, связанными с тем, что нет необходимости учитывать очень слабые связи.
Для каждого класса известно, какое количество информации о принадлежности к нему содержит данный признак – это информативность. Здесь необходимо уточнить, что информативность признака – это не только количество информации в признаке о принадлежности к данному классу, но и количество информации в классе о том, что при нем наблюдается данный признак, т.е. это взаимная информация класса и признака.
Если бы классы были тождественны друг другу, т.е. это был бы один класс, то его вклад в сходство/различие двух признаков был бы просто равен соответствующему данному классу слагаемому корреляции этих признаков, т.е. просто произведению информативностей.
Но поскольку это в общем случае это могут быть различные классы, то, очевидно, необходимо умножить произведение информативностей на коэффициент корреляции между классами.
Таким образом, будем считать, что любые два класса (j,l) вносят определенный вклад в сходство/различие двух признаков (i,k), определяемый сходством/различием этих классов и количеством информации о принадлежности к ним, которое содержится в данных признаках
 |
(3. 52) |
Вывод формулы (3.52) обобщенного коэффициента корреляции Пирсона для двух признаков совершенно аналогичен выводу формулы (3.47), поэтому он здесь не приводится. Формулы для всех входящих в (3.52) величин приведены выше в предыдущем разделе.
Так же, как и в режиме содержательного сравнения классов, в данном режиме сила связи выражается в процентах от максимальной теоретически–возможной силы связи. На диаграммах отображается 16 наиболее значимых связей, рассчитанных согласно этой формуле, причем знак связи изображается цветом (красный +, синий –), а величина – толщиной линии. Имеется возможность вывода диаграмм только с положительными или только с отрицательными связями.
Математическая модель позволяет получить обобщенные инвертированные когнитивные диаграммы для любых двух заданных признаков, для пар наиболее похожих и непохожих признаков, для всех их возможных сочетаний, а также инвертированные диаграммы Мерлина.
Необходимо отметить, что понятия, соответствующие по смыслу терминам "обобщенная инвертированная когнитивная диаграмма" и "инвертированная диаграмма Мерлина" не упоминаются даже в фундаментальных руководствах по когнитивной психологии и впервые предложены в [92]. Эти диаграммы представляют собой частный случай обобщенных когнитивных диаграмм признаков, формируемых в соответствии с предложенной математической моделью при следующих ограничениях:
1. Признак сравнивается сам с собой.
2. Выбрана фильтрация левого и правого вектора по уровням системной организации классов (аналог уровней Мерлина для свойств).
3. Левый вектор отображается с фильтрацией по одному уровню системной организации классов, а правый – по другому.
Обоснование сопоставимости частных критериев Iij
Применение этого метода корректно, если можно сравнивать суммарное количество информации о переходе АОУ в различные состояния, рассчитанное в соответствии с выражением (3.44), т.е. если они сопоставимы друг с другом.
Будем считать, что величины сопоставимы тогда и только тогда, когда одновременно выполняются следующие три условия:
1. Сопоставимы индивидуальные количества информации, содержащейся в признаках о принадлежности к классам.
2. Сопоставимы величины, рассчитанные для одного объекта и разных классов.
3. Сопоставимы величины, рассчитанные для разных объектов и разных классов.
Очевидно, для решения всех этих вопросов необходимо дать точное и полное определение самого термина "сопоставимость".
Считается, что величины сопоставимы, если существует некоторая количественная шкала для измерения этих величин.
Таким образом, в нашем случае сопоставимость обеспечивается, если на шкале определены направление и единица измерения, а также есть абсолютный минимум (ноль) или максимум.
Докажем теоремы о выполнении условий сопоставимости для упрощенной и полной информационных моделей объектов и классов распознавания. Для этого рассмотрим вышеперечисленные необходимые и достаточные условия сопоставимости для упрощенной и полной информационных моделей.
Теорема-1: Индивидуальные количества информации, содержащейся в признаках объекта о принадлежности к классам, сопоставимы между собой.
В упрощенной информационной модели класса и информационной модели объекта принято, что все признаки имеют одинаковый вес, который равен 1, если признак есть у класса, и 0, если его нет. Уже одним этим обеспечивается сопоставимость индивидуальных количеств информации в упрощенной модели.
В полной модели количество информации рассчитывается в соответствии с модифицированной формулой Харкевича (3.28). Таким образом, в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов распознавания. Следовательно, для полной информационной модели сопоставимость индивидуальных количеств информации также обеспечивается, так как для них применима шкала отношений.
Это означает, что индивидуальные количества информации можно суммировать и ввести интегральный критерий как аддитивную меру от индивидуальных количеств информации, что и требовалось доказать.
Теорема-2: Величины суммарной информации, рассчитанные для одного объекта и разных классов, сопоставимы друг с другом.
В упрощенной информационной модели вариант расстояния Хэмминга Hj, в котором учитываются только совпадения единиц (т.е. существующих признаков), для кодовых слов объекта и класса равно:
 |
(3. 53) |
где


Li – кодовое слово (профиль, массив–локатор) объекта.

Пусть длина кодового слова (количество признаков) равна А. Длины кодовых слов объекта и классов одинаковы. Признаки могут принимать значения {0,1}. Тогда из этих условий и выражения (3.53) следует:
 |
(3. 54) |
Но выражение (3.54) является математическим определением шкалы отношений, что означает полную сопоставимость предложенной меры сходства для упрощенной информационной модели одного объекта и многих классов. Для обобщенной информационной модели этот вывод сохраняет силу, т.к. в этой модели информация в соответствии с выражением (3.28) измеряется в единицах измерения – битах, определенных на шкале измерения информации, и на этой шкале имеется 0 и теоретический максимум, определяемый в соответствии с выражением Хартли. В полной информационной модели мера сходства объекта с классом

Очевидно, величина
 |
(3. 55) |
что и доказывает применимость шкалы отношений и полную сопоставимость меры сходства для полной информационной модели одного объекта и многих классов.
Это значит, что можно сравнивать меры сходства данного объекта с каждым из классов и ранжировать классы в порядке убывания сходства с данным объектом , что и требовалось доказать.
Теорема-3: Величины суммарной информации, рассчитанные для разных объектов и разных классов, а также классов и классов, признаков и признаков, взаимно-сопоставимы.
Очевидно, величина

 |
(3. 56) |
что и доказывает применимость шкалы отношений и полную сопоставимость мер сходства для полной информационной модели многих объектов и многих классов.
Это значит, что можно сравнивать меры сходства различных объектов с классами распознавания и делать выводы о том, что одни объекты распознаются лучше, а другие хуже на данном наборе классов и признаков, что и т.д.
Аналогичные рассуждения верны и для сравнения векторов классов друг с другом, а также векторов признаков друг с другом, что позволяет применить модели кластерно-конструктивного анализа и алгоритмы построения семантических сетей, что и требовалось доказать.
Теорема-4: Неметрический интегральный критерий сходства, основанный на модифицированной формуле А.Харкевича и обобщенной лемме Неймана-Пирсона, аддитивен.
Рассмотрим информационные модели распознаваемого объекта и классов распознавания, т.е. модели, основанные на теории кодирования – декодирования и расстоянии Хэмминга (кодовое расстояние) в качестве критерия сходства. Эта модель является упрощенной, но достаточно адекватной для решения вопроса об аддитивности меры сходства объектов и классов.
Информационная модель распознаваемого объекта представляет собой двоичное слово, каждый разряд которого соответствует определенному признаку. Если признак есть у распознаваемого объекта, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам распознаваемого объекта, называется его кодовым словом.
Упрощенная информационная модель класса распознавания есть двоичное слово, каждый разряд которого соответствует определенному признаку. Соответствие между двоичными разрядами и признаками для классов то же самое, что и для распознаваемых объектов. Если признак есть у класса, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам класса, называется его кодовым словом.
Такая модель класса является упрощенной, так как в ней принято, что все признаки имеют одинаковый вес равный 1, если он есть у класса, и 0, если его нет, тогда как в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов.
Таким образом, в упрощенной информационной модели различные классы распознавания отличаются друг от друга только наборами признаков, которые им соответствуют.
При использовании этих упрощенных моделей задача распознавания объекта сводится к задаче декодирования, т.е. кодовые слова объектов рассматриваются как искаженные зашумленным каналом связи кодовые слова классов. Распознавание состоит в том, что по кодовому слову объекта определяется наиболее близкое ему в определенном смысле кодовое слово класса. При этом естественной и наиболее простой мерой сходства между распознаваемым объектом и классом является расстояние Хэмминга между их кодовыми словами, т.е. количество разрядов, которыми они отличаются друг от друга.
Рассмотрим теперь вопрос об аддитивности количества информации как частного критерия в интегральном критерии.
Известно [148], что существует всего два варианта формирования интегрального критерия из частных критериев: аддитивный и мультипликативный, поэтому задача сводится к выбору одного из этих вариантов.
Рассмотрим эти варианты. Пусть кодовое слово объекта состоит из N разрядов. Тогда добавление еще одного разряда, отображающего имеющийся (1) или отсутствующий (0) признак, приведет к различным результатам в случаях, когда интегральный критерий есть аддитивная и мультипликативная функция индивидуальных количеств информации в признаках (таблица 19).
|
Таблица 19 – СРАВНЕНИЕ АДДИТИВНОГО И МУЛЬТИПЛИКАТИВНОГО ВАРИАНТОВ ИНТЕГРАЛЬНОГО КРИТЕРИЯ |
||
|
Дополнительный признак |
Аддитивная функция:  |
Мультипликативная функция:  |
|
Есть (1) |
 |
 |
|
Нет (0) |
 |
 |
Здесь предполагается, что: I=f(n), f(1)=1, f(0)=0.
Итак, если функция аддитивна – добавление еще одного разряда увеличит количество информации в кодовом слове на 1 бит, если соответствующий признак есть, и не изменит этого количества, если его нет; если же функция мультипликативна, – то это не изменит количества информации в кодовом слове, если соответствующий признак есть, и сделает его равным нулю, если его нет.
Очевидно, мультипликативный вариант интегрального критерия не соответствует классическим представлениям о природе информации, тогда как аддитивный вариант полностью им соответствует: требование аддитивности самой меры информации было впервые обосновано Хартли в 1928 году, подтверждено Шенноном в 1948 году, и в последующем развитии теории информации никогда не подвергалось сомнению. На аддитивности частных критериев, имеющих смысл количества информации, основана известная лемма Неймана-Пирсона [148, стр.152].
Пусть по выборке (т.е. совокупности факторов) {x=x1,…, xN} требуется отдать предпочтение одной из конкурирующих гипотез (H1 или H0), т.е. определить в какое будущее состояние перейдет объект управления, если известны распределения наблюдений при каждой из них (по данным обучающей выборки), т.е. р(х|H0) и р(х|H1). Как обработать предпочтительную гипотезу? Из теории информации известно, что никакая обработка не может увеличить количества информации, содержащегося в выборке {х}. Следовательно, выборке {х} нужно поставить в соответствие число, содержащее всю полезную информацию, т.е. обработать выборку без потерь. Возникает мысль о у том, чтобы вычислить индивидуальные количества информации в выборке {х} о каждой из гипотез и сравнить их:
 |
Какой из гипотез отдать предпочтение, зависит теперь от величины Di и от того, какой порог сравнения мы назначим. Оптимальность данной статистической процедуры специально доказывается в математической статистике, – именно к этому сводится содержание фундаментальной Леммы Неймана-Пирсона, которая утверждает, что предпочтение следует отдавать той статистической гипотезе, о которой в выборке содержится больше информации.
Согласно описанной выше процедуре предполагается, что объект управления перейдет в то будущее состояние, о переходе в которое в системе факторов содержится большее суммарное количество информации.
Таким образом, аддитивность интегрального критерия, основанного на частных критериях, имеющих смысл количества информации, можно считать обоснованной, что и требовалось доказать.
