Устойчивость модели к неполноте информации
Подготовим распознаваемую выборку, состоящую из идентифицируемых слов с отсутствующими буквами.
Для этого выполним следующую последовательность шагов:
Шаг 1.
Сбросим распознаваемую выборку в режиме "F7 Сервис – Генерация (сброс) баз данных – Распознаваемые анкеты" (рисунок 129):
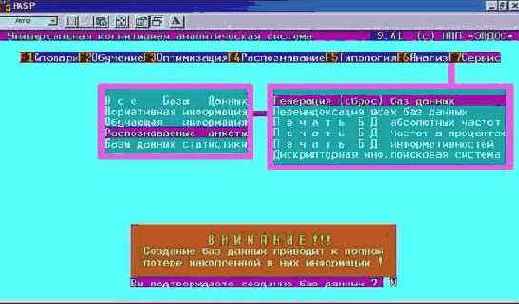 | |
| Рисунок 129. Режим "Сброс распознаваемой выборки" системы "Эйдос" |
Шаг 2. Скопируем, например, первую анкету из обучающей выборки в распознаваемую, используя возможности режима "F2 Обучение – Ввод-корректировка обучающей выборки" (рисунок 124);
Шаг 3. Выберем режим "F4 Распознавание – Ввод-корректировка распознаваемой выборки" (рисунок 130):
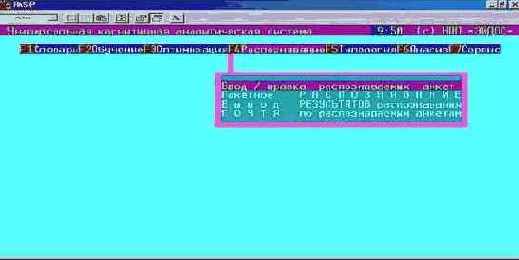 | |
| Рисунок 130. Выбор режима "Ввод-корректировка распознаваемой выборки" системы "Эйдос" |
Выбор режима осуществляется нажатием клавиши Enter.
Шаг 4. Перейдем в правое окно, в котором задаются коды признаков, нажав клавишу "TAB".
Шаг 5. Удаляем последний код признака и дублируем анкету, нажав клавишу "F5 Дублирование анкеты".
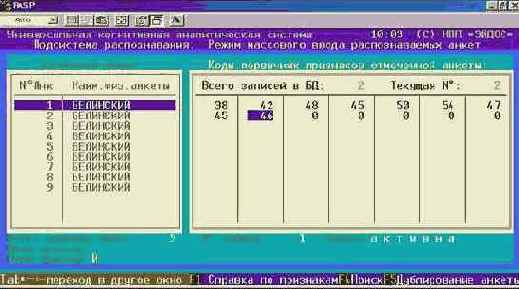
Повторяем шаги 4 и 5 до тех пор, пока в описании слова останется одна буква. В результате получится видеограмма, представленная на рисунке 131.
Студенты при выполнении этого этапа работы могут взять несколько анкет на выбор. При этом набор анкет должен отличаться у разных студентов.
Обучающая выборка в этом случае будет иметь вид, представленный на таблице 72:
Таблица 72 – ВАРИАНТЫ КОДИРОВАНИЯ ОБЪЕКТА ОБУЧАЮЩЕЙ ВЫБОРКИ, ОТЛИЧАЮЩИЕСЯ СТЕПЕНЬЮ НЕПОЛНОТЫ ИНФОРМАЦИИ
| № | Класс | Коды признаков | |||||||||||||||||||||||||||||
| 1 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | 45 | 46 | |||||||||||||||||||||
| 2 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | 45 | ||||||||||||||||||||||
| 3 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | |||||||||||||||||||||||
| 4 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | ||||||||||||||||||||||||
| 5 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | |||||||||||||||||||||||||
| 6 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | ||||||||||||||||||||||||||
| 7 | БЕЛИНСКИЙ | 38 | 42 | 48 | |||||||||||||||||||||||||||
| 8 | БЕЛИНСКИЙ | 38 | 42 | ||||||||||||||||||||||||||||
| 9 | БЕЛИНСКИЙ | 38 |
Жирным шрифтом выделены символы, коды которых есть в анкете.
 |
|
Рисунок 131. Выполнение режима "Ввод-корректировка распознаваемой выборки" системы "Эйдос" |
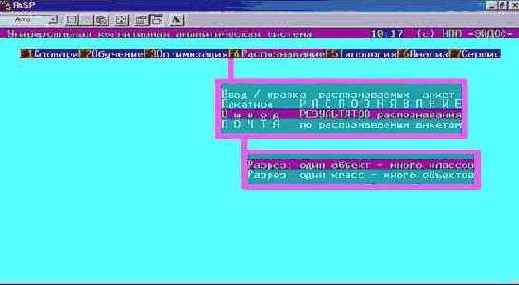
Шаг 7. Затем выберем и выполним режим "F4 Распознавание – Вывод результатов распознавания" (рисунок 132):
 |
|
Рисунок 132. Выбор режима "Вывод результатов распознавания" системы "Эйдос" |
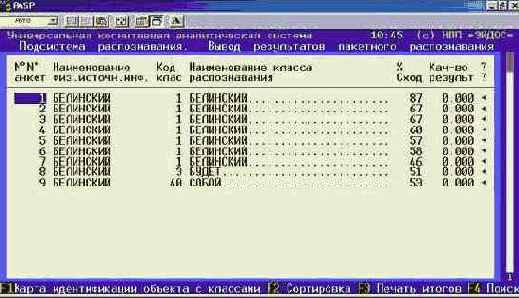 |
|
Рисунок 133. Обобщенная форма по результатам выполнения режима "Вывод результатов распознавания" системы "Эйдос" |
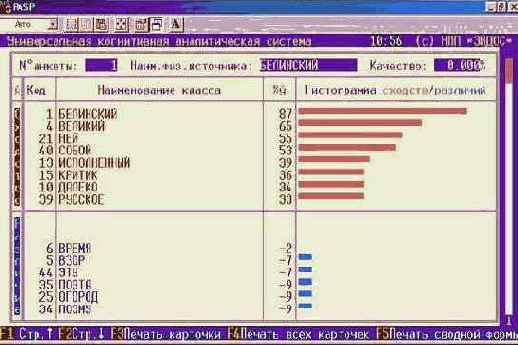
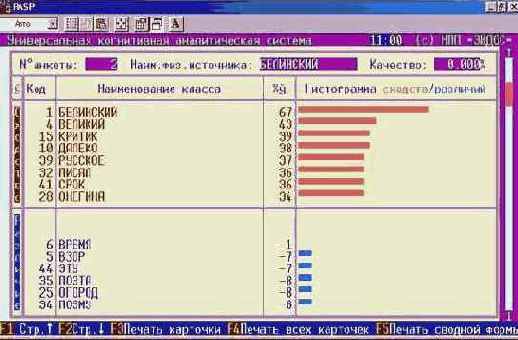
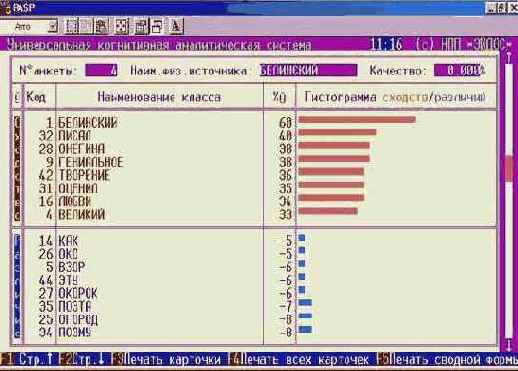
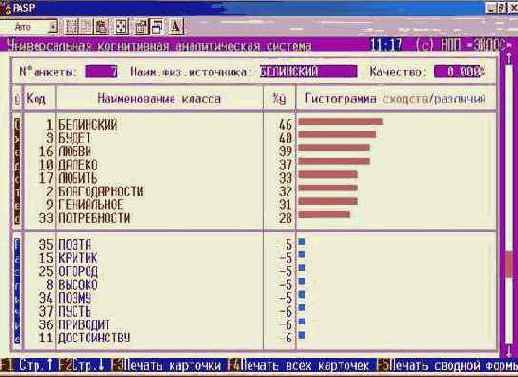
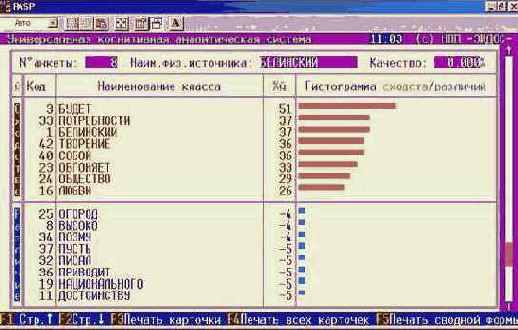
Шаг 9. Нажав клавишу "F1 Карта идентификации объекта с классами" получим более подробные результаты идентификации, представленные в карточках распознавания на рисунке 134:
 |
 |
 |
 |
 |
|
Рисунок 134. Идентификация в условиях неполноты информации в системе "Эйдос" |
