Алгоритмы обработки одномерных символьных массивов
Одномерные символьные масивы
- это массивы, составленные из определенной последовательности символов, которые образуют тексты. Основными операциями, выполняемыми над текстами, являются операции по определению слов, выделению слова с максимальной длиной, удаление и перестановка слов,сортировка по алфавиту идр.
Для простоты будем считать, что символьный массив представляет одну строку произвольного текста, слово - любую последовательность подряд идущих символов не содержащую пробела. Пробел - это специальный символ, используемый для отделения слов, он не может располагаться перед первым словом. Учитывая все эти допущения можно предложить для решения задачи определения количества слов использовать подсчет количества элементов массива, равных пробелу минус 1.
Рассмотрим алгоритмическое решение распространенной задачи определения в массиве символов слова с максимальной длиной.
Пусть исходный массив А содержит N символов. Для определения слова с максимальной длиной будем использовать сравнение длины текущего слова М с длиной предыдущего слова МАХ. Длина слова определяется как содержащееся в нем количество символов. Для того, чтобы вывести слово с максимальной длиной, необходимо запомнить номер элемента S, с которого начинается это слово.
Алгоритм поиска в символьном массиве слова с максимальной длиной приведен на рис. 32, а его таблица трассировки для массива (Дул теплый ветер)- в таблице 8.
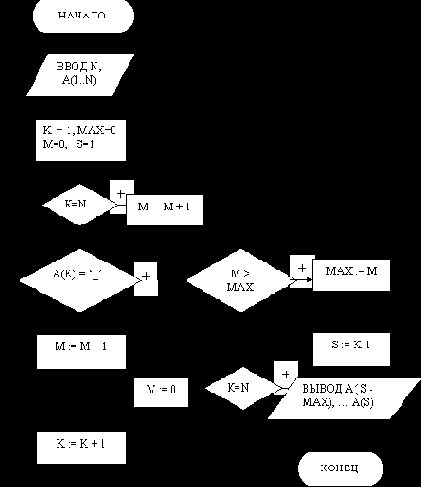 |
Рис. 32.Алгоритм поиска в символьном массиве слова с максимальной длиной
Таблица 8. Таблица трассировки алгоритма поиска слова с максимальной длиной при N= 16 в тексте : "Дул теплый ветер"
| К | А(К) | К=N | А(К)=" " | М>МАХ | М | МАХ | S | НОВОЕ S | |||||||||
| 1 | Д | Нет | Нет | 1 | 0 | 1 | 1 | ||||||||||
| 2 | у | Нет | Нет | 2 | |||||||||||||
| 3 | л | Нет | Нет | 3 | |||||||||||||
| 4 | " " | Нет | ДА | Да | 0 | 3 | 3 | 4 | |||||||||
| 5 | т | Нет | Нет | 1 | |||||||||||||
| 6 | е | Нет | Нет | 2 | |||||||||||||
| 7 | п | Нет | Нет | 3 | |||||||||||||
| 8 | л | Нет | Нет | 4 | |||||||||||||
| 9 | ы | Нет | Нет | 5 | |||||||||||||
| 10 | й | Нет | Нет | 6 | |||||||||||||
| 11 | " " | Нет | ДА | Да | 0 | 6 | 10 | 11 | |||||||||
| 12 | в | Нет | Нет | 1 | |||||||||||||
| 13 | е | Нет | Нет | 2 | |||||||||||||
| 14 | т | Нет | Нет | 3 | |||||||||||||
| 15 | е | Нет | Нет | 4 | |||||||||||||
| 16 | р | Да | Нет | Нет | 5 |
/p>
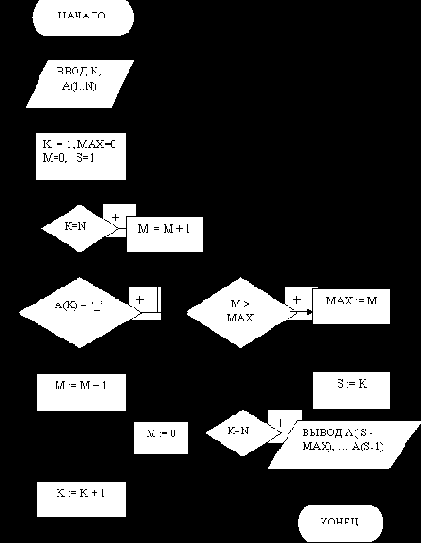
Рассмотрите результат, приведенный в таблице 8, для конкретного входного символьного массива "Дул теплый ветер" без последнего столбца. Однако, после выполнения приведенного на рис. 32 алгоритма для предложения "Дул теплый ветер" будет выведено слово из 7 символов, начинающихся с пробела :" теплый". Значит, формулу определения номера символа S = K-1 , с которого начинается слово с максимальной длиной, следует изменить на S = K. При этом надо будет изменить содержание блока вывода результата: вместо A( S -MАХ), … A(S) следует использовать A( S -MАХ), … A(S-1). Таким образом, таблица трассировки показала наличие ошибок в алгоритме, изображенном на рис. 32. После внесения изменений этот алгоритм будет работать правильно (см. модернизированный алгоритм поиска в символьном массиве слова с максимальной длиной на рис. 33).
 |