Проблемы построения ИС
Самой первой проблемой является проблема проектирования. Нельзя начинать техническую разработку, не имея тщательно проработанного проекта. Если начинать с решения наиболее очевидных задач, не обращая внимания на потенциально существующие, то такая система будет непрерывно находиться в стадии разработки и переделки.
Первой стадией проектирования должен быть анализ требований корпорации. Для этого на основе экспертных запросов необходимо выявить все актуальные и потенциальные потребности корпорации, которые должны удовлетворяться проектируемой информационной системой, понять какие потоки данных существуют внутри корпорации, оценить объемы информации, которые должны поддерживаться и обрабатываться информационной системой. Эта стадия, как правило, носит неформальный характер, хотя, конечно, очень важно сохранить полученную информацию, поскольку она должна входить в документацию системы. Существуют CASE-средства верхнего уровня, которые помещают полученные данные в общий репозиторий проекта и позволяют использовать их на следующих стадиях проектирования.
Следующая стадия проектирования - выработка концептуальной схемы базы данных, которая будет лежать в основе информационной системы. Сначала придется выбрать систему нотаций, в которой будет представляться концептуальная схема (правильнее было бы сказать - выбрать концептуальную модель). Таких нотаций существует великое множество, и хотя практически все они диаграммные (в духе ER-модели), они отличаются одна от другой. Заметим, что даже в случае использования некоторых CASE-средств вам все равно предлагается на выбор несколько нотаций. Заметим, что хотя, на взгляд автора, выбор нотации - дело вкуса (по возможностям они почти эквивалентны), это ответственный выбор. Концептуальное представление базы данных должно сохраняться как часть документации информационной системы на все время ее существования и будет использоваться при ее сопровождении и развитии.
Далее, с большой вероятностью в основе информационной системы будет лежать реляционная база данных.
Несмотря на очевидную привлекательность объектно-ориентированных (ObjectStore, Objectivity, O2, Jasmin и т.д.) и объектно-реляционных (Illustra, UniSQL) СУБД, в ближайшие годы придется работать с хорошо отлаженными, развитыми, сопровождаемыми системами, поддерживающими стандарт SQL-92 (например, Oracle, Informix, CA-OpenIngres, Sybase, DB2). Просто потому, что должно пройти время, чтобы эти системы устоялись, обрели необходимую надежность, стали бы опираться на какие-либо стандарты и т.д.
Поэтому, с большой вероятностью, на следующей стадии проектирования понадобится на основе имеющейся концептуальной схемы произвести набор определений схемы реляционной базы данных в терминах языка SQL. К сожалению, несмотря на наличие стандарта языка, на этой стадии иногда невозможно не учитывать специфику сервера баз данных, который будет использоваться. Вы спросите, почему "к сожалению"? Да потому, что на самом деле мы еще не дошли до той стадии, когда конкретные особенности сервера действительно необходимо учитывать. В принципе, на данной стадии мы все еще находимся на уровне абстрактной реляционной модели. Но все дело в том, что когда производители серверов баз данных провозглашают соответствие своих серверных продуктов стандарту языка SQL-92, то в основном они понимают соответствие так называемому "ядру" стандарта. К сожалению, ядро стандарта не включает средств определения схемы базы данных. Поэтому диалекты SQL, реализуемые разными производителями, различаются в деталях соответствующих языковых средств. По этой причине необходимо внимательно изучить "целевой" диалект SQL, если трансляция концептуальной схемы в реляционную производится вручную (например, на основе методологии, предлагаемой компанией Oracle), или указать название используемого серверного продукта, если используется продукто-независимое CASE-средство (например, Silverrun).
На этой же стадии необходимо решить, какие таблицы будут реально хранимыми, а какие - представляемыми (view).
После того, как выработана общая реляционная схема базы данных, необходимо определиться с архитектурой системы. В частности, очень важно решить, какой будет база данных - централизованной или распределенной (другими словами будет ли использоваться только один сервер баз данных или их будет несколько). Если принимается решение о распределенном характере базы данных, то необходимо произвести соответствующую декомпозицию набора определений схемы базы данных. (Заметим, что, вообще говоря, принятие решения об архитектуре системы возможно и до выработки общей реляционной схемы базы данных. Тогда декомпозиция производится на уровне концептуальной схемы, а затем для каждой отдельной части концептуальной схемы создается реляционная схема в терминах языка SQL.)
Наиболее простым случаем декомпозиции является тот, когда образующиеся разделы базы данных логически автономны. В терминах концептуальной схемы это означает, что между разделенными сущностями отсутствуют прямые или транзитивные (через другие сущности) связи. В терминах реляционной схемы: ни в одном разделе не присутствует таблица, ссылающаяся на таблицу, которая располагается в другом разделе (рисунки 1.3 и 1.4). Если требование логической автономности компонентов распределенной базы данных выполнено, то дальнейшее проектирование можно производить для каждого компонента независимо.

Рис. 1.3. Распределенная база данных с логически автономными разделами
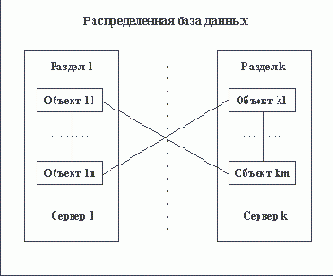
Рис. 1.4. Распределенная база данных с логически неавтономными разделами
В чем, собственно, состоит проблема распределенных баз данных с логически неавтономными разделами? Все дело в том, что любая связь, отраженная в схеме базы данных (между сущностями в концептуальной модели или между таблицами в реляционной модели), соответствует ограничению целостности, которое впоследствии должно сохраняться в базе данных и поддерживаться СУБД. В настоящее время общая технология организации распределенных баз данных (даже однородных, основанных на SQL) отсутствует. Некоторые производители решают эту задачу путем расширения функций сервера, и тогда, вообще говоря, в базе данных могут присутствовать ограничения целостности, содержащие ссылки на таблицы, которые располагаются в других разделах.
В других системах задача управления распределенной базой данных решается на стороне клиента. В этом случае сервер, управляющий разделом распределенной базы данных ничего не знает о существовании других разделов и не может поддерживать ограничения целостности, включающие ссылки на объекты "чужих" разделов. Тогда целостность распределенной базы данных приходится поддерживать за счет написания явного кода в приложении. Другими словами, если невозможно произвести декомпозицию схемы общей базы данных в набор схем логически независимых разделов, то снова необходимо учитывать возможности используемого серверного продукта и двигаться дальше соответствующим образом.
Следующая стадия проектирования состоит в дополнении реляционных схем разделов распределенной базы данных определениями общих ограничений целостности, триггеров и хранимых процедур. На каждом из этих компонентов схемы следует остановиться отдельно. Начнем с общих ограничений целостности.
Язык SQL-92 позволяет определить ограничения целостности, относящиеся к общему состоянию базы данных и включающие ссылки на произвольное число таблиц. Семантика таких ограничений целостности может быть существенно шире, чем ограничения, задаваемые связями
