Data Mining на службе у таможни
17.10.2002
Развитие корпоративных баз данных в сжатом во времени виде повторяет общую историю развития ИТ. Корпорации начинают с небольших разрозненных баз, работающих под управлением скромных СУБД, постепенно переходя к централизованным базам на основе полномасштабных СУБД. Однако, накопив огромное количество данных, корпорации осознают, что само по себе обладание данными еще не дает им преимуществ. В статье излагается опыт использования технологий «поиска знаний» применительно к задачам, стоящим перед Государственным таможенным комитетом РФ.
Для того чтобы база данных работала эффективно, необходимо как минимум обеспечить экспертам оперативный доступ к информации, который не требовал бы от них навыков программирования и позволял представлять данные в привычном для экспертов виде. За последние пять лет мы реализовали несколько систем OLAP. К сожалению, в рамках технологий OLAP основная тяжесть анализа по-прежнему ложится на плечи человека. Более того, встречаются задачи, в которых либо объем информации слишком велик, либо решение зависит от множества факторов, что делает невозможным анализ данных вручную. На сегодняшний день многие поставщики программного обеспечения, в том числе Oracle, выпустили ряд продуктов, реализующих алгоритмы Data Mining и позволяющих автоматизировать процесс анализа данных.
с анализом ставок таможенных пошлин
Анализ электронных копий ГТД, в совокупности с анализом ставок таможенных пошлин и агрегированных данных статистики внешней торговли Евросоюза и Российской Федерации, проведенный средствами технологии Data Mining позволил определить корреляции между товарными группами, сделать обоснованные предположения по определению «товаров риска» и «товаров прикрытия», а также дать оценку возможных потерь таможенных платежей.
Таким образом, проведенное исследование показало, что технологии Data Mining могут успешно применяться для выявления скрытых тенденций во внешнеторговой деятельности. При этом следует отметить, что в отличие от других методов поддержки принятия решений технологии Data Mining обладают гораздо более высокой степенью интеллектуальности и хорошей масштабируемостью, позволяя в значительной степени автоматизировать анализ данных.
Андрей Майоров () — сотрудник компании «РДТех».
Oracle Data Mining
Компания Oracle выпустила два программных продукта, реализующих алгоритмы поиска знаний: Oracle Data Mining Suite (Darwin) и Oracle 9i Data Mining (server option). Первый доступен уже в течение нескольких лет и, хотя степень его интегрированности с другими продуктами Oracle низка, предлагает достаточно мощный набор алгоритмов (классификационные и регрессионные деревья, нейронная сеть, кластеризация по ближайшим соседям). К безусловным достоинствам Darwin надо отнести наличие ряда утилит для подготовки входных данных, позволяющих объединять наборы, рандомизировать и трансформировать данные в соответствии с заданной функцией. Чрезвычайно полезной является наличие утилит предварительного анализа, в том числе построение гистограмм. Darwin интегрирован с MS Excel, что расширяет его возможности особенно в плане графики. Наличие графического пользовательского интерфейса делает доступным весь цикл работы с моделью для аналитиков, не имеющих достаточного опыта в программировании.
Oracle 9i Data Mining — сравнительно новый продукт и его первая версия включала лишь два алгоритма: простейший классификатор (Naive Bayes) по методу Байеса и поиск ассоциативных правил. Оба алгоритма хорошо известны и, несмотря на свою простоту, в ряде областей применений зарекомендовали себя как чрезвычайно успешные. Отличительной чертой Oracle 9i Data Mining является его интегрированность с Oracle Server причем не только при доступе к данным — алгоритмы реализованы как пакеты, хранимые в базе. Программный интерфейс реализован на Java, что делает взаимодействие с продуктом более гибким. Однако, в отличие от Darwin, графический пользовательский интерфейс полностью отсутствует. В последнем выпуске (Oracle Server 9.2) опция Data Mining была обогащена новыми алгоритмами. В частности, был добавлен адаптивный Байесов классификатор и O-кластеризация.
Сравнение статистических данных ЕС и РФ
Имея два источника сведений о внешнеэкономической деятельности, можно попытаться сопоставить данные, одновременно анализируя всю совокупность ТНВЭД. Если сравнивать данные по группам товаров, то разница значений еще не может привести к каким-либо выводам, поскольку существуют естественные причины отклонения в данных ЕС и РФ:
ошибки ввода; округление веса до целого значения в тоннах (в базе EC); округление стоимости до целого значения в долл. (в базе РФ); несоответствие даты декларирования товара в РФ и стране-контрагенте (данные агрегированы до месяца, однако даты декларирования могут относиться к разным месяцам); разница курсов валют в момент вывоза и ввоза товара; различия в классификации ТНВЭД и ГС в РФ и EC, в результате чего некоторые товары могут быть учтены по разным группам ТНВЭД/ГС в статистике РФ и EC.
В то же время не могут быть непосредственно использованы оригинальные переменные: вес нетто и стоимость, так как различные группы товаров характеризуются различной ценой и характерными объемами перемещаемых товаров. Кроме того, цель анализа — не выявление расхождений между данными ЕС и РФ, а определение величины риска, связанной с данной группой товаров, т. е. величины относительного несоответствия между данными. В связи с этим в качестве основных переменных выбраны относительные разности по стоимости и весу нетто, определяемые как:
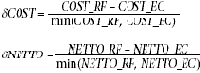
COST_RF, COST_ES — статистическая стоимость товаров данной группы по статистике РФ и EC соответственно, NETTO_RF, NETTO_ES — аналогичные показатели для веса нетто. Нормировка на минимальные значения обоснована, поскольку неизвестно истинное значение стоимости и веса, кроме того, это приближает распределение значений переменных к известному статистическому распределению (хотелось бы иметь распределение, хотя бы отдаленно напоминающее гауссово). Сравнить данные по всем группам можно, построив гистограмму для описанных переменных, показывающую, как часто встречается то или иное значение переменной (ось Х — значения переменной, Y — количество случаев, когда переменная принимала данное значение).
Oracle Darwin имеет утилиту для построения одно и двухмерных гистограмм данных, которой мы и воспользовались. На рис. 1 показаны нормированные распределения для относительного отклонения стоимости и веса для экспорта и импорта.
 |
Рис. 1. Распределение относительных отклонений стоимости и веса между данными ЕС и РФ |
 |
Рис. 2. Совместные распределения относительных отклонений стоимости веса. Слева — экспорт, справа — импорт |
Оказывается, этому есть простое объяснение.
Вес груза декларируется верно, но фальсифицируется наименование товара — в декларации указывается близкий по характеристикам товар с меньшей ставкой таможенной пошлины. В результате для определенных групп товаров наблюдается существенный прирост импорта по сравнению с данными ЕС. Эта схема ухода от таможенных платежей хорошо известна таможенным органам как «товар прикрытия».
Даже использование таких простейших способов анализа данных как гистограмма позволило выделить наличие определенных тенденций и оценить масштаб искажения данных. Более того, уже на этом этапе возможно сформулировать определенные критерии для отбора групп товаров наиболее подверженных фальсификациям. В то же время распределения, приведенные на рис. 1 и 2, показывают, что сделанный нами выбор переменных был не очень удачным с точки зрения алгоритмов кластеризации — плотность данных довольно монотонно падает от центра к краям распределения. Чтобы воспользоваться алгоритмами кластеризации нам пришлось переопределить переменные, введя следующие переменные:
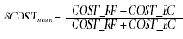
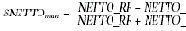
Основное отличие новых переменных — ограниченный диапазон принимаемых значений:

Распределение, аналогичное приведенному на рис. 2, в новых переменных показано на рис. 3.
 |
Рис. 3. Совместное распределение относительных отклонений по стоимости (dCOSTmean) и весу (dNETTOmean) для случаев импорта |
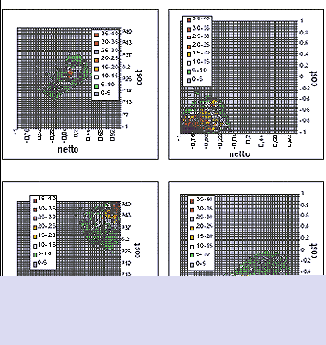 |
Рис. 4. Кластеры совместного распределения относительных отклонений по стоимости (dCOSTmean) и весу (dNETTOmean) для случаев импорта |
 |
Рис. 5. Найденный с помощью Darwin Match кластер в переменных netto-cost |
Товар риска — товар прикрытия
Как правило, при «прикрытии» одного товара другим в рамках одного груза (и одной таможенной декларации) действительно перевозятся оба товара, однако доля «дорогого» занижается. Этот факт и может быть использован для выявления подобных пар. При отборе потенциальных пар «товар риска» — «товар прикрытия» мы использовали следующие критерии:

Первый критерий основной и означает, что один из товаров вероятнее всего сопутствует другому. Выбор условных вероятностей, вместо, например, коэффициента корреляций, обуславливается их большей чувствительностью. Коэффициент корреляции близок к единице лишь в случае, если оба товара все время ввозятся одновременно. Мы же налагаем гораздо более слабое условие: лишь один из товаров постоянно сопутствует другому, поскольку один из товаров может ввозиться в больших объемах без всякого сопровождения. Использованный критерий известен в литературе как алгоритм ассоциированных правил и, в частности, реализован в Oracle Data Mining 9i. К сожалению, использованные данные находились в базе Oracle Server 8, в связи с чем пришлось использовать собственную реализацию алгоритма.
Впрочем, высокая корреляция одного из товаров с другим еще не означает, что товар обязательно прикрывается другим: множество людей ежедневно покупают одновременно хлеб и молоко без всякого злого умысла. И при импорте товаров существуют случаи естественной корреляции между товарами. Чтобы очистить отобранные пары от таких случаев, мы наложили дополнительные условия: прикрытие должно быть экономически выгодно, а сравнительный анализ статистических данных должен подтверждать факт прикрытия.
Анализ предоставленных ГТК данных выявил значительное количество пар, удовлетворяющих выбранным критериям. Безусловно, не все они являются парами «товар риска — товар прикрытия». Эффективность реализованного алгоритма может быть подтверждена только в ходе дополнительных проверок на таможенных постах. Однако следует отметить, что число подобных пар существенно меньше, нежели общее число товарных групп, и их список вполне может быть использован как рекомендация по более тщательному досмотру определенных грузов.
В качестве примера приведем одну пару товаров: шины для легковых автомобилей и протекторные заготовки для их восстановления. В приведены данные по импорту этих двух групп товаров за 2000 год, а именно число случаев ввоза каждого из товаров, число случаев совместного ввоза и вычисленные по этим данным коэффициенты корреляции и вероятности.
Как видно из , на протяжении всего 2000 года вероятность ввоза шин вместе с заготовками очень высока — в среднем 95% за год. Случаев ввоза только заготовок практически не было. При этом коэффициент корреляции не столь велик, поскольку достаточно большой объем импорта шин не сопровождается заготовками. Сам по себе факт корреляции между этими группами товаров достаточно естественен, однако ставка таможенной пошлины в 2000 году на заготовки была в 5 раз ниже, нежели для шин — 5% и 25% соответственно. Более того, сравнительный анализ данных РФ и ЕС показал, что импорт заготовок согласно российским данным почти в 200 раз выше, чем по данным ЕС, а импорт шин ниже в 3,5 раза, если сравнивать объемы импорта по весу. При этом суммарный вес импорта по этим двум группам совпадает по данным РФ и ЕС с точностью до 20% ().
Похожая картина наблюдается и в стоимостном выражении. Стоимость ввезенных в РФ заготовок в 30 раз выше, чем вывезенных из стран ЕС, в то время как шин, если судить по декларированной стоимости, ввезено в 2,7 раза меньше вывезенного количества. Т. е., судя по приведенным данным, с большой вероятностью протекторные заготовки в 2000 году использовались рядом импортеров как прикрытие для ввозимых шин. Потери государства на таможенных пошлинах составили предположительно около 7 млн. долл.
Отметим, что анализ был проведен на полном объеме грузовых таможенных деклараций за 2000 год, что составляет более 2 млн. деклараций с общим числом товаров порядка 5 млн. Ясно, что анализ такого количества данных не может быть выполнен ни вручную, ни с помощью ряда других технологий поддержки решений. И хотя, безусловно, невозможно полностью заменить аналитика автоматизированной системой, применение методов поиска знаний позволяет отсеять огромное количество данных, не представляющих, интереса и сократить объем анализируемой информации до уровня адекватного человеческому восприятию.
Товары риска
Одна из основных задач, стоящих перед таможенными органами, состоит в выявлении преднамеренного искажения грузовых таможенных деклараций. В силу ограниченных ресурсов полная проверка всех перемещаемых через границу грузов невозможна. Однако ГТК собирает подробные базы данных по грузовым таможенным декларациям. Анализ этих данных может быть использован для выявления тенденций во внешней торговле РФ и по группам товаров, наиболее подверженных фальсификации при прохождении таможни — «товарам риска». Имея данные о таких товарах, таможенные посты могли бы более тщательно проверять прохождение соответствующих грузов и уменьшить потери от фальсификации таможенных документов.
Одной из особенностей задачи стало отсутствие «тренировочного» набора данных — данных, для которых было бы априори известно, какие из них являются попыткой фальсификации грузовой таможенной декларации, а какие представляют собой добросовестно задекларированные товары. Это существенно ограничивало круг алгоритмов, которые можно было использовать: например, популярные методы типа классификаторы Байеса, деревья решений, нейронные сети и т.п. требуют предварительного обучения на тренировочном наборе данных. В нашем распоряжении оставались лишь алгоритмы кластеризации и ассоциативных правил.
Предметом анализа является база данных Европейского Союза по внешней торговле с Россией и база грузовых таможенных деклараций (ГТД) Единой Автоматизированной Информационной Системы ГТК России. ГТД может оформляться одновременно на несколько перемещаемых вместе товаров. База данных ЕС содержит только агрегированную до уровня одного месяца и восьми знаков товарную номенклатуру внешнеэкономической деятельности. ТНВЭД — это десятизначный классификатор товаров, используемый таможенными органами. В 2000 году он содержал более 12 тыс. групп товаров, а также информацию об объеме и стоимости перемещаемых товаров. В российскую же декларацию заносится детальная информация о каждом грузе. В своем анализе мы использовали лишь часть информации, содержащейся в декларации: направление перемещения (импорт/экспорт); объем (вес); стоимость в долл.; дата оформления.
