Где может размещаться блок в кэшпамяти?
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod (число блоков в кэш-памяти)
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod (число множеств в кэш-памяти)
Далее, блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
Как найти блок находящийся в кэшпамяти?
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тегу так называемого бита достоверности (valid bit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путем деления адреса, поступающего из процессора, на три части: поле смещения используется для выбора байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.
Какой блок кэшпамяти должен быть замещен при промахе?
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным. На рисунке 3.22 показаны различия в долях промахов при использовании алгоритма замещения LRU и случайного алгоритма.
| Ассоциативность: | 2-канальная | 4-канальная | 8-канальная |
| Размер кэш-памяти | LRU Random | LRU Random | LRU Random |
| 16 KB | 5.18% 5.69% | 4.67% 5.29% | 4.39% 4.96% |
| 64 KB | 1.88% 2.01% | 1.54% 1.66% | 1.39% 1.53% |
| 256 KB | 1.15% 1.17% | 1.13% 1.13% | 1.12% 1.12% |
это небольшой сервер, замыкающий снизу
AlphaServer 400 4/166- это небольшой сервер, замыкающий снизу семейство машин AlphaServer. AlphaServer 400 поддерживают три операционные системы: Digital UNIX, Windows NT и OpenVMS. Система включает в себя стандартную шину PCI, обеспечивающую широкий выбор периферийных устройств. Компьютер AlphaServer 400 4/166 призван заменить на рынке такой популярный продукт Digital, как миникомпьютер
MicroVAX 3100. Имея те же преимущества, что и MicroVAX, современная система
AlphaServer 400 имеет и дополнительные достоинства: открытость архитектуры, использование стандартных компонент (например, шина PCI) и, главное, мощный микропроцессор Alpha. AlphaServer 400 имеет многие преимущества больших систем, такие, как высокая надежность и расширенные средства обеспечения безопасности и управления. Этот сервер работает на частоте 166 МГц и является одним из самым "быстрых" серверов в своем классе. Это подтверждают результаты тестов: AlphaServer 400 4/166 выполняет 100 транзакций в секунду по тесту TPC-A и имеет показатели 107.7 и 134.8 единиц, соответственно, на тестах SPECint92 и SPECfp92.
AlphaServer 400 может служить в качестве сервера локальной сети небольших и средних по размеру организаций. Следует отметить, что Digital предлагает недорогие способы увеличения производительности этих систем путем замены процессоров на самые современные модели по мере их появления. AlphaServer 400 имеет до 192 Мб оперативной памяти, может использовать более 8 Гб внутренней и до 44 Гб - общей дисковой памяти. Особенность этого компьютера - средства удаленной диагностики, позволяющие выполнять программы тестирования и конфигурации системы удаленным способом по телефонным линиям связи.
к уровню серверов рабочих групп.
Недорогой сервер AlphaServer 1000 4/233 относится к уровню серверов рабочих групп. Данный компьютер может быть поставлен с заранее установленным программным обеспечением доступа к сети Internet. AlphaServer 1000, имеющий 512 Мб памяти ECC, более 14 Гб внутренней памяти "горячего" переключения, шину PCI/EISA, две шины PCI и 7 портов расширения EISA, дисковод для гибкого диска, CD-ROM. Следует также учитывать возможность выбора одной их трех операционных систем: Windows NT, Digital UNIX и OpenVMS.
Системы AlphaServer 2000 близки по
Системы AlphaServer 2000 близки по своему уровню к компьютерам AlphaServer 2100. Они также представляют собой недорогие SMP-серверы, базирующиеся на шинах PCI/EISA, и поддерживают операционные системы OpenVMS, Digital UNIX и Windows NT. Данные компьютеры могут использоваться в качестве серверов высокопроизводительных коммерческих приложений и баз данных, а также серверов крупных локальных сетей. AlphaServer 2000 4/233 (микропроцессор DECchip 21064A) имеет частоту 233 МГц с кэш-памятью 1 Мб; AlphaServer 2000 4/275 (микропроцессор DECchip 21064A) - 275 МГц с кэш-памятью 4 Мб. Каждая система может иметь конфигурацию с 1-2 процессорами, поддерживает до 1 Гб оперативной памяти и до 32 Гб внутренней дисковой памяти. Пропускная способность системной шины равна 667 Мб/сек, а высокопроизводительная подсистема ввода/вывода PCI имеет пиковую пропускную способность 132 Мб/сек. Шина ввода/вывода EISA (33 Мб/сек) поддерживает широкий спектр стандартных устройств.
Системы AlphaServer 2100 представляют собой
Системы AlphaServer 2100 представляют собой недорогие SMP-серверы, базирующиеся на шинах PCI/EISA. Они поддерживают операционные системы OpenVMS, Digital UNIX и Windows NT. Данные компьютеры могут использоваться в качестве серверов высокопроизводительных коммерческих приложений и баз данных, а также серверов крупных локальных сетей. AlphaServer 2100 4/233 (микропроцессор DECchip 21064A) имеет частоту 233 МГц с кэш-памятью 1 Мб; AlphaServer 2100 4/275 (микропроцессор DECchip 21064A) - 275 МГц с кэш-памятью 4 Мб; AlphaServer 2100 5/250 (микропроцессор DECchip 21164) - 250 МГц с кэш-памятью 4 Мб. Каждая система может иметь конфигурацию с 1-4 процессорами, поддерживает до 2 Гб оперативной памяти и до 64 Гб внутренней дисковой памяти. Пропускная способность системной шины равна 667 Мб/сек, а высокопроизводительная подсистема ввода/вывода PCI имеет пиковую пропускную способность 132 Мб/сек. Шина ввода/вывода EISA (33 Мб/сек) поддерживает широкий спектр стандартных устройств.
это одна из наиболее высокопроизводительных
Компьютер AlphaServer 8200 - это одна из наиболее высокопроизводительных систем для офиса в современной промышленности. Его конфигурация может включать до шести микропроцессоров DECchip 21164. Имея все преимущества 64-разрядной Alpha-архитектуры, до 6 Гб памяти и до 108 слотов PCI, данный сервер обеспечивает возможности роста даже для самых крупных и сложных приложений. AlphaServer 8200 поддерживает операционные системы OpenVMS, Digital UNIX и Windows NT. Небольшие предприятия и крупные подразделения могут использовать производительность, мощность и надежность этого сервера для приложений, которые прежде функционировали на системах масштаба крупного предприятия. Большие базы данных, процессы моделирования, системы поддержки принятия решений - вот несколько примеров приложений, которые легко поддерживаются AlphaServer 8200.
это реализация сервера на базе
AlphaServer 8400 - это реализация сервера на базе микропроцессора DECchip 21164 (частота - от 300 МГц) высокопроизводительного сервера масштаба предприятия. AlphaServer 8400 поддерживает до 12 процессоров, 14 Гб памяти и скорость ввода/вывода свыше 1,2 Гб/сек. Сбалансированная конструкция и быстрые процессоры позволяют обеспечивать обработку более 3000 транзакций в секунду. На AlphaServer 8400 могут функционировать операционные системы OpenVMS, Digital UNIX и Windows NT. Для защиты инвестиций своих пользователей Digital предлагает линию модернизации таких продуктов, как DEC 7000 и VAX 7000. Этот upgrade до уровня AlphaServer 8400 может быть выполнен в течение нескольких часов, что обеспечивает высокую производительность сегодня и средства роста в будущем. Архитектура AlphaServer 8400 разработана с учетом возможности использования будущих поколений микропроцессора Alpha. AlphaServer 8400 оснащается высокоскоростными шинами ввода/вывода PCI (144 слота на 12 физически различных шинах). Данный компьютер имеет относительно низкую стоимость в своем классе и может использоваться в качестве сервера крупной распределенной базы данных, обеспечивая при этом надежность и готовность на уровне более дорогих мэйнфреймов.
Альтернативные протоколы
Имеются две методики поддержания описанной выше когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором. Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи мы можем потребовать, чтобы процессор имел достоверную (valid) копию данных в своей кэш-памяти прежде, чем выполнять в нее запись. Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго (мы вскоре увидим, как принять решение, кто из них выиграет) и вызывает аннулирование его копии. Другой процессор для завершения своей операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах. Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками:
-
Несколько последовательных операций записи в одно и то же слово, не перемежающихся операциями чтения, требуют нескольких операций трансляции при использовании протокола записи с обновлением, но только одной начальной операции аннулирования при использовании протокола записи с аннулированием.
При наличии многословных блоков в кэш-памяти каждое слово, записываемое в блок кэша, требует трансляции при использовании протокола записи с обновлением, в то время как только первая запись в любое слово блока нуждается в генерации операции аннулирования при использовании протокола записи с аннулированием. Протокол записи с аннулированием работает на уровне блоков кэш-памяти, в то время как протокол записи с обновлением должен работать на уровне отдельных слов (или байтов, если выполняется запись байта).
Задержка между записью слова в одном процессоре и чтением записанного значения другим процессором обычно меньше при использовании схемы записи с обновлением, поскольку записанные данные немедленно транслируются в процессор, выполняющий чтение (предполагается, что этот процессор имеет копию данных). Для сравнения, при использовании протокола записи с аннулированием в процессоре, выполняющим чтение, сначала произойдет аннулирование его копии, затем будет производиться чтение данных и его приостановка до тех пор, пока обновленная копия блока не станет доступной и не вернется в процессор.
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи. При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
Аппаратное прогнозирование направления переходов и снижение потерь на организацию переходов
Буфера прогнозирования условных переходов
Простейшей схемой динамического прогнозирования направления условных переходов является буфер прогнозирования условных переходов (branch-prediction buffer) или таблица "истории" условных переходов (branch history table). Буфер прогнозирования условных переходов представляет собой небольшую память, адресуемую с помощью младших разрядов адреса команды перехода. Каждая ячейка этой памяти содержит один бит, который говорит о том, был ли предыдущий переход выполняемым или нет. Это простейший вид такого рода буфера. В нем отсутствуют теги, и он оказывается полезным только для сокращения задержки перехода в случае, если эта задержка больше, чем время, необходимое для вычисления значения целевого адреса перехода. В действительности мы не знаем, является ли прогноз корректным (этот бит в соответствующую ячейку буфера могла установить совсем другая команда перехода, которая имела то же самое значение младших разрядов адреса). Но это не имеет значения. Прогноз - это только предположение, которое рассматривается как корректное, и выборка команд начинается по прогнозируемому направлению. Если же предположение окажется неверным, бит прогноза инвертируется. Конечно такой буфер можно рассматривать как кэш-память, каждое обращение к которой является попаданием, и производительность буфера зависит от того, насколько часто прогноз применялся и насколько он оказался точным.
Однако простая однобитовая схема прогноза имеет недостаточную производительность. Рассмотрим, например, команду условного перехода в цикле, которая являлась выполняемым переходом последовательно девять раз подряд, а затем однажды невыполняемым. Направление перехода будет неправильно предсказываться при первой и при последней итерации цикла. Неправильный прогноз последней итерации цикла неизбежен, поскольку бит прогноза будет говорить, что переход "выполняемый" (переход был девять раз подряд выполняемым). Неправильный прогноз на первой итерации происходит из-за того, что бит прогноза инвертируется при предыдущем выполнении последней итерации цикла, поскольку в этой итерации переход был невыполняемым. Таким образом, точность прогноза для перехода, который выполнялся в 90% случаев, составила только 80% (2 некорректных прогноза и 8 корректных). В общем случае, для команд условного перехода, используемых для организации циклов, переход является выполняемым много раз подряд, а затем один раз оказывается невыполняемым. Поэтому однобитовая схема прогнозирования будет неправильно предсказывать направление перехода дважды (при первой и при последней итерации).
Для исправления этого положения часто используется схема двухбитового прогноза. В двухбитовой схеме прогноз должен быть сделан неверно дважды, прежде чем он изменится на противоположное значение. На рисунке 3.13 представлена диаграмма состояний двухбитовой схемы прогнозирования направления перехода.
Двухбитовая схема прогнозирования в действительности является частным случаем более общей схемы, которая в каждой строке буфера прогнозирования имеет n-битовый счетчик. Этот счетчик может принимать значения от 0 до 2n - 1. Тогда схема прогноза будет следующей:
Если значение счетчика больше или равно 2n-1 (точка на середине интервала), то переход прогнозируется как выполняемый. Если направление перехода предсказано правильно, к значению счетчика добавляется единица (если только оно не достигло максимальной величины); если прогноз был неверным, из значения счетчика вычитается единица. Если значение счетчика меньше, чем 2n-1, то переход прогнозируется как невыполняемый. Если направление перехода предсказано правильно, из значения счетчика вычитается единица (если только не достигнуто значение 0); если прогноз был неверным, к значению счетчика добавляется единица.Исследования n-битовых схем прогнозирования показали, что двухбитовая схема работает почти также хорошо, и поэтому в большинстве систем применяются двухбитовые схемы прогноза, а не n-битовые.
Аппаратные средства поддержки большой степени распараллеливания
Методы, подобные разворачиванию циклов и планированию трасс, могут использоваться для увеличения степени доступного параллелизма, когда поведение условных переходов достаточно предсказуемо во время компиляции. Если же поведение переходов не известно, одной техники компиляторов может оказаться не достаточно для выявления большей степени параллелизма уровня команд. Существуют два метода, которые могут помочь преодолеть подобные ограничения. Первый метод заключается в расширении набора команд условными или предикатными командами. Такие команды могут использоваться для ликвидации условных переходов и помогают компилятору перемещать команды через точки условных переходов. Условные команды увеличивают степень параллелизма уровня команд, но имеют существенные ограничения. Для использования большей степени параллелизма разработчики исследовали идею, которая называется "выполнением по предположению" (speculation), и позволяет выполнить команду еще до того, как процессор узнает, что она должна выполняться (т.е. этот метод позволяет избежать приостановок конвейера, связанных с зависимостями по управлению).
Архитектура машин с длинным командным словом
Архитектура машин с очень длинным командным словом (VLIW - Very Long Instruction Word) позволяет сократить объем оборудования, требуемого для реализации параллельной выдачи нескольких команд, и потенциально чем большее количество команд выдается параллельно, тем больше эта экономия. Например, суперскалярная машина, обеспечивающая параллельную выдачу двух команд, требует параллельного анализа двух кодов операций, шести полей номеров регистров, а также того, чтобы динамически анализировалась возможность выдачи одной или двух команд и выполнялось распределение этих команд по функциональным устройствам. Хотя требования по объему аппаратуры для параллельной выдачи двух команд остаются достаточно умеренными, и можно даже увеличить степень распараллеливания до четырех (что применяется в современных микропроцессорах), дальнейшее увеличение количества выдаваемых параллельно для выполнения команд приводит к нарастанию сложности реализации из-за необходимости определения порядка следования команд и существующих между ними зависимостей.
Архитектура VLIW базируется на множестве независимых функциональных устройств. Вместо того, чтобы пытаться параллельно выдавать в эти устройства независимые команды, в таких машинах несколько операций упаковываются в одну очень длинную команду. При этом ответственность за выбор параллельно выдаваемых для выполнения операций полностью ложится на компилятор, а аппаратные средства, необходимые для реализации суперскалярной обработки, просто отсутствуют.
WLIW-команда может включать, например, две целочисленные операции, две операции с плавающей точкой, две операции обращения к памяти и операцию перехода. Такая команда будет иметь набор полей для каждого функционального устройства, возможно от 16 до 24 бит на устройство, что приводит к команде длиною от 112 до 168 бит.
Рассмотрим работу цикла инкрементирования элементов вектора на подобного рода машине в предположении, что одновременно могут выдаваться две операции обращения к памяти, две операции с плавающей точкой и одна целочисленная операция либо одна команда перехода. На рисунке 3.19 показан код для реализации этого цикла. Цикл был развернут семь раз, что позволило устранить все возможные приостановки конвейера. Один проход по циклу осуществляется за 9 тактов и вырабатывает 7 результатов. Таким образом, на вычисление каждого результата расходуется 1.28 такта (в нашем примере для суперскалярной машины на вычисление каждого результата расходовалось 2.4 такта).
| Обращение к памяти 1 |
Обращение к памяти 2 |
Операция ПТ 1 | Операция ПТ 2 | Целочисленная операция/переход |
| LD F0,0(R1) LD F10,-16(R1) LD F18,-32(R1) LD F26,-48(R1) SD 0(R1),F4 SD -16(R1),F12 SD -32(R1),F20 SD 0(R1),F28 |
LD F6,-8(R1) LD F14,-24(R1) LD F22,-40(R1) SD -8(R1),F8 SD -24(R1),F16 SD -40(R1),F24 |
ADDD F4,F0,F2 ADDD F12,F10,F2 ADDD F20,F18,F2 ADDD F28,F26,F2 |
ADDD F8,F6,F2 ADDD F16,F14,F2 ADDD F24,F22,F2 |
SUBI R1,R1,#48 BNEZ R1,Loop |
Архитектура матричного коммутатора
Архитектура коммутатора реализована с помощью аппаратной сети, которая осуществляет индивидуальные соединения типа точка-точка процессора с процессором, процессора с основной памятью и процессора с магистралью данных ввода/вывода. Эта сеть работает совместно с разделяемой адресной шиной. Такой сбалансированный подход позволяет использовать лучшие свойства каждого из этих методов организации соединений.
Разделяемая адресная шина упрощает реализацию наблюдения (snooping) за адресами, которое необходимо для аппаратной поддержки когерентности памяти. Адресные транзакции конвейеризованы, выполняются асинхронно (расщеплено) по отношению к пересылкам данных и требуют относительно небольшой полосы пропускания, гарантируя, что этот ресурс никогда войдет в состояние насыщения.
Организация пересылок данных требует больше внимания, поскольку уровень трафика и время занятости ресурсов физического межсоединения здесь существенно выше, чем это требуется для пересылки адресной информации. Операция пересылки адреса представляет собой одиночную пересылку, в то время как операция пересылки данных должна удовлетворять требованию многобайтной пересылки в соответствии с размером строки кэша ЦП. При реализации отдельных магистралей данных появляется ряд дополнительных возможностей, которые обеспечивают:
максимальную скорость передачи данных посредством соединений точка-точка на более высоких тактовых частотах; параллельную пересылку данных посредством организации выделенного пути для каждого соединения; разделение адресных транзакций и транзакций данных. Поэтому архитектуру PowerScale компании Bull можно назвать многопотоковой аппаратной архитектурой (multi-threaded hardware architecture) с возможностями параллельных операций.На Рисунок 4.3 показаны основные режимы и операции, выполняемые матричным коммутатором.
Архитектура NonStop
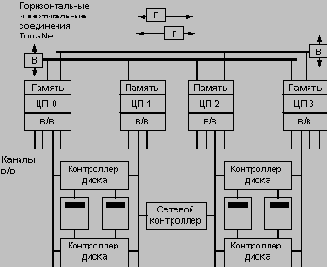
Все аппаратные компоненты систем NonStop построены на основе принципа "быстрого проявления неисправности" (fail fast disign), в соответствии с которым каждый компонент должен либо функционировать правильно, либо немедленно останавливаться. В более ранних системах Tandem реализация этого принципа широко опиралась на использование методов проверки четности, избыточного кодирования или проверки допустимости состояния при выполнении каждой логической функции. Современные конструкции для обнаружения ошибок в сложной логике полагаются главным образом на методы дублирования и сравнения. Все системы, имеющие ЦП на базе микропроцессоров, для гарантии целостности данных и быстрого обнаружения неисправностей выполняют сравнение выходов дублированных и взаимно синхронизированных микропроцессоров. В системах NonStop ответственность за восстановление после обнаружения неисправности в аппаратуре возлагается на программное обеспечение.
Операционная система NonStop Kernel систем NonStop непрерывно развивалась и к настоящему времени превратилась из патентованной фирменной операционной системы в систему, которая обеспечивает полностью открытые интерфейсы, построенные на основе промышленных стандартов. Для поддержки устойчивости критически важных процессов в NonStop Kernel реализованы низкоуровневые механизмы контрольных точек, а также специальный слой программных средств, на котором строится как патентованная среда Guardian, так и открытая среда Posix-XPG/4. NonStop Kernel базируется на механизмах передачи сообщений и обеспечивает средства прозрачного масштабирования системы в пределах 16-процессорного узла, 224-процессорного домена или 4080-процессорной (локальной или глобальной) сети TorusNet.
Архитектура POWER
Архитектура POWER во многих отношениях представляет собой традиционную RISC-архитектуру. Она придерживается наиболее важных отличительных особенностей RISC: фиксированной длины команд, архитектуры регистр-регистр, простых способов адресации, простых (не требующих интерпретации) команд, большого регистрового файла и трехоперандного (неразрушительного) формата команд. Однако архитектура POWER имеет также несколько дополнительных свойств, которые отличают ее от других RISC-архитектур.
Во-первых, набор команд был основан на идее суперскалярной обработки. В базовой архитектуре команды распределяются по трем независимым исполнительным устройствам: устройству переходов, устройству с фиксированной точкой и устройству с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, где они могут выполняться одновременно и заканчиваться не в порядке поступления. Для увеличения уровня параллелизма, который может быть достигнут на практике, архитектура набора команд определяет для каждого из устройств независимый набор регистров. Это минимизирует связи и синхронизацию, требуемые между устройствами, позволяя тем самым исполнительным устройствам настраиваться на динамическую смесь команд. Любая связь по данным, требующаяся между устройствами, должна анализироваться компилятором, который может ее эффективно спланировать. Следует отметить, что это только концептуальная модель. Любой конкретный процессор с архитектурой POWER может рассматривать любое из концептуальных устройств как множество исполнительных устройств для поддержки дополнительного параллелизма команд. Но существование модели приводит к согласованной разработке набора команд, который естественно поддерживает степень параллелизма по крайней мере равную трем.
Во-вторых, архитектура POWER расширена несколькими "смешанными" командами для сокращения времен выполнения. Возможно единственным недостатком технологии RISC по сравнению с CISC, является то, что иногда она использует большее количество команд для выполнения одного и того же задания. Было обнаружено, что во многих случаях увеличения размера кода можно избежать путем небольшого расширения набора команд, которое вовсе не означает возврат к сложным командам, подобным командам CISC. Например, значительная часть увеличения программного кода была обнаружена в кодах пролога и эпилога, связанных с сохранением и восстановлением регистров во время вызова процедуры. Чтобы устранить этот фактор IBM ввела команды "групповой загрузки и записи", которые обеспечивают пересылку нескольких регистров в/из памяти с помощью единственной команды. Соглашения о связях, используемые компиляторами POWER, рассматривают задачи планирования, разделяемые библиотеки и динамическое связывание как простой, единый механизм. Это было сделано с помощью косвенной адресации посредством таблицы содержания (TOC - Table Of Contents), которая модифицируется во время загрузки. Команды групповой загрузки и записи были важным элементом этих соглашений о связях.
Другим примером смешанных команд является возможность модификации базового регистра вновь вычисленным эффективным адресом при выполнении операций загрузки или записи (аналог автоинкрементной адресации). Эти команды устраняют необходимость выполнения дополнительных команд сложения, которые в противном случае потребовались бы для инкрементирования индекса при обращениях к массивам. Хотя это смешанная операция, она не мешает работе традиционного RISC-конвейера, поскольку модифицированный адрес уже вычислен и порт записи регистрового файла во время ожидания операции с памятью свободен.
Архитектура POWER обеспечивает также несколько других способов сокращения времени выполнения команд такие как: обширный набор команд для манипуляции битовыми полями, смешанные команды умножения-сложения с плавающей точкой, установку регистра условий в качестве побочного эффекта нормального выполнения команды и команды загрузки и записи строк (которые работают с произвольно выровненными строками байтов).
Третьим фактором, который отличает архитектуру POWER от многих других RISC-архитектур, является отсутствие механизма "задержанных переходов". Обычно этот механизм обеспечивает выполнение команды, следующей за командой условного перехода, перед выполнением самого перехода. Этот механизм эффективно работал в ранних RISC-машинах для заполнения "пузыря", появляющегося при оценке условий для выбора направления перехода и выборки нового потока команд. Однако в более продвинутых, суперскалярных машинах, этот механизм может оказаться неэффективным, поскольку один такт задержки команды перехода может привести к появлению нескольких "пузырей", которые не могут быть покрыты с помощью одного архитектурного слота задержки. Почти все такие машины, чтобы устранить влияние этих "пузырей", вынуждены вводить дополнительное оборудование (например, кэш-память адресов переходов). В таких машинах механизм задержанных переходов становится не только мало эффективным, но и привносит значительную сложность в логику обработки последовательности команд. Вместо этого архитектура переходов POWER была организована для поддержки методики "предварительного просмотра условных переходов" (branch-lockahead) и методики "свертывания переходов" (branch-folding).
Методика реализации условных переходов, используемая в архитектуре POWER, является четвертым уникальным свойством по сравнению с другими RISC-процессорами. Архитектура POWER определяет расширенные свойства регистра условий. Проблема архитектур с традиционным регистром условий заключается в том, что установка битов условий как побочного эффекта выполнения команды, ставит серьезные ограничения на возможность компилятора изменить порядок следования команд. Кроме того, регистр условий представляет собой единственный архитектурный ресурс, создающий серьезное узкое горло в машине, которая параллельно выполняет несколько команд или выполняет команды не в порядке их появления в программе. Некоторые RISC-архитектуры обходят эту проблему путем полного исключения из своего состава регистра условий и требуют установки кода условий с помощью команд сравнения в универсальный регистр, либо путем включения операции сравнения в саму команду перехода. Последний подход потенциально перегружает конвейер команд при выполнении перехода. Поэтому архитектура POWER вместо того, чтобы исправлять проблемы, связанные с традиционным подходом к регистру условий, предлагает: a) наличие специального бита в коде операции каждой команды, что делает модификацию регистра условий дополнительной возможностью, и тем самым восстанавливает способность компилятора реорганизовать код, и b) несколько (восемь) регистров условий для того, чтобы обойти проблему единственного ресурса и обеспечить большее число имен регистра условий так, что компилятор может разместить и распределить ресурсы регистра условий, как он это делает для универсальных регистров.
Другой причиной выбора модели расширенного регистра условий является то, что она согласуется с организацией машины в виде независимых исполнительных устройств. Концептуально регистр условий является локальным по отношению к устройству переходов. Следовательно, для оценки направления выполнения условного перехода не обязательно обращаться к универсальному регистровому файлу (который является локальным для устройства с фиксированной точкой). Для той степени, с которой компилятор может заранее спланировать модификацию кода условия (и/или загрузить заранее регистры адреса перехода), аппаратура может заранее просмотреть и свернуть условные переходы, выделяя их из потока команд. Это позволяет освободить в конвейере временной слот (такт) выдачи команды, обычно занятый командой перехода, и дает возможность диспетчеру команд создавать непрерывный линейный поток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась на рынке в 1990 году. С тех пор компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд.
По данным IBM процессор POWER требует менее одного такта для выполнении одной команды по сравнению с примерно 1.25 такта у процессора Motorola 68040, 1.45 такта у процессора SPARC, 1.8 такта у Intel i486DX и 1.8 такта Hewlett-Packard PA-RISC. Тактовая частота архитектурного ряда в зависимости от модели меняется от 25 МГц до 62 МГц.
Процессоры POWER работают на частоте 33, 41.6, 45, 50 и 62.5 МГЦ. Архитектура POWER включает раздельную кэш-память команд и данных (за исключением рабочих станций и серверов рабочих групп начального уровня, которые имеют однокристальную реализацию процессора POWER и общую кэш-память команд и данных), 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки и таким образом хорошо подходит для приложений с интенсивными вычислениями, типичными для технической среды, хотя текущая стратегия RS/6000 нацелена как на коммерческие, так и на технические приложения. RS/6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/Powerserver 580. Это меньше, чем уровень моделей Hewlett-Packard 9000 Series 800 G/H/I-50, которые достигают уровня 150 SPECfp92.
Для реализации быстрой обработки ввода/вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 Мбайт/сек. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных микросхем (устройств):
Блок кэш-памяти команд (ICU) - 32 Кбайт, имеет два порта с 128-битовыми шинами; Блок устройств целочисленной арифметики (FXU) - содержит два целочисленных конвейера и два блока регистров общего назначения (по 32 32-битовых регистра). Выполняет все целочисленные и логические операции, а также все операции обращения к памяти; Блок устройств плавающей точки (FPU) - содержит два конвейера для выполнения операций с плавающей точкой двойной точности, а также 54 64-битовых регистра плавающей точки; Четыре блока кэш-памяти данных - максимальный объем кэш-памяти первого уровня составляет 256 Кбайт. Каждый блок имеет два порта. Устройство реализует также ряд функций обнаружения и коррекции ошибок при взаимодействии с системой памяти; Блок управления памятью (MMU).Набор кристаллов POWER2 содержит порядка 23 миллионов транзисторов на площади 1217 квадратных мм и изготовлен по технологии КМОП с проектными нормами 0.45 микрон. Рассеиваемая мощность на частоте 66.5 МГц составляет 65 Вт.
Производительность процессора POWER2 по сравнению с POWER значительно повышена: при тактовой частоте 71.5 МГц она достигает 131 SPECint92 и 274 SPECfp92.
Архитектура процессоров PowerPC
Основой архитектуры PowerPC является многокристальная архитектура POWER, которая была разработана прежде всего в расчете на однопроцессорную реализацию процессора. При разработке PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) в архитектуре POWER было сделано несколько изменений в следующих направлениях:
упрощение архитектуры с целью ее приспособления для реализации дешевых однокристальных процессоров; устранение команд, которые могут стать препятствием повышения тактовой частоты; устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд; добавление свойств, необходимых для поддержки симметричной мультипроцессорной обработки; добавление новых свойств, считающихся необходимыми для будущих прикладных программ; обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально нарушить двоичную совместимость с приложениями, написанными для архитектуры POWER, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программных средств. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
Микропроцессор PowerPC поддерживает мультипроцессорную обработку, в частности, модель тесно связанных вычислений в разделяемой (общей) памяти. Работа тесно связанных процессоров предполагает использование разными процессорами одной общей памяти и одной операционной системы, которая управляет всеми процессорами и аппаратурой системы. Процессоры должны конкурировать за разделяемые ресурсы.
В симметричной мультипроцессорной системе все процессоры считаются функционально эквивалентными и могут выполнять операции ввода/вывода и другие вычисления. Возможности управления подобной системой с разделяемой памятью реализованы в ОС AIX 4.1.
Разработанное Bull семейство Escala обеспечивает масштабируемость и высокую готовность систем, центральным местом которых является симметричная мультипроцессорная архитектура, названная PowerScale, позволяющая производить постепенную модернизацию и объединять в системе от 1 до 8 процессоров.
Архитектура систем Integrity
Основной задачей компании Tandem при разработке систем семейства Integrity было обеспечение устойчивости к одиночным отказам аппаратуры при соблюдении 100% переносимости стандартных UNIX-приложений. Для маскирования аппаратных неисправностей в системах Integrity используется тройное модульное резервирование (TMR - triple-modular redundancy) в процессоре, кэш-памяти и основной памяти (см. Рисунок 4.7).
Архитектура систем Integrity
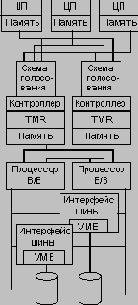
В системах Integrity реализация платы основного процессора не требует сложной логики самоконтроля. Однако это делает ее конструкцию отличной от конструкции процессорной платы систем NonStop, хотя в обеих используются одни и те же микропроцессоры. Архитектура новых систем объединяет требования базовой конструкции Integrity при сохранении совместимости с требованиями систем NonStop.
Архитектура систем NonStop
На Рисунок 4.6 показана базовая архитектура систем NonStop. Эта архитектура предполагает объединение двух или более ЦП при помощи дублированной высокоскоростной межпроцессорной шины. Каждый процессор имеет один или несколько каналов в/в, соединяющих его с двухпортовыми дисковыми контроллерами и коммуникационными адаптерами. В действительности в первых пяти поколениях систем NonStop (NonStop I, II, TXP, CLX и VLX) было реализовано только по одному каналу в/в на процессор, а пара разделяемых шин обеспечивала объединение до 16 процессоров. В более поздних системах NonStop Cyclone и Himalaya K10000/20000 для увеличения пропускной способности системы межсоединений была применена сегментация межпроцессорной шины на базе четырехпроцессорных секций. Секции могут объединяться с помощью оптоволоконных линий связи в узлы (до четырех секций в узле). Системы NonStop II, TXP, VLX и Cyclone поддерживают также возможность построения оптоволоконного кольца, которое позволяет объединить между собой до 14 узлов и обеспечивает быстрый обмен данными внутри домена, состоящего из 224 процессоров. В системе Cyclone к каждому процессору могут подсоединяться несколько каналов в/в, причем каждые четыре канала управляются своей парой контроллеров прямого доступа к памяти.
Архитектура системной шины UPA
Высокая производительность процессора UltraSPARC-1 потребовала создания гибкой масштабируемой архитектуры межсоединений, позволяющей достаточно просто строить системы для широкого круга приложений от небольших настольных систем индивидуального пользования до больших многопроцессорных серверов масштаба предприятия. Новая архитектура UPA (Ultra Port Architecture) определяет возможности построения целого семейства тесно связанных многопроцессорных систем с общей памятью.
UPA представляет собой спецификацию, описывающую логические и физические интерфейсы порта системной шины и требования, накладываемые на организацию межсоединений. К этим портам подключаются все устройства системы. Спецификация UPA включает также описание поведения системного контроллера и интерфейс ввода/вывода системы межсоединений.
UPA может поддерживать большое количество (рисунок 5.9) системных портов (32, 64, 128 и т.д.) и включает четыре типа интерфейса. Интерфейс главного устройства выдает в систему межсоединений транзакции чтения/записи по физическому адресу, используя распределенный протокол арбитража для управления адресной шиной. Главное устройство UPA (например, процессорный модуль UltraSPARC-1) может включать физически адресуемую когерентную кэш-память, на размер которой в общем случае не накладывается никаких ограничений. Интерфейс подчиненного устройства получает транзакции чтения/записи от главных устройств UPA, поддерживая строгое упорядочивание транзакций одного и того же класса главных устройств, а также транзакций, направляемых по одному и тому же адресу устройства. Порт UPA может быть только подчиненным, например, для подключения графического буфера кадров. Двумя другими дополнительными интерфейсами порта UPA являются источник прерывания и обработчик прерываний. Источники прерывания UPA генерируют пакеты прерывания, направляемые к обработчикам прерываний UPA.
Архитектура системы команд Классификация процессоров (CISC и RISC)
Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление этого термина. В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера как систему памяти, структуру системной шины, организацию ввода/вывода и т.п.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются
архитектуры CISC и RISC. Основоположником CISC-архитектуры можно считать
компанию IBM с ее базовой архитектурой /360, ядро которой используется с 1964
года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC-I и RISC-II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. В 1981 году Дж. Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки.
Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC-архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные. Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983-1984 гг.) обозначился также прорыв в технологии изготовления сверхбольших интегральных схем. Простота архитектуры и ее эффективность, подтвержденная этими проектами, вызвали большой интерес в компьютерной индустрии и с 1986 года началась активная промышленная реализация архитектуры RISC. К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд.
Следует отметить, что в последних разработках компании Intel (имеются в виду Pentium и Pentium Pro), а также ее последователей-конкурентов (AMD R5, Cyrix M1, NexGen Nx586 и др.) широко используются идеи, реализованные в RISC-микропроцессорах, так что многие различия между CISC и RISC стираются. Однако сложность архитектуры и системы команд x86 остается и является главным фактором, ограничивающим производительность процессоров на ее основе.
Архитектура системы на базе ServerNet
Новая системная архитектура, построенная на базе ServerNet, объединяет свойства систем NonStop и Integrity. Она решает общую задачу построения отказоустойчивых систем различного масштаба путем реализации гибких методов соединения стандартных функциональных блоков (модулей ЦП/памяти, подсистем внешней памяти и коммуникационных адаптеров).
Архитектура системы на базе ServerNet
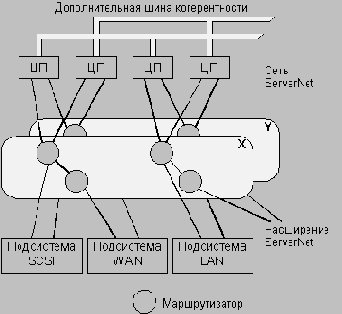
При работе под управлением операционных систем, поддерживающих отказоустойчивость программными средствами (подобных NonStop Kernel), процессорные узлы выполняют независимые потоки команд. В отличие от более ранних систем, которые для передачи сообщений между процессорами и реализации операций ввода/вывода использовали разные интерфейсы, в новой архитектуре все пересылки данных осуществляются ЦП по сети ServerNet.
При использовании операционных систем, в которых отсутствуют специальные средства поддержки отказоустойчивости, последнее свойство может быть реализовано с помощью аппаратных средств путем создания конфигураций ЦП в виде дуплексных пар. В этом случае пары узлов ЦП выполняют идентичные потоки команд. Если один ЦП из пары отказывает, другой продолжает работать. Таким процессорам в сети ServerNet присваивается общий идентификатор узла, и все пакеты, адресуемые с помощью этого идентификатора, дублируются и доставляются одновременно двум ЦП. При отсутствии неисправностей оба ЦП в паре создают идентичные исходящие пакеты. Поэтому в случае нормальной работы логика маршрутизации ServerNet может выбрать для пересылки пакеты любого узла. При этом для обнаружения неисправностей используются возможности самой сети ServerNet.
Как уже отмечалось, для обеспечения отказоустойчивости в системе Integrity требуются три процессорных кристалла и три массива микросхем памяти. Новая архитектура требует четырех процессорных кристаллов (два на модуль ЦП) и двух массивов микросхем памяти. Стоимость реализации этих двух подходов существенно зависит от размера памяти. Для типовых систем оба метода имеют сравнимую стоимость.
Блоксхема ЦП
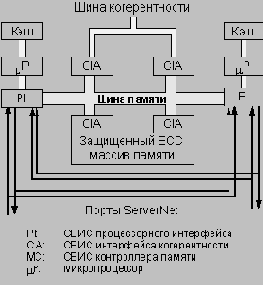
Как уже было отмечено, ЦП могут иметь прямой доступ к памяти других ЦП с помощью дополнительной шины когерентности. Эта шина обеспечивает аппаратную поддержку стандартных приложений UNIX или Windows NT, которые используют симметричную мультипроцессорную обработку (SMP). Каждый ЦП подсоединяется к шине с помощью пары самоконтролирующихся СБИС интерфейса когерентности. Эти СБИС обеспечивают кэш-когерентный доступ к общей памяти используя дублированную память тегов и стандартный протокол аннулирования блоков кэш-памяти. Они обеспечивают также когерентность кэш-памяти при выполнении обращений к памяти со стороны В/В. Все передачи данных по шине когерентности защищены кодом ECC. Проверка синдрома ECC для данных, пересылаемых по шине, и сравнение выходов СБИС позволяет обнаруживать сбои шины или СБИС интерфейса.
Операционная система, поддерживающая модель системы без разделения ресурсов (подобная NonStop Kernel), для увеличения степени изоляции ошибок может запретить работу с шиной когерентности. В этом режиме когерентность кэш-памяти для всех транзакций с памятью по сети ServerNet обеспечивается средствами системного программного обеспечения. Если же работа шины когерентности разрешена, то вообще говоря ошибка в одном ЦП может привести к отказу всех ЦП, подсоединенных к этой шине.
СБИС процессорного интерфейса ЦП реализуют два порта ServerNet. Линии приема данных обоих портов ServerNet подсоединяются к обеим СБИС процессорного интерфейса. Каждая СБИС формирует данные для передачи по обоим портам ServerNet, но реально данные передаются только из одного порта. Вторая СБИС принимает данные, передаваемые другой СБИС, сравнивает полученное значение со значением, которое она сформировала сама, и сигнализирует об ошибке при любом рассогласовании данных.
памяти данных тесно координирована. Например,
Целочисленное исполнительное устройство выполняет целочисленные
Устройство управления памятью выполняет все команды загрузки, записи и барьерные операции синхронизации. Оно содержит полностью ассоциативный 64-строчный буфер преобразования адресов (DTB), 8 Кбайт кэш-память данных с прямым отображением, файл адресов промахов и буфер записи. Длина строки в кэше данных равна 32 байтам, он имеет два порта по чтению и реализован по принципу сквозной записи. Он индексируется разрядами физического адреса и в тегах хранятся физические адреса. В устройство управления памятью в каждом такте может поступать до двух виртуальных адресов из целочисленного устройства. DTB также имеет два порта, поэтому он может одновременно выполнять преобразование двух виртуальных адресов в физические. Команды загрузки обращаются к кэшу данных и возвращают результат в регистровый файл в случае попадания. При этом задержка составляет два такта. В случае промаха физические адреса направляются в файл адресов промахов, где они буферизуются и ожидают завершения обращения к кэш-памяти второго уровня. Команды записи записывают данные в кэш данных в случае попадания и всегда помещают данные в буфер записи, где они ожидают обращения к кэш-памяти второго уровня.
Отличительной особенностью микропроцессора 21164 является размещение на кристалле вторичного трехканального множественно-ассоциативного кэша, емкостью 96 Кбайт. Вторичный кэш резко снижает количество обращений к внешней шине микропроцессора. Кроме вторичного кэша на кристалле поддерживается работа с внешним кэшем третьего уровня.
Сочетание большого количества вычислительных устройств, более быстрого выполнения операций с плавающей точкой (четыре такта вместо шести), более быстрого доступа к первичному кэшу (два такта вместо трех) обеспечивают новому микропроцессору рекордные параметры производительности.
Блоксхема процессора micro SparcII
Целочисленное устройство использует пятиступенчатый конвейер команд с одновременным запуском до двух команд. Устройство плавающей точки обеспечивает выполнение операций в соответствии со стандартом IEEE 754.
Устройство управления памятью выполняет четыре основных функции. Во-первых, оно обеспечивает формирование и преобразование виртуального адреса в физический. Эта функция реализуется с помощью ассоциативного буфера TLB. Кроме того, устройство управления памятью реализует механизмы защиты памяти. И, наконец, оно выполняет арбитраж обращений к памяти со стороны ввода/вывода, кэша данных, кэша команд и TLB.
Процессор microSPARC II имеет 64-битовую шину данных для связи с памятью и поддерживает оперативную память емкостью до 256 Мбайт. В процессоре интегрирован контроллер шины SBus, обеспечивающий эффективную с точки зрения стоимости реализацию ввода/вывода.
вывода посредством синхронной шины. Процессор
Устройство плавающей точки (рисунок 5.12) реализует арифметику с одинарной и двойной точностью в стандарте IEEE 754. Его устройство умножения используется также для выполнения операций целочисленного умножения. Устройства деления и вычисления квадратного корня работают с удвоенной частотой процессора. Арифметико-логическое устройство выполняет операции сложения, вычитания и преобразования форматов данных. Регистровый файл состоит из 28 64-битовых регистров, каждый из которых может использоваться как два 32-битовых регистра для выполнения операций с плавающей точкой одинарной точности. Регистровый файл имеет пять портов чтения и три порта записи, которые обеспечивают одновременное выполнение операций умножения, сложения и загрузки/записи.
В случае промаха при обращении
Блоксхема процессора Super SPARC hyperSPARC

Производительность процессоров hyperSPARC может меняться независимо от скорости работы внешней шины (MBus). Набор кристаллов hyperSPARC обеспечивает как синхронные, так и асинхронные операции с помощью специальной логики кристалла RT625. Отделение внутренней шины процессора от внешней шины позволяет увеличивать тактовую частоту процессора независимо от частоты работы подсистем памяти и ввода/вывода. Это обеспечивает более длительный жизненный цикл, поскольку переход на более производительные модули hyperSPARC не требует переделки всей системы.
Процессорный набор hyperSPARC с тактовой частотой 100 МГц построен на основе технологического процесса КМОП с тремя уровнями металлизации и проектными нормами 0.5 микрон. Внутренняя логика работает с напряжением питания 3.3В.
Блоксхема процессора UltraSPARC1 Устройство предварительной выборки и диспетчеризации команд
В процессоре реализована схема динамического прогнозирования направления ветвлений программы, основанная на двухбитовой истории переходов и обеспечивающая ускоренную обработку команд условного перехода. Для реализации этой схемы с каждыми двумя командами в I-кэше, связано специальное поле, хранящее двухбитовое значение прогноза. Таким образом, UltraSPARC-1 позволяет хранить информацию о направлении 2048 переходов, что превышает потребности большинства прикладных программ. Поскольку направление перехода может меняться каждый раз, когда обрабатывается соответствующая команда, состояние двух бит прогноза должно каждый раз модифицироваться для отражения реального исхода перехода. Эта схема особенно эффективна при обработке циклов.
Кроме того, в процессоре UltraSPARC-1 с каждыми четырьмя командами в I-кэше связано специальное поле, указывающее на следующую строку кэш-памяти, которая должна выбираться вслед за данной. Использование этого поля позволяет осуществлять выборку командных строк в соответствии с выполняемыми переходами, что обеспечивает для программ с большим числом ветвлений практически ту же самую пропускную способность команд, что и на линейном участке программы. Способность быстро выбрать команды по прогнозируемому целевому адресу команды перехода является очень важной для оптимизации производительности суперскалярного процессора и позволяет
UltraSPARC-1 эффективно выполнять "по предположению" (speculative) достаточно хитроумные последовательности условных переходов.
Используемые в UltraSPARC-1 механизмы динамического прогнозирования направления и свертки переходов сравнительно просты в реализации и обеспечивают высокую производительность. По результатам контрольных испытаний UltraSPARC-1 88% переходов по условиям целочисленных операций и 94% переходов по условиям операций с плавающей точкой предсказываются успешно.
Кэш-память команд
Кэш-память команд (I-кэш) представляет собой двухканальную множественно-ассоциативную кэш-память емкостью 16 Кбайт. Она организована в виде 512 строк, содержащих по 32 байта данных. С каждой строкой связан соответствующий адресный тег. Команды, поступающие для записи в I-кэш проходят предварительное декодирование и записываются в кэш-память вместе с соответствующими признаками, облегчающими их последующую обработку. Окончательное декодирование команд происходит перед их записью в буфер команд.
Большие объекты данных
Однако в ряде случаев возможностей сетей Ethernet или Token Ring может оказаться недостаточно. Чаще всего это случается, когда данные хранятся в базе в виде очень больших массивов. Например, в медицинских базах данных часто хранятся образы рентгеновских снимков, поскольку они могут быть легко быть объединены с другими данными истории болезни пациента; эти образы рентгеновских снимков часто бывают размером в 3-5 Мбайт. Другими примерами приложений с интенсивным использованием данных являются системы хранения/выборки документов, САПР в области механики и системы мультимедиа. В этих случаях наиболее подходящей сетевой средой является FDDI, хотя в сравнительно ближайшем будущем она может быть будет заменена на ATM или
100 Мбит Ethernet.
Для систем, требующих большей пропускной способности сети, чем обеспечивают
Ethernet или Token Ring, по существу до конца 1994 года FDDI была единственным выбором. Хотя концентраторы FDDI имеют значительно большую стоимость по сравнению с хабами Ethernet, установка выделенной сети между фронтальной системой и сервером СУБД оказывается достаточно простой и недорогой. Как определено в стандарте FDDI, минимальная сеть FDDI состоит только из двух систем, соединенных между собой с помощью единственного кабеля. Никаких концентраторов не требуется, а цены на некоторые интерфейсы FDDI в настоящее время упали до уровня менее $1500.
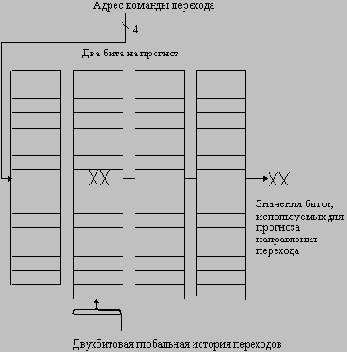
Буфер целевых адресов переходов
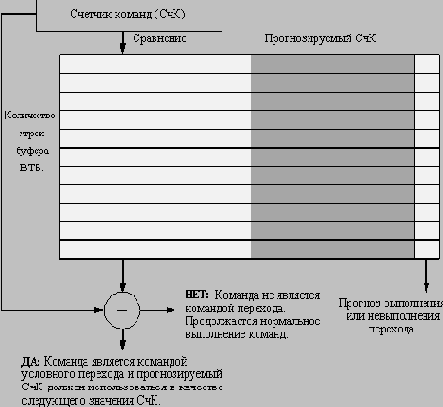
Еще одним методом уменьшения потерь на переходы является метод прогнозирования косвенных переходов, а именно переходов, адрес назначения которых меняется в процессе выполнения программы (в run-time). Компиляторы языков высокого уровня будут генерировать такие переходы для реализации косвенного вызова процедур, операторов select или case и вычисляемых операторов goto в Фортране. Однако подавляющее большинство косвенных переходов возникает в процессе выполнения программы при организации возврата из процедур. Например, для тестовых пакетов SPEC возвраты из процедур в среднем составляют 85% общего числа косвенных переходов.
Хотя возвраты из процедур могут прогнозироваться с помощью буфера целевых адресов переходов, точность такого метода прогнозирования может оказаться низкой, если процедура вызывается из нескольких мест программы или вызовы процедуры из одного места программы не локализуются по времени. Чтобы преодолеть эту проблему, была предложена концепция небольшого буфера адресов возврата, работающего как стек. Эта структура кэширует последние адреса возврата: во время вызова процедуры адрес возврата вталкивается в стек, а во время возврата он оттуда извлекается. Если этот кэш достаточно большой (например, настолько большой, чтобы обеспечить максимальную глубину вложенности вызовов), он будет прекрасно прогнозировать возвраты. На рисунке 3.17 показано исполнение такого буфера возвратов, содержащего от 1 до 16 строк (элементов) для нескольких тестов SPEC.
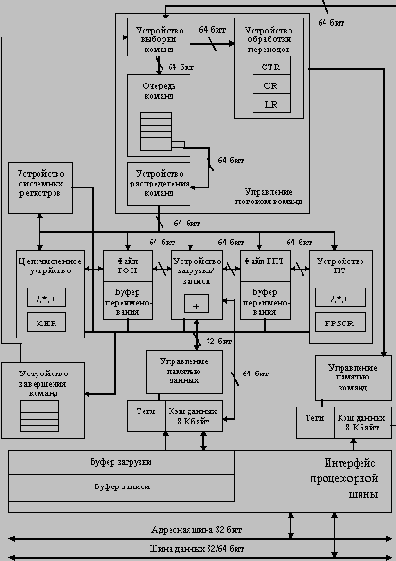
Буфер прогнозирования переходов
Каждая строка этого буфера включает программный адрес команды перехода, прогнозируемый адрес следующей команды и предысторию команды перехода (рисунок 3.16). Биты предыстории представляют собой информацию о выполнении или невыполнении условий перехода данной команды в прошлом. Обращение к буферу целевых адресов перехода (сравнение с полями программных адресов команд перехода) производится с помощью текущего значения счетчика команд на этапе выборки очередной команды. Если обнаружено совпадение (попадание в терминах кэш-памяти), то по предыстории команды прогнозируется выполнение или невыполнение условий команды перехода, и немедленно производится выборка и дешифрация команд из прогнозируемой ветви программы. Считается, что предыстория перехода, содержащая информацию о двух предшествующих случаях выполнения этой команды, позволяет прогнозировать развитие событий с вполне достаточной вероятностью.
Целочисленное исполнительное устройство
Главной задачей при разработке целочисленного исполнительного устройства (IEU) является обеспечение максимальной производительности при поддержке полной программной совместимости с существующим системным и прикладным ПО. Целочисленное исполнительное устройство UltraSPARC-1 объединяет в себе несколько важных особенностей:
2 АЛУ для выполнения арифметических и логических операций, а также операций сдвига; Многотактные целочисленные устройства умножения и деления; Регистровый файл с восемью окнами и четырьмя наборами глобальных регистров; Реализация цепей ускоренной пересылки результатов; Реализация устройства завершения команд, которое обеспечивает минимальное количество цепей обхода (ускоренной пересылки данных) при построении девятиступенчатого конвейера; Устройство загрузки/записи (LSU).LSU отвечает за формирование виртуального адреса для всех команд загрузки и записи (включая атомарные операции), за доступ к кэш-памяти данных, а также за буферизацию команд загрузки в случае промаха D-кэша (в буфере загрузки) и буферизацию команд записи (в буфере записи). В каждом такте может выдаваться для выполнения одна команда загрузки и одна команда записи.
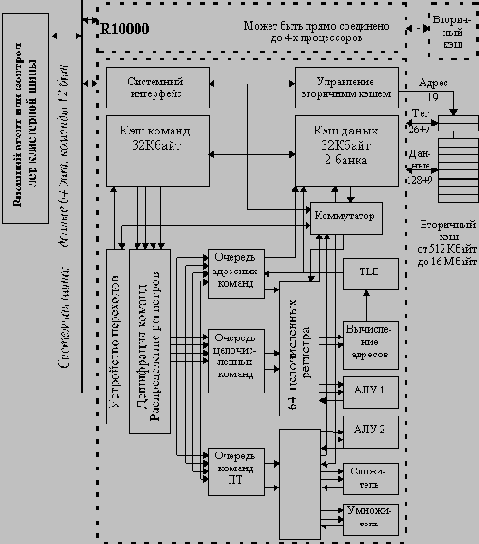
Целочисленные АЛУ
В микропроцессоре R10000 имеются два целочисленных АЛУ: АЛУ1 и АЛУ2. Время выполнения всех целочисленных операций АЛУ (за исключением операций умножения и деления) и частота повторений составляют один такт.
Оба АЛУ выполняют стандартные операции сложения, вычитания и логические операции. Эти операции завершаются за один такт. АЛУ1 обрабатывает все команды перехода, а также операции сдвига, а АЛУ2 - все операции умножения и деления с использованием итерационных алгоритмов. Целочисленные операции умножения и деления помещают свои результаты в регистры EntryHi и EntryLo.
Во время выполнения операций умножения в АЛУ2 могут выполняться другие однотактные команды, но сам умножитель оказывается занятым. Однако когда умножитель заканчивает свою работу, АЛУ2 оказывается занятым на два такта, чтобы обеспечить запись результата в два регистра. Во время выполнения операций деления, которые имеют очень большую задержку, АЛУ2 занято на все время выполнения операции.
Целочисленные операции умножения вырабатывают произведение с двойной точностью. Для операций с одинарной точностью происходит распространение знака результата до 64 бит прежде, чем он будет помещен в регистры EntryHi и EntryLo. Время выполнения операций с двойной точностью примерно в два раза превосходит время выполнения операций с одинарной точностью.
Challenge DataArray
Чтобы обеспечить еще большее масштабирование своих систем SGI сравнительно недавно выпустила на рынок продукт под названием Challenge DataArray. По существу он представляет собой слабо связанную систему, построенную на базе высокоскоростных 16-портовых коммутаторов, позволяющих объединить до восьми серверов Challenge DM, L или LX, и набор инструментальных средств по администрированию системы и управлению ее производительностью. Эти системы поддерживают популярные параллельные СУБД Informix Extended Parallel Server (XPS) и Oracle Parallel Server (OPS) и предназначены для построения крупномасштабных систем принятия решений.
Основу для построения системы дает стандартный Высокопроизводительный Параллельный Интерфейс (HiPPI - High Performance Parallel Interface), обеспечивающий передачу данных со скоростью до 100 Мбайт/с (для сравнения стандарт FDDI обеспечивает скорость 12,5 Мбайт/с). Это 32-битовая параллельная реализация, рассчитанная на соединения точка-точка. HiPPI обеспечивает высокую производительность сетевых приложений благодаря 8-кратному увеличению скорости передачи (по сравнению с FDDI) и возможности передавать пакеты большего размера, оптимальные для организации пересылок память-память. Система строится на 1-2 неблокируемых 16-портовых HIPPI-коммутаторах. В отличие от Ethernet, Token Ring или FDDI, HiPPI не использует общую среду передачи данных. Кабели, соединяющие два интерфейса HiPPI, содержат пакеты, передаваемые источником данных в симплексном режиме. Эти пакеты могут быть видны на промежуточных коммутаторах, но недоступны для других узлов системы. После пересылки пакета соединение может быть закрыто или остаться открытым для пересылки дополнительных пакетов. HiPPI имеет раздельное управление соединением, пакетами и передачей данных.
Системы Challenge поддерживают от 1 до 4 HiPPI-связей, каждая из которых имеет полосу пропускания в установившемся режиме 92 Мбайт/с.
В качестве системной консоли в Challenge DataArray используется рабочая станция Indy с 16-портовым мультиплексором последовательных портов. Программное обеспечение включает инструментальные средства администрирования и управления системой, высокопроизводительный драйвер, управляющий работой нескольких HiPPI-связей и интерфейс прикладного уровня для Oracle OPS и Informix XPS.
Challenge DM
Сервер сетевых ресурсов Challenge DM представляет собой систему начального уровня в семействе высокопроизводительных симметричных мультипроцессорных систем компании Silicon Graphics. Эти системы прежде всего нацелены на рынок баз данных, файловых серверов, серверов WWW, цифровой обработки данных и систем реального времени.
В архитектурном плане Challenge DM базируется на высокоскоростной системной шине с пропускной способностью в установившемся режиме 1.2 Гбайт/с и микропроцессорах MIPS R4400. Система поддерживает от 1 до 4 R4400, от 1 до 4 Мбайт кэш-памяти второго уровня на каждый процессор, до 6 Гбайт оперативной памяти и до трех подсистем ввода/вывода POWER Channel-2 с пропускной способностью 320 Мбайт/с.
В стандартной конфигурации серверы оснащаются одной подсистемой в/в POWER Challenge-2. Каждая такая подсистема включает контроллер Ethernet, два контроллера Fast/Wide 16-бит SCSI-2 с максимальной скоростью 20 Мбайт/с, два последовательных порта 19.2 Кбит/с RS232, один последовательный порт 38.4 Кбит/с RS422, параллельный порт и поддерживает работу до двух дополнительных дочерних плат (модулей) фирменного интерфейса в/в - HIO. Внешняя память систем может быть сформирована с помощью устройств CHALLENGE Vault L, CHALLENGE Vault XL и CHALLENGE RAID, которые обеспечивают наращивание емкости дисков до уровня 3.7 Тбайт без использования средств RAID и до 10 Тбайт RAID-памяти.
Для расширения возможностей серверов можно использовать адаптеры стандартной шины VME-64 и модули HIO. Дополнительно в серверы могут быть установлены адаптеры HiPPI, ATM, FDDI и 8-портовый адаптер Ethernet.
Эти серверы оснащаются инструментальными средствами системного администрирования, а также средствами надежного резервного копирования данных и управления внешней памятью. В качестве дополнительной возможности предлагаются средства обеспечения высокой готовности системы.
Challenge L
Серверы сетевых ресурсов Challenge L являются системами среднего класса в семействе высокопроизводительных симметричных мультипроцессорных систем SGI. Они также ориентированы на рынок мощных баз данных, файловых серверов, серверов WWW, цифровой обработки данных и систем реального времени.
В архитектурном плане они практически не отличаются от серверов Challenge DM, т.к. базируются на высокоскоростной системной шине с пропускной способностью в установившемся режиме 1.2 Гбайт/с. Но в качестве процессоров в них используются более современные микропроцессоры MIPS R10000, количество которых в системе может достигать 12. Система поддерживает от 2 до 12 процессоров R10000, от 1 до 4 Мбайт кэш-памяти второго уровня на каждый процессор, до 6 Гбайт оперативной памяти и до шести подсистем ввода/вывода POWER Channel-2 с пропускной способностью 320 Мбайт/с.
В стандартной конфигурации эти серверы имеют сходные характеристики с серверами Challenge DM, но имеют существенно большие возможности для расширения. В частности, внешняя память систем может быть сформирована с помощью устройств CHALLENGE Vault L, которые обеспечивают наращивание емкости дисков до уровня 5.6 Тбайт без использования средств RAID и до 17.4 Тбайт RAID-памяти.
Эти серверы также оснащаются мощными инструментальными средствами системного администрирования, а также средствами надежного резервного копирования данных и управления внешней памятью. В качестве дополнительной возможности предлагаются средства обеспечения высокой готовности системы.
Challenge S
В семействе серверов Challenge системы Challenge S представляют собой однопроцессорные компьютеры с достаточно высокой производительностью и хорошими возможностями для расширения. Архитектура этих серверов рассчитана на использование различных типов процессоров MIPS (в настоящее время используются процессоры R4400, R4600 и R5000) и высокоскоростной системной шины с пропускной способностью 267 Мбайт/с.
В стандартной конфигурации серверы Challenge S оснащаются двумя портами Ethernet, одним интерфейсом 10 Мбайт/с Fast SCSI-2 и двумя каналами Fast/Wide Differential SCSI-2, работающими со скоростью 20 Мбайт/с. Дальнейшее расширение возможно с помощью двух гнезд GIO, которые поддерживают дополнительные адаптеры SCSI, Ethernet, FDDI, ATM и видеоподсистемы. Внешняя дисковая память наращивается с помощью специальных шасси CHALLENGE Vault L, обеспечивающих 72 Гбайт дискового пространства. Максимальный объем дисков может достигать 277 Гбайт с использованием нескольких таких устройств.
Challenge XL
Серверы сетевых ресурсов Challenge XL представляют собой наиболее мощные высокопроизводительные симметричные мультипроцессорные системы компании SGI. По своим возможностям они сравнимы с компьютерами класса "мейнфрейм" и могут работать с базами данных огромных размеров.
Они также базируются на высокоскоростной системной шине с пропускной способностью в установившемся режиме 1.2 Гбайт/с и микропроцессорах MIPS R10000, но количество ЦП в этих системах может достигать 36. Система поддерживает от 2 до 36 процессоров R10000, от 1 до 4 Мбайт кэш-памяти второго уровня на каждый процессор, до 16 Гбайт оперативной памяти и до шести подсистем ввода/вывода POWER Channel-2 с пропускной способностью 320 Мбайт/с. Таким образом, основным свойством этих систем является масштабируемость за счет увеличения числа процессоров, объемов оперативной памяти и подсистем ввода/вывода.
Частота резервного копирования
Большинство пользователей выполняют полное резервное копирование ежедневно. Полагая, что резервное копирование выполняется на тот случай, когда понадобится восстановление, важно рассмотреть составляющие времени восстановления. Оно включает время перезаписи (обычно с ленты) и время, которое требуется для того, чтобы выполнить изменения, внесенные в базу данных с момента резервного копирования. Учитывая необходимость средств такой "прокрутки" вперед, очень важно зеркалировать журналы и журналы архивов, которые и делают этот процесс возможным.
В рабочей среде, где большое количество транзакций выполняют записи в базу данных, время, требуемое для выполнения "прокрутки" вперед от последней контрольной точки может существенно увеличить общее время восстановления. Это соображение само по себе может определить частоту резервного копирования.
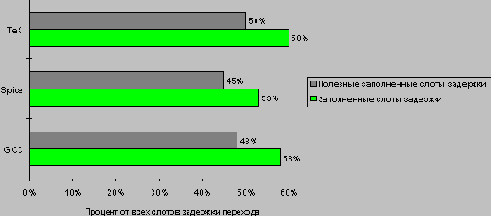
Частота заполнения одного слота
Как и в неконвейерных машинах двумя основными проблемами при реализации прерываний являются: (1) прерывания возникают в процессе выполнения некоторой команды; (2) необходим механизм возврата из прерывания для продолжения выполнения программы. Например, для нашего простейшего конвейера прерывание по отсутствию страницы виртуальной памяти при выборке данных не может произойти до этапа выборки из памяти (MEM). В момент возникновения этого прерывания в процессе обработки уже будут находиться несколько команд. Поскольку подобное прерывание должно обеспечить возврат для продолжения программы и требует переключения на другой процесс (операционную систему), необходимо надежно очистить конвейер и сохранить состояние машины таким, чтобы повторное выполнение команды после возврата из прерывания осуществлялось при корректном состоянии машины. Обычно это реализуется путем сохранения адреса команды (PC), вызвавшей прерывание. Если выбранная после возврата из прерывания команда не является командой перехода, то сохраняется обычная последовательность выборки и обработки команд в конвейере. Если же это команда перехода, то мы должны оценить условие перехода и в зависимости от выбранного направления начать выборку либо по целевому адресу команды перехода, либо следующей за переходом команды. Когда происходит прерывание, для корректного сохранения состояния машины необходимо выполнить следующие шаги:
-
В последовательность команд, поступающих на обработку в конвейер, принудительно вставить команду перехода на прерывание.
Пока выполняется команда перехода на прерывание, погасить все требования записи, выставленные командой, вызвавшей прерывание, а также всеми следующими за ней в конвейере командами. Эти действия позволяют предотвратить все изменения состояния машины командами, которые не завершились к моменту начала обработки прерывания.
После передачи управления подпрограмме обработки прерываний операционной системы, она немедленно должна сохранить значение адреса команды (PC), вызвавшей прерывание. Это значение будет использоваться позже для организации возврата из прерывания.
Если используются механизмы задержанных переходов, состояние машины уже невозможно восстановить с помощью одного счетчика команд, поскольку в процессе восстановления команды в конвейере могут оказаться вовсе не последовательными. В частности, если команда, вызвавшая прерывание, находилась в слоте задержки перехода и переход был выполненным, то необходимо заново повторить выполнение команд из слота задержки плюс команду, находящуюся по целевому адресу команды перехода. Сама команда перехода уже выполнилась и ее повторения не требуется. При этом адреса команд из слота задержки перехода и целевой адрес команды перехода естественно не являются последовательными. Поэтому необходимо сохранять и восстанавливать несколько счетчиков команд, число которых на единицу превышает длину слота задержки. Это выполняется на третьем шаге обработки прерывания.
После обработки прерывания специальные команды осуществляют возврат из прерывания путем перезагрузки счетчиков команд и инициализации потока команд. Если конвейер может быть остановлен так, что команды, непосредственно предшествовавшие вызвавшей прерывание команде, завершаются, а следовавшие за ней могут быть заново запущены для выполнения, то говорят, что конвейер обеспечивает точное прерывание. В идеале команда, вызывающая прерывание, не должна менять состояние машины, и для корректной обработки некоторых типов прерываний требуется, чтобы команда, вызывающая прерывание, не имела никаких побочных эффектов. Для других типов прерываний, например, для прерываний по исключительным ситуациям плавающей точки, вызывающая прерывание команда на некоторых машинах записывает свои результаты еще до того момента, когда прерывание может быть обработано. В этих случаях аппаратура должна быть готовой для восстановления операндов-источников, даже если местоположение результата команды совпадает с местоположением одного из операндов-источников.
Поддержка точных прерываний во многих системах является обязательным требованием, а в некоторых системах была бы весьма желательной, поскольку она упрощает интерфейс операционной системы. Как минимум в машинах со страничной организацией памяти или с реализацией арифметической обработки в соответствии со стандартом IEEE средства обработки прерываний должны обеспечивать точное прерывание либо целиком с помощью аппаратуры, либо с помощью некоторой поддержки со стороны программных средств.
Что такое TPC
По мере расширения использования компьютеров при обработке транзакций в сфере бизнеса все более важной становится возможность справедливого сравнения систем между собой. С этой целью в 1988 году был создан Совет по оценке производительности обработки транзакций (TPC - Transaction Processing Performance Council), который представляет собой бесприбыльную организацию. Любая компания или организация может стать членом TPC после уплаты соответствующего взноса. На сегодня членами TPC являются практически все крупнейшие производители аппаратных платформ и программного обеспечения для автоматизации коммерческой деятельности. К настоящему времени TPC создал три тестовых пакета для обеспечения объективного сравнения различных систем обработки транзакций и планирует создать новые оценочные тесты.
В компьютерной индустрии термин транзакция (transaction) может означать почти любой вид взаимодействия или обмена информацией. Однако в мире бизнеса "транзакция" имеет вполне определенный смысл: коммерческий обмен товарами, услугами или деньгами. В настоящее время практически все бизнес-транзакции выполняются с помощью компьютеров. Наиболее характерными примерами систем обработки транзакций являются системы управления учетом, системы резервирования авиабилетов и банковские системы. Таким образом, необходимость стандартов и тестовых пакетов для оценки таких систем все больше усиливается. До 1988 года отсутствовало общее согласие относительно методики оценки систем обработки транзакций. Широко использовались два тестовых пакета: Дебет/Кредит и TPI. Однако эти пакеты не позволяли осуществлять адекватную оценку систем: они не имели полных, основательных спецификаций; не давали объективных, проверяемых результатов; не содержали полного описания конфигурации системы, ее стоимости и методологии тестирования; не обеспечивали объективного, беспристрастного сравнения одной системы с другой.
Чтобы решить эти проблемы, и была создана организация TPC, основной задачей которой является точное определение тестовых пакетов для оценки систем обработки транзакций и баз данных, а также для распространения объективных, проверяемых данных в промышленности.
TPC публикует спецификации тестовых пакетов, которые регулируют вопросы, связанные с работой тестов. Эти спецификации гарантируют, что покупатели имеют объективные значения данных для сравнения производительности различных вычислительных систем. Хотя реализация спецификаций оценочных тестов оставлена на усмотрение индивидуальных спонсоров тестов, сами спонсоры, объявляя результаты TPC, должны представить TPC детальные отчеты, документирующие соответствие всем спецификациям. Эти отчеты, в частности, включают конфигурацию системы, методику калькуляции цены, диаграммы значений производительности и документацию, показывающую, что тест соответствует требованиям атомарности, согласованности, изолированности и долговечности (ACID - atomicity, consistency, isolation, and durability), которые гарантируют, что все транзакции из оценочного теста обрабатываются должным образом. Обычно при описании конфигурации системы приводятся блок-схемы подключения каналов и устройств ввода/вывода; детальный список аппаратных средств и программного обеспечения включает номера составных частей, их описание и номер версии/ревизии; в цену системы включена стоимость аппаратных средств и программного обеспечения, а также стоимость запасных частей, необходимых для эксплуатации системы в течение 5 лет; объем внешней памяти системы должен обеспечивать хранение информации о транзакциях за период 30, 90 или 180 дней.
Работой TPC руководит Совет Полного Состава (Full Council), который принимает все решения; каждая компания-участник имеет один голос, а для того, чтобы провести какое-либо решение, требуется две трети голосов. Управляющий Комитет (Steering Committee), состоящий из пяти представителей и избираемый ежегодно, надзирает за работой администрации TPC, поддерживает и обеспечивает все направления и рекомендации для членов Совета Полного Состава и Управляющего Комитета. В составе TPC имеются два типа подкомитетов: постоянные подкомитеты, которые управляют администрацией TPC, осуществляют связи с общественностью и обеспечивают выпуск документации; и технические подкомитеты, которые формируются для разработки предложений по оценочным тестам и распускаются после того, как их работа по разработке завершена.
Возможно наиболее важным аспектом тестов TPC является требование полного раскрытия всех деталей проведения испытаний. Информация, содержащаяся в отчете о проведении испытаний (FDR - Full Disclosure Report), должна обеспечивать возможность полного воспроизведения результатов. TPC также следит за тем, чтобы до появления FDR никакая информация не публиковалась. Каждый отчет проверяется советом технических советников, который состоит из ведущих специалистов по базам данных.
Тесты TPC
TPC определяет и управляет форматом нескольких тестов для оценки производительности OLTP (On-Line Transaction Processing), включая тесты TPC-A, TPC-B, TPC-C, TPC-D и TPC-E. Как уже отмечалось, создание оценочного теста является ответственностью организации, выполняющей этот тест. TPC требует только, чтобы при создании оценочного теста выполнялись определенные условия. Хотя упомянутые тесты TPC не представляют собой тесты для непосредственной оценки производительности баз данных, системы реляционных баз данных являются ключевыми компонентами любой системы обработки транзакций.
Следует отметить, что как и любой другой тест, ни один тест TPC не может измерить производительность системы, которая применима для любой возможной среды обработки транзакций, но эти тесты действительно могут помочь пользователю справедливо сравнивать похожие системы. Однако, когда пользователь делает покупку или планирует решение о покупке, он должен понимать, что никакой тест не может заменить его конкретную прикладную задачу.
Тест TPC-A
Выпущенный в ноябре 1989 года, тест TCP-A предназначался для оценки производительности систем, работающих в среде интенсивно обновляемых баз данных, типичной для приложений интерактивной обработки данных (OLDP - on-line data processing). Такая среда характеризуется:
множеством терминальных сессий в режиме on-line значительным объемом ввода/вывода при работе с дисками умеренным временем работы системы и приложений целостностью транзакций.Практически, при выполнении теста, эмулируется типичная вычислительная среда банка, включающая сервер базы данных, терминалы и линии связи. Этот тест использует одиночные, простые транзакции, интенсивно обновляющие базу данных. Одиночная транзакция (подобная обычной операции обновления счета клиента) обеспечивает простую, повторяемую единицу работы, которая проверяет ключевые компоненты системы OLTP. Более подробно транзакция состоит из выполнения следующих действий:
обновление счета клиента (дебет/кредит) обновление суммы наличных денег у кассира (дебет/кредит) обновление общей суммы наличных денег в филиале банка (дебет/кредит) запись номера счета клиента, филиала, кассира, суммы и даты операции в файл истории.Тест TPC-A определяет пропускную способность системы, измеряемую количеством транзакций в секунду (tps A), которые система может выполнить при работе с множеством терминалов. Одной из неопределенностей старого теста Дебет/Кредит, которая часто использовалась поставщиками систем, была возможность подгонки соотношений между объемами таблиц СЧЕТ/ФИЛИАЛ/КАССИР, позволяющая обойти узкие места в подсистемах ввода/вывода и блокировок. В тесте TPC-A (а также в тесте TPC-B) соотношение межу количеством строк в таблицах СЧЕТ, ФИЛИАЛ и КАССИР строго специфицировано и для каждого сообщаемого в отчете уровня tpsA (tpsB) размер базы данных как минимум должен быть следующим:
СЧЕТ 100000 * tpsmin
КАССИР 10 * tpsmin
ФИЛИАЛ 1 * tpsmin
Количество терминалов 10 * tpsmin,
где tpsmin должно быть больше, чем приводимый в отчете рейтинг системы. Таким образом, для системы, выполняющей 2000 транзакций в секунду, таблица СЧЕТ должна содержать 200 миллионов записей и т.д. Кроме того, должно быть гарантировано, что представленная в отчете скорость транзакций на специфицированной системе должна устойчиво поддерживаться минимально в течение 8-часового периода непрерывной работы системы (хотя реально измерения на тесте могли проводиться и в течение только одного часа). Тест TPC-A требует наличия внешней памяти для хранения информации об истории всех транзакций, накапливающейся в течение 90 дней в предположении о сохранении установившейся скорости работы в течение 8-часового рабочего дня.
В тесте TPC-A специфицировано также "время обдумывания" пользователя, которое должно составлять по крайней мере 10 секунд на терминал. Это означает, что никакой терминал не может выдавать транзакции со скоростью более 0.1 транзакции в секунду. Таким образом, в состав конфигурации системы, обеспечивающей рейтинг в 2000 tpsA, должно входить по крайней мере 20000 терминалов, последовательных портов и других аппаратных средств поддержки межсоединений. Чтобы обеспечить подобные требования к системе межсоединений, необходимо соответствующее количество рабочих станций, концентраторов или мультиплексоров и в отчете должна быть приведена блок-схема всей системы межсоединений. Правда в реальной жизни при проведении испытаний, как правило, терминалы эмулируются с помощью специальных эмуляторов удаленных терминалов (RTE - Remote Terminal Emulator) через соответствующие последовательные порты.
Тест TPC-A может выполняться в локальных или региональных вычислительных сетях. В этом случае его результаты определяют либо "локальную" пропускную способность (TPC-A-local Throughput), либо "региональную" пропускную способность (TPC-A-wide Throughput). Очевидно, эти два тестовых показателя нельзя непосредственно сравнивать. Спецификация теста TPC-A требует, чтобы все компании полностью раскрывали детали работы своего теста, свою конфигурацию системы и ее стоимость (с учетом пятилетнего срока обслуживания). Это позволяет определить нормализованную стоимость системы ($/tpsA).
Тест TPC-B
В августе 1990 года TPC одобрил TPC-B, интенсивный тест базы данных, характеризующийся следующими элементами:
значительный объем дискового ввода/вывода; умеренное время работы системы и приложений; целостность транзакций.TPC-B измеряет пропускную способность системы в транзакциях в секунду (tpsB). Поскольку имеются существенные различия между двумя тестами TPC-A и TPC-B (в частности, в TPC-B не выполняется эмуляция терминалов и линий связи), их нельзя прямо сравнивать. На Рисунок 2.2 показаны взаимоотношения между TPC-A и TPC-B.
Тест TPC-C
Тестовый пакет TPC-C с точки зрения реальных потребностей потребителей сделал огромный шаг вперед по отношению к тестам TPC-A и TPC-B. Хотя по своей сути он также моделирует оперативную обработку транзакций, его сложность по крайней мере на порядок превышает сложность тестов A и B: он использует несколько типов транзакций, более сложную базу данных и общую структуру выполнения. Тест TPC-C моделирует прикладную задачу обработки заказов. Он моделирует достаточно сложную систему OLTP, которая должна управлять приемом заказов, управлением учетом товаров и распространением товаров и услуг. Тест TPC-C осуществляет тестирование всех основных компонентов системы: терминалов, линий связи, ЦП, дискового в/в и базы данных.
TPC-С специфицирует время обдумывания и ввода с клавиатуры, которые обычно программируются в RTU при проведении испытаний.
TPC-C требует, чтобы выполнялись пять типов транзакций:
новый заказ, вводимый с помощью сложной экранной формы; простое обновление базы данных, связанное с платежом; простое обновление базы данных, связанное с поставкой; справка о состоянии заказов; справка по учету товаров.Диаграмм переходов состояний протокола MESI
Как уже было отмечено, одной из функций тегов L2 является уменьшение накладных расходов, связанных с ответами на запросы механизма наблюдения. Доступ к тегам L2 разделяется между процессорами и адресной шиной. Теги L2 практически выполняют роль фильтров по отношению к активностям наблюдения. Это позволяет процессорам продолжать обработку вместо того, чтобы отвечать на каждый запрос наблюдения. Хотя теги L2 представляют собой разделяемый между процессором и шиной ресурс, его захват настолько кратковременен, что практически не приводит ни к каким конфликтам.
Состояние строки кэш-памяти "модифицированная" означает в частности то, что кэш, хранящий такие данные, несет ответственность за правильность этих данных перед системой в целом. Поскольку в основной памяти эти данные недостоверны, это означает, что владелец такого кэша должен каким-либо способом гарантировать, что никакой другой модуль системы не прочитает эти недостоверные данные. Обычно для описания такой ответственности используется термин "вмешательство" (intervention), которое представляет собой действие, выполняемое устройством-владельцем модифицированных кэшированных данных при обнаружении запроса наблюдения за этими данными. Вмешательство сигнализируется с помощью ответа состоянием "строка модифицирована" протокола MESI, за которым следуют пересылаемые запросчику, а также потенциально в память, данные.
Для увеличения пропускной способности системы в PowerScale реализованы два способа выполнения функции вмешательства:
Немедленная кроссировка (Cross Immediate), которая используется когда канал данных источника и получателя свободны и можно пересылать данные через коммутатор на полной скорости. Поздняя кроссировка (Cross Late), когда ресурс (магистраль данных) занят, поэтому данные будут записываться в буфер коммутатора и позднее пересылаться запросчику.Диаграмма работы конвейера при структурном конфликте
При всех прочих обстоятельствах, машина без структурных конфликтов будет всегда иметь более низкий CPI (среднее число тактов на выдачу команды). Возникает вопрос: почему разработчики допускают наличие структурных конфликтов? Для этого имеются две причины: снижение стоимости и уменьшение задержки устройства. Конвейеризация всех функциональных устройств может оказаться слишком дорогой. Машины, допускающие два обращения к памяти в одном такте, должны иметь удвоенную пропускную способность памяти, например, путем организации раздельных кэшей для команд и данных. Аналогично, полностью конвейерное устройство деления с плавающей точкой требует огромного количества вентилей. Если структурные конфликты не будут возникать слишком часто, то может быть и не стоит платить за то, чтобы их обойти. Как правило, можно разработать неконвейерное, или не полностью конвейерное устройство, имеющее меньшую общую задержку, чем полностью конвейерное. Например, разработчики устройств с плавающей точкой компьютеров CDC7600 и MIPS R2010 предпочли иметь меньшую задержку выполнения операций вместо полной их конвейеризации.
Диаграмма работы модернизированного конвейера
Альтернативная схема прогнозирует переход как выполняемый. Как только команда условного перехода декодирована и вычислен целевой адрес перехода, мы предполагаем, что переход выполняемый, и осуществляем выборку команд и их выполнение, начиная с целевого адреса. Если мы не знаем целевой адрес перехода раньше, чем узнаем окончательное направление перехода, у этого подхода нет никаких преимуществ. Если бы условие перехода зависело от непосредственно предшествующей команды, то произошла бы приостановка конвейера из-за конфликта по данным для регистра, который является условием перехода, и мы бы узнали сначала целевой адрес. В таких случаях прогнозировать переход как выполняемый было бы выгодно. Дополнительно в некоторых машинах (особенно в машинах с устанавливаемыми по умолчанию кодами условий или более мощным (а потому и более медленным) набором условий перехода) целевой адрес перехода известен раньше окончательного направления перехода, и схема прогноза перехода как выполняемого имеет смысл.
Задержанные переходы
Четвертая схема, которая используется в некоторых машинах называется "задержанным переходом". В задержанном переходе такт выполнения с задержкой перехода длиною n есть:
команда условного перехода
следующая команда 1
следующая команда 2
.....
следующая команда n
целевой адрес при выполняемом переходе
Команды 1 - n находятся в слотах (временных интервалах) задержанного перехода. Задача программного обеспечения заключается в том, чтобы сделать команды, следующие за командой перехода, действительными и полезными. Аппаратура гарантирует реальное выполнение этих команд перед выполнением собственно перехода. Здесь используются несколько приемов оптимизации.
Планирование задержанных переходов осложняется (1) наличием ограничений на команды, размещение которых планируется в слотах задержки и (2) необходимостью предсказывать во время компиляции, будет ли условный переход выполняемым или нет. Рисунок 3.10 дает общее представление об эффективности планирования переходов для простейшего конвейера с одним слотом задержки перехода при использовании простого алгоритма планирования. Он показывает, что больше половины слотов задержки переходов оказываются заполненными. При этом почти 80% заполненных слотов оказываются полезными для выполнения программы. Это может показаться удивительным, поскольку условные переходы являются выполняемыми примерно в 53% случаев. Высокий процент использования заполненных слотов объясняется тем, что примерно половина из них заполняется командами, предшествовавшими команде условного перехода, выполнение которых необходимо независимо от того, выполняется ли переход, или нет.
Диаграмма состояния двухбитовой схемы прогнозирования
Как уже упоминалось, точность двухбитовой схемы прогнозирования зависит от того, насколько часто прогноз каждого перехода является правильным и насколько часто строка в буфере прогнозирования соответствует выполняемой команде перехода. Если строка не соответствует данной команде перехода, прогноз в любом случае делается, поскольку все равно никакая другая информация не доступна. Даже если эта строка соответствует совсем другой команде перехода, прогноз может быть удачным.
Какую точность можно ожидать от буфера прогнозирования переходов на реальных приложениях при использовании 2 бит на каждую строку буфера? Для набора оценочных тестов SPEC-89 буфер прогнозирования переходов с 4096 строками дает точность прогноза от 99% до 82%, т.е. процент неудачных прогнозов составляет от 1% до 18% (рисунок 3.14). Следует отметить, что буфер емкостью 4К строк считается очень большим. Буферы меньшего объема дадут худшие результаты.
Дисковые массивы и уровни RAID
Одним из способов повышения производительности ввода/вывода является использование параллелизма путем объединения нескольких физических дисков в матрицу (группу) с организацией их работы аналогично одному логическому диску. К сожалению, надежность матрицы любых устройств падает при увеличении числа устройств. Полагая интенсивность отказов постоянной, т.е. при экспоненциальном законе распределения наработки на отказ, а также при условии, что отказы независимы, получим, что среднее время безотказной работы (mean time to failure - MTTF) матрицы дисков будет равно:
MTTF одного диска / Число дисков в матрице
Для достижения повышенного уровня отказоустойчивости приходится жертвовать пропускной способностью ввода/вывода или емкостью памяти. Необходимо использовать дополнительные диски, содержащие избыточную информацию, позволяющую восстановить исходные данные при отказе диска. Отсюда получают акроним для избыточных матриц недорогих дисков RAID (redundant array of inexpensive disks). Существует несколько способов объединения дисков RAID. Каждый уровень представляет свой компромисс между пропускной способностью ввода/вывода и емкостью диска, предназначенной для хранения избыточной информации.
Когда какой-либо диск отказывает, предполагается, что в течение короткого интервала времени он будет заменен и информация будет восстановлена на новом диске с использованием избыточной информации. Это время называется средним временем восстановления (mean time to repair - MTTR). Этот показатель можно уменьшить, если в систему входят дополнительные диски в качестве "горячего резерва": при отказе диска резервный диск подключается аппаратно-программными средствами. Периодически оператор вручную заменяет все отказавшие диски. Четыре основных этапа этого процесса состоят в следующем:
определение отказавшего диска, устранение отказа без останова обработки; восстановление потерянных данных на резервном диске; периодическая замена отказавших дисков на новые.Дисковые подсистемы ввода/вывода
Как уже было отмечено при обсуждении требований к основной памяти, обращения к диску выполняются примерно в 30000 медленнее, чем к памяти. В результате, лучший способ оптимизации дискового ввода/вывода - вообще его не выполнять! Однако экономически это не оправдано. Таким образом, обеспечение достаточной пропускной способности (емкости доступа) подсистемы ввода/вывода, является решающим фактором для обеспечения высокой устойчивой производительности СУБД. Множество технических соображений приводят к некоторым удивительным результатам.
Дополнительные требования к памяти
Естественно конфигурация системы должна обеспечивать также пространство для традиционного использования памяти. В СУБД на базе UNIX всегда необходимо обеспечить по крайней мере 16 Мбайт для базовой операционной системы. Далее, необходимо предусмотреть пространство объемом 2-4 Мбайт для ряда программ СУБД (программ ведения журнала, проверки согласованного состояния, архиваторов и т.п.) и достаточно пространства для размещения в памяти двоичных кодов приложения. Объем двоичных кодов приложения составляет обычно 1-2 Мбайт, но иногда они могут достигать 16-20 Мбайт. Операционная система обеспечивает режим разделения двоичных кодов между множеством пользующихся ими процессов, поэтому необходимо резервировать пространство только для одной копии. Пространство для размещения самого кода сервера СУБД зависит от общей архитектуры сервера. Для архитектуры "2N" следует выделять по 100-500 Кбайт на пользователя. Многопотоковые архитектуры требуют только 60-150 Кбайт, поскольку они имеют намного меньше процессов и намного меньшие накладные расходы.
Существует также эмпирическое правило, которое гласит, что неразумно конфигурировать менее, чем примерно 64 Мбайт памяти на процессор. Обрабатываемая каждым ЦП дополнительная информация требует выделения некоторого пространства для того, чтобы обойти интенсивную фрагментацию памяти.
