Сравнение долей промахов для алгоритма
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти. запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall). Общий прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
При промахе во время записи имеются две дополнительные возможности:
разместить запись в кэш-памяти (write allocate) (называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении. не размещать запись в кэш-памяти (называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Сравнение качества 2битового прогноза
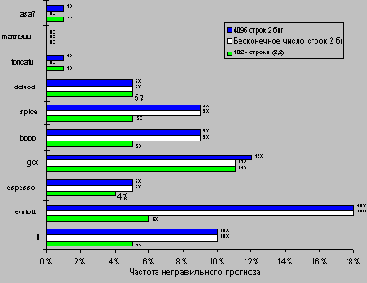
Поскольку главной задачей является использование максимально доступной степени параллелизма программы, точность прогноза направления переходов становится очень важной. Как видно из рисунка 3.14, точность схемы прогнозирования для целочисленных программ, которые обычно имеют более высокую частоту переходов, меньше, чем для научных программ с плавающей точкой, в которых интенсивно используются циклы. Можно решать эту проблему двумя способами: увеличением размера буфера и увеличением точности схемы, которая используется для выполнения каждого отдельного прогноза. Буфер с 4К строками уже достаточно большой и, как показывает рисунок 3.14, работает практически также, что и буфер бесконечного размера. Из этого рисунка становится также ясно, что коэффициент попаданий буфера не является лимитирующим фактором. Как мы упоминали выше, увеличение числа бит в схеме прогноза также имеет малый эффект.
Рассмотренные двухбитовые схемы прогнозирования используют информацию о недавнем поведении команды условного перехода для прогноза будущего поведения этой команды. Вероятно можно улучшить точность прогноза, если учитывать не только поведение того перехода, который мы пытаемся предсказать, но рассматривать также и недавнее поведение других команд перехода. Рассмотрим, например, небольшой фрагмент из текста программы eqntott тестового пакета SPEC92 (это наихудший случай для двухбитовой схемы прогноза):
if (aa==2)
aa=0;
if (bb==2)
bb=0;
if (aa!=bb) {
Ниже приведен текст сгенерированной программы (предполагается, что aa и bb размещены в регистрах R1 и R2):
SUBI R3,R1,#2
BNEZ R3,L1 ; переход b1 (aa!=2)
ADD R1,R0,R0 ; aa=0
L1: SUBI R3,R2,#2
BNEZ R3,L2 ; переход b2 (bb!=2)
ADD R2,R0,R0 ; bb=0
L2: SUB R3,R1,R2 ; R3=aa-bb
BEQZ R3,L3 ; branch b3 (aa==bb).
...
L3:
Пометим команды перехода как b1, b2 и b3. Можно заметить, что поведение перехода b3 коррелирует с переходами b1 и b2. Ясно, что если оба перехода b1 и b2 являются невыполняемыми (т.е. оба условия if оцениваются как истинные и обеим переменным aa и bb присвоено значение 0), то переход b3 будет выполняемым, поскольку aa и bb очевидно равны. Схема прогнозирования, которая для предсказания направления перехода использует только прошлое поведение того же перехода никогда этого не учтет.
Схемы прогнозирования, которые для предсказания направления перехода используют поведение других команд перехода, называются коррелированными или двухуровневыми схемами прогнозирования. Схема прогнозирования называется прогнозом (1,1), если она использует поведение одного последнего перехода для выбора из пары однобитовых схем прогнозирования на каждый переход. В общем случае схема прогнозирования (m,n) использует поведение последних m переходов для выбора из 2m схем прогнозирования, каждая из которых представляет собой n-битовую схему прогнозирования для каждого отдельного перехода. Привлекательность такого типа коррелируемых схем прогнозирования переходов заключается в том, что они могут давать больший процент успешного прогнозирования, чем обычная двухбитовая схема, и требуют очень небольшого объема дополнительной аппаратуры. Простота аппаратной схемы определяется тем, что глобальная история последних m переходов может быть записана в m-битовом сдвиговом регистре, каждый разряд которого запоминает, был ли переход выполняемым или нет. Тогда буфер прогнозирования переходов может индексироваться конкатенацией (объединением) младших разрядов адреса перехода с m-битовой глобальной историей. Например, на рисунке 3.15 показана схема прогнозирования (2,2) и организация выборки битов прогноза.
В этой реализации имеется тонкий эффект: поскольку буфер прогнозирования не является кэш-памятью, счетчики, индексируемые единственным значением глобальной схемы прогнозирования, могут в действительности в некоторый момент времени соответствовать разным командам перехода; это не отличается от того, что мы видели и раньше: прогноз может не соответствовать текущему переходу. На рисунке 3.15 с целью упрощения понимания буфер изображен как двумерный объект. В действительности он может быть реализован просто как линейный массив двухбитовой памяти; индексация выполняется путем конкатенации битов глобальной истории и соответствующим числом бит, требуемых от адреса перехода. Например, на рисунке 3.15 в буфере (2,2) с общим числом строк, равным 64, четыре младших разряда адреса команды перехода и два бита глобальной истории формируют 6-битовый индекс, который может использоваться для обращения к 64 счетчикам.
На рисунке 3.14 представлены результаты для сравнения простой двухбитовой схемы прогнозирования с 4К строками и схемы прогнозирования (2,2) с 1К строками. Как можно видеть, эта последняя схема прогнозирования не только превосходит простую двухбитовую схему прогнозирования с тем же самым количеством бит состояния, но часто превосходит даже двухбитовую схему прогнозирования с неограниченным (бесконечным) количеством строк. Имеется широкий спектр корреляционных схем прогнозирования, среди которых схемы (0,2) и (2,2) являются наиболее интересными.
Сравнение модели клиент/сервер

Режим разделения времени, в отличие от режима клиент/сервер, обычно обеспечивает большую производительность только тогда, когда требования к компоненту представления оказываются очень легкими, или когда одновременная пользовательская нагрузка невелика. Существенно что приложения, в основе компонента представления которых лежат формы, никогда не бывают легковесными. Даже приложения, работающие в диалоговом режиме printf/get обычно значительно более тяжелые, что позволяет оправдать использование конфигураций клиент/сервер. Тест TPC-A определяет возможно наиболее легкое требование приложения/представления (он включает ровно по одному вызову scaf(n) и printf(n)). Следует отметить, что даже тест TPC-A работает только на 5% быстрее в режиме разделения времени. Некоторые сравнительно недавние исследования компании Sun с использованием Oracle*Financials и Oracle 7 показали, что 6-процессорный сервер СУБД на базе SPARCserver 1000 с фронтальной системой на базе SPARCstation 10 Model 512 может поддерживать почти на 40% пользователей больше, чем 8-процессорный SPARCserver 1000, работающий в режиме разделения времени (Рисунок 2.3).
Рекомендации:
Всегда, если это возможно, следует применять конфигурацию клиент/сервер, если только нагрузка по прикладной обработке и обработке представления являются необычно легкими. Где это возможно, собственно сервер СУБД должен работать на выделенной системе.Стандарты шин
Обычно количество и типы устройств ввода/вывода в вычислительных системах не фиксируются, что позволяет пользователю самому подобрать необходимую конфигурацию. Шина ввода/вывода компьютера может рассматриваться как шина расширения, обеспечивающая постепенное наращивание устройств ввода/вывода. Поэтому стандарты играют огромную роль, позволяя разработчикам компьютеров и устройств ввода/вывода работать независимо. Появление стандартов определяется разными обстоятельствами.
Иногда широкое распространение и популярность конкретных машин становятся причиной того, что их шина ввода/вывода становится стандартом де факто. Примерами таких шин могут служить PDP-11 Unibus и IBM PC-AT Bus. Иногда стандарты появляются также в результате определенных достижений по стандартизации в некотором секторе рынка устройств ввода/вывода. Интеллектуальный периферийный интерфейс (IPI - Intelligent Peripheral Interface) и Ethernet являются примерами стандартов, появившихся в результате кооперации производителей. Успех того или иного стандарта в значительной степени определяется его принятием такими организациями как ANSI (Национальный институт по стандартизации США) или IEEE (Институт инженеров по электротехнике и радиоэлектронике). Иногда стандарт шины может быть прямо разработан одним из комитетов по стандартизации: примером такого стандарта шины является FutureBus.
На рисунке 3.26 представлены характеристики нескольких стандартных шин. Заметим, что строки этой таблицы, касающиеся пропускной способности, не указаны в виде одной цифры для шин процессор-память (VME, FutureBus, MultibusII). Размер пересылки, из-за разных накладных расходов шины, сильно влияет на пропускную способность. Поскольку подобные шины обычно обеспечивают связь с памятью, то пропускная способность шины зависит также от быстродействия памяти. Например, в идеальном случае при бесконечном размере пересылки и бесконечно быстрой памяти (время доступа 0 нсек) шина FutureBus на 240% быстрее шины VME, но при пересылке одиночных слов из 150-нсекундной памяти шина FutureBus только примерно на 20% быстрее, чем шина VME.
Одной из популярных шин персональных компьютеров была системная шина IBM PC/XT, обеспечивавшая передачу 8 бит данных. Кроме того, эта шина включала 20 адресных линий, которые ограничивали адресное пространство пределом в 1 Мбайт. Для работы с внешними устройствами в этой шине были предусмотрены также 4 линии аппаратных прерываний (IRQ) и 4 линии для требования внешними устройствами прямого доступа к памяти (DMA). Для подключения плат расширения использовались специальные 62-контактные разъемы. При этом системная шина и микропроцессор синхронизировались от одного тактового генератора с частотой 4.77 МГц. Таким образом теоретическая скорость передачи данных могла достигать немногим более 4 Мбайт/с.
Системная шина ISA (Industry Standard Architecture) впервые стала применяться в персональных компьютерах IBM PC/AT на базе процессора i286. Эта системная шина отличалась наличием второго, 36-контактного дополнительного разъема для соответствующих плат расширения. За счет этого количество адресных линий было увеличено на 4, а данных - на 8, что позволило передавать параллельно 16 бит данных и обращаться к 16 Мбайт системной памяти. Количество линий аппаратных прерываний в этой шине было увеличено до 15, а каналов прямого доступа - до 7. Системная шина ISA полностью включала в себя возможности старой 8-разрядной шины. Шина ISA позволяет синхронизировать работу процессора и шины с разными тактовыми частотами. Она работает на частоте 8 МГц, что соответствует максимальной скорости передачи 16 Мбайт/с.
С появлением процессоров i386, i486 и Pentium шина ISA стала узким местом персональных компьютеров на их основе. Новая системная шина EISA (Extended Industry Standard Architecture), появившаяся в конце 1988 года, обеспечивает адресное пространство в 4 Гбайта, 32-битовую передачу данных (в том числе и в режиме DMA), улучшенную систему прерываний и арбитраж DMA, автоматическую конфигурацию системы и плат расширения. Устройства шины ISA могут работать на шине EISA.
Шина EISA предусматривает централизованное управление доступом к шине за счет наличия специального устройства - арбитра шины. Поэтому к ней может подключаться несколько главных устройств шины. Улучшенная система прерываний позволяет подключать к каждой физической линии запроса на прерывание несколько устройств, что снимает проблему количества линий прерывания. Шина EISA тактируется частотой около 8 МГц и имеет максимальную теоретическую скорость передачи данных 33 Мбайт/с.
| VME bus | FutureBus | Multibus II | IPI | SCSI | |
| Ширина шины (кол-во сигналов) |
128 | 96 | 96 | 16 | 8 |
| Мультиплексирование адреса/данных |
Нет | Да | Да | ( | ( |
| Разрядность данных |
16/32 бит | 32 бит | 32 бит | 16 бит | 8 бит |
| Размер пересылки (слов) | Одиночная или групповая |
Одиночная или групповая |
Одиночная или групповая |
Одиночная или групповая |
Одиночная или групповая |
| Количество главных устройств шины |
Несколько | Несколько | Несколько | Одно | Несколько |
| Расщепление транзакций |
Нет | Доп. возможность | Доп. возможность | Доп. возможность | Доп. возможность |
| Полоса пропускания (время доступа - 0 нс - 1 слово) |
25.9 Мб/c | 37.0 Мб/c | 20.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c |
| Полоса пропускания (время доступа - 150 нс - 1 слово) |
12.9 Мб/c | 15.5 Мб/c | 10.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c |
| Полоса пропускания (время доступа - 0 нс - неогр. размер блока) |
27.9 Мб/c | 95.2 Мб/c | 40.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c |
| Полоса пропускания (время доступа - 150 нс - неогр. размер блока) |
13.6 Мб/c | 20.8 Мб/c | 13.3 Мб/c | 25.0 Мб/c | 5.0 Мб/c |
| Максимальное количество устройств |
21 | 20 | 21 | 8 | 7 |
| Максимальная длина шины |
0.5 м | 0.5 м | 0.5 м | 50 м | 25 м |
| Стандарт | IEEE 1014 | IEEE 896.1 | ANSI/ IEEE 1296 |
ANSI X3.129 |
ANSI X3.131 |
Страничная организация памяти
В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов (TLB traнсlation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
Структура очередей команд
Процессор R10000 содержит три очереди (буфера) команд (очередь целочисленных команд, очередь команд плавающей точки и адресную очередь). Эти три очереди осуществляют динамическую выдачу команд в соответствующие исполнительные устройства. С каждой командой в очереди хранится тег команды, который перемещается вместе с командой по ступеням конвейера. Каждая очередь осуществляет динамическое планирование потока команд и может определить моменты времени, когда становятся доступными операнды, необходимые для выполнения каждой команды. Кроме того, очередь определяет порядок выполнения команд на основе анализа состояния соответствующих исполнительных устройств. Как только ресурс оказывается свободным очередь выдает команду в соответствующее исполнительное устройство.
Обе модели работают под управлением
Таблица 4.16. Основные параметры моделей CM и CO семейства Integrity S4000
| S4000-CM | S4000-CO | |
| Возможности стойки | ||
| Количество плат SPU | 4 | 8 |
| Процессорные конфигурации: | ||
| Симплексная | 1-4 проц.SMP | 1-4 проц.SMP |
| Дуплексная (отказоустойчивая) | 1-2 проц.SMP | 1-4 проц.SMP |
| Количество маршрутизаторов | 2 | 4 |
| Количество плат SSC | 2 | 4 |
| Количество гнезд в/в ServerNet | 10 | 20 |
| Количество мест установки устройств внешней памяти |
12 | 36 |
| Процессор | ||
| Микропроцессор | MIPS RISC R4400 | MIPS RISC R4400 |
| Тактовая частота | 200 МГц | 200 МГц |
| Первичный кэш | 16 Кб - команды 16 Кб - данные |
16 Кб - команды 16 Кб - данные |
| Вторичный кэш | 1 Мб / процессор | 1 Мб / процессор |
| Основная память | ||
| Объем | 128/256ECC/проц. | 128/256ECC/проц. |
| Максимально в системе | 1024 Мб | 1024 Мб |
| Пропускная способность шины памяти (пиковая) | 400 Мб/с / проц. | 400 Мб/с / проц. |
| Подсистема в/в | ||
| Количество каналов в/в | 2 подсистемы в/в ServerNet |
2 подсистемы в/в ServerNet |
| Пропускная способность каналов в/в (пиковая) | 200 Мб/с / проц. | 150 Мб/с / проц. |
| Пропускная способность каналов в/в (пиковая) | 800 Мб/с / сист. | 600 Мб/с / сист. |
Структурные конфликты и способы их минимизации
Совмещенный режим выполнения команд в общем случае требует конвейеризации
функциональных устройств и дублирования ресурсов для разрешения всех возможных комбинаций команд в конвейере. Если какая-нибудь комбинация команд не может
быть принята из-за конфликта по ресурсам, то говорят, что в машине имеется структурный конфликт. Наиболее типичным примером машин, в которых возможно появление структурных конфликтов, являются машины с не полностью конвейерными функциональными устройствами. Время работы такого устройства может составлять несколько тактов синхронизации конвейера. В этом случае последовательные команды,
которые используют данное функциональное устройство, не могут поступать в него в каждом такте. Другая возможность появления структурных конфликтов связана с
недостаточным дублированием некоторых ресурсов, что препятствует выполнению
произвольной последовательности команд в конвейере без его приостановки. Например, машина может иметь только один порт записи в регистровый файл, но при определенных обстоятельствах конвейеру может потребоваться выполнить две записи в регистровый файл в одном такте. Это также приведет к структурному конфликту. Когда
последовательность команд наталкивается на такой конфликт, конвейер приостанавливает выполнение одной из команд до тех пор, пока не станет доступным требуемое
устройство.
Структурные конфликты возникают, например, и в машинах, в которых имеется единственный конвейер памяти для команд и данных (рисунок 3.3). В этом случае, когда одна команда содержит обращение к памяти за данными, оно будет конфликтовать с выборкой более поздней команды из памяти. Чтобы разрешить эту ситуацию, можно просто приостановить конвейер на один такт, когда происходит обращение к памяти за данными. Подобная приостановка часто называются "конвейерным пузырем" (pipeline bubble) или просто пузырем, поскольку пузырь проходит по конвейеру, занимая место, но не выполняя никакой полезной работы.
| Команда | Номер такта | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Команда загрузки | IF | ID | EX | MEM | WB | |||||
| Команда 1 | IF | ID | EX | MEM | WB | |||||
| Команда 2 | IF | ID | EX | MEM | WB | |||||
| Команда 3 | stall | IF | ID | EX | MEM | WB | ||||
| Команда 4 | IF | ID | EX | MEM | WB | |||||
| Команда 5 | IF | ID | EX | MEM | ||||||
| Команда 6 | IF | ID | EX |
SuperSPARC
Имеется несколько версий этого процессора, позволяющего в зависимости от смеси команд обрабатывать до трех команд за один машинный такт, отличающихся тактовой частотой (50, 60, 75 и 85 МГц). Процессор SuperSPARC (рисунок 5.3) имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб - кэш команд и 16 Кб - кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS. Процессор SuperSPARC применяется также в серверах SPARCserver 1000 и SPARCcenter 2000 компании Sun.
Конструктивно кристалл монтируется на взаимозаменяемых процессорных модулях трех типов, отличающихся наличием и объемом кэш-памяти второго уровня и тактовой частотой. Модуль M-bus SuperSPARC, используемый в модели 50 содержит 50-МГц SuperSPARC процессор с внутренним кэшем емкостью 36 Кб (20 Кб кэш команд и 16 Кб кэш данных). Модули M-bus SuperSPARC в моделях 51, 61 и 71 содержат по одному SuperSPARC процессору, работающему на частоте 50, 60 и 75 МГц соответственно, одному кристаллу кэш-контроллера (так называемому SuperCache), а также внешний кэш емкостью 1 Мб. Модули M-bus в моделях 502, 612, 712 и 514 содержат два SuperSPARC процессора и два кэш-контроллера каждый, а последние три модели и по одному 1 Мб внешнему кэшу на каждый процессор. Использование кэш-памяти позволяет модулям CPU работать с тактовой частотой, отличной от тактовой частоты материнской платы; пользователи всех моделей поэтому могут улучшить производительность своих систем заменой существующих модулей CPU вместо того, чтобы производить upgrade всей материнской платы.
Типовая архитектура машины с распределенной памятью Модели связи и архитектуры памяти
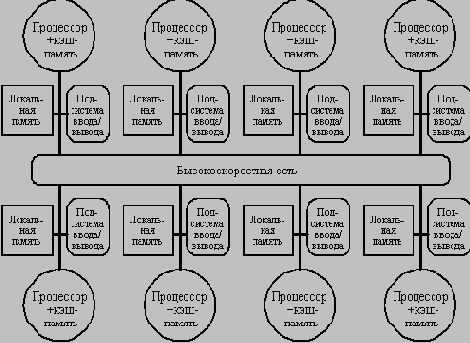
В альтернативном случае, адресное пространство состоит из отдельных адресных пространств, которые логически не связаны и доступ к которым не может быть осуществлен аппаратно другим процессором. В таком примере каждый модуль процессор-память представляет собой отдельный компьютер, поэтому такие системы называются многомашинными (multicomputers).
С каждой из этих организаций адресного пространства связан свой механизм обмена. Для машины с единым адресным пространством это адресное пространство может быть использовано для обмена данными посредством операций загрузки и записи. Поэтому эти машины и получили название машин с разделяемой (общей) памятью. Для машин с множеством адресных пространств обмен данными должен использовать другой механизм: передачу сообщений между процессорами; поэтому эти машины часто называют машинами с передачей сообщений.
Каждый из этих механизмов обмена имеет свои преимущества. Для обмена в общей памяти это включает:
Совместимость с хорошо понятными используемыми как в однопроцессорных, так и маломасштабных многопроцессорных системах, механизмами, которые используют для обмена общую память. Простота программирования, когда модели обмена между процессорами сложные или динамически меняются во время выполнения. Подобные преимущества упрощают конструирование компилятора. Более низкая задержка обмена и лучшее использование полосы пропускания при обмене малыми порциями данных. Возможность использования аппаратно управляемого кэширования для снижения частоты удаленного обмена, допускающая кэширование всех данных как разделяемых, так и неразделяемых.Основные преимущества обмена с помощью передачи сообщений являются:
Аппаратура может быть более простой, особенно по сравнению с моделью разделяемой памяти, которая поддерживает масштабируемую когерентность кэш-памяти. Модели обмена понятны, принуждают программистов (или компиляторы) уделять внимание обмену, который обычно имеет высокую, связанную с ним стоимость.Конечно, требуемая модель обмена может быть надстроена над аппаратной моделью, которая использует любой из этих механизмов. Поддержка передачи сообщений над разделяемой памятью, естественно, намного проще, если предположить, что машины имеют адекватные полосы пропускания. Основные трудности возникают при работе с сообщениями, которые могут быть неправильно выровнены и сообщениями произвольной длины в системе памяти, которая обычно ориентирована на передачу выровненных блоков данных, организованных как блоки кэш-памяти. Эти трудности можно преодолеть либо с небольшими потерями производительности программным способом, либо существенно без потерь при использовании небольшой аппаратной поддержки.
Построение механизмов реализации разделяемой памяти над механизмом передачи сообщений намного сложнее. Без предполагаемой поддержки со стороны аппаратуры все обращения к разделяемой памяти потребуют привлечения операционной системы как для обеспечения преобразования адресов и защиты памяти, так и для преобразования обращений к памяти в посылку и прием сообщений. Поскольку операции загрузки и записи обычно работают с небольшим объемом данных, то большие накладные расходы по поддержанию такого обмена делают невозможной чисто программную реализацию.
При оценке любого механизма обмена критичными являются три характеристики производительности:
-
Полоса пропускания: в идеале полоса пропускания механизма обмена будет ограничена полосами пропускания процессора, памяти и системы межсоединений, а не какими-либо аспектами механизма обмена. Связанные с механизмом обмена накладные расходы (например, длина межпроцессорной связи) прямо воздействуют на полосу пропускания.
Задержка: в идеале задержка должна быть настолько мала, насколько это возможно. Для ее определения критичны накладные расходы аппаратуры и программного обеспечения, связанные с инициированием и завершением обмена.
Упрятывание задержки:
насколько хорошо механизм скрывает задержку путем перекрытия обмена с вычислениями или с другими обменами.
Каждый из этих параметров производительности воздействует на характеристики обмена. В частности, задержка и полоса пропускания могут меняться в зависимости от размера элемента данных. В общем случае, механизм, который одинаково хорошо работает как с небольшими, так и с большими объемами данных будет более гибким и эффективным.
Таким образом, отличия разных машин с распределенной памятью определяются моделью памяти и механизмом обмена. Исторически машины с распределенной памятью первоначально были построены с использованием механизма передачи сообщений, поскольку это было очевидно проще и многие разработчики и исследователи не верили, что единое адресное пространство можно построить и в машинах с распределенной памятью. С недавнего времени модели обмена с общей памятью действительно начали поддерживаться практически в каждой разработанной машине (характерным примером могут служить системы с симметричной мультипроцессорной обработкой). Хотя машины с централизованной общей памятью, построенные на базе общей шины все еще доминируют в терминах размера компьютерного рынка, долговременные технические тенденции направлены на использование преимуществ распределенной памяти даже в машинах умеренного размера. Как мы увидим, возможно наиболее важным вопросом, который встает при создании машин с распределенной памятью, является вопрос о кэшировании и когерентности кэш-памяти.
Типовая архитектура мультипроцессорной системы с общей памятью
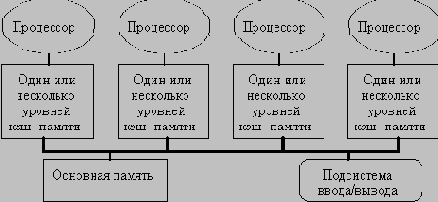
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров. С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т.е. число процессоров в системе), для которых требуется организация распределенной памяти, уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти.
Распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Эти два преимущества еще больше сокращают количество процессоров, для которых архитектура с распределенной памятью имеет смысл.
Обычно устройства ввода/вывода, также как и память, распределяются по узлам и в действительности узлы могут состоять из небольшого числа (2-8) процессоров, соединенных между собой другим способом. Хотя такая кластеризация нескольких процессоров с памятью и сетевой интерфейс могут быть достаточно полезными с точки зрения эффективности в стоимостном выражении, это не очень существенно для понимания того, как такая машина работает, поэтому мы пока остановимся на системах с одним процессором на узел. Основная разница в архитектуре, которую следует выделить в машинах с распределенной памятью заключается в том, как осуществляется связь и какова логическая модель памяти.
Типовая среда обработки транзакций и соответствующие оценочные тесты TPC
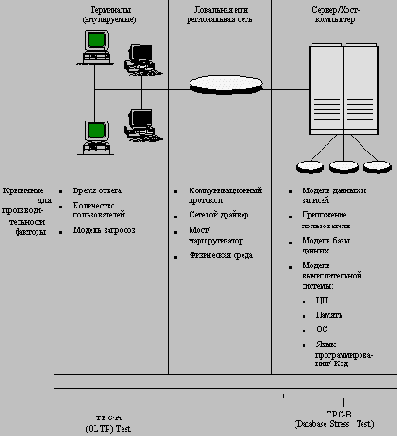
База данных TPC-C основана на модели оптового поставщика с удаленными районами и товарными складами. База данных содержит девять таблиц: товарные склады, район, покупатель, заказ, порядок заказов, новый заказ, статья счета, складские запасы и история.
Обычно публикуются два результата (таблица 2.2). Один из них, tpmC, представляет пиковую скорость выполнения транзакций (выражается в количестве транзакций в минуту и представляет собой максимальную пропускную способность системы (MQTh - Maximum Qualified Throghput)). Второй результат, $/tpmC, представляет собой нормализованную стоимость системы. Стоимость системы включает все аппаратные средства и программное обеспечение, используемые в тесте, плюс стоимость обслуживания в течение пяти лет.
Таблица 2.2..
TPC-C Results
| Company | System | Throughput (tmpC) | Price/Perf ($/tmpC) | Database Software |
| Compaq | ProLiant 5000 6/166 4/Pentium Pro/166MHz |
6184.90 | $111 | Microsoft SQL Server 6.5 |
| Compaq | ProLiant 5000 6/200 4/Pentium Pro/200MHz |
6750.53 | $90 | Microsoft SQL Server 6.5 |
| Digital | AlphaServer 8400 5/350 8/DECchip21164/350MHz |
14227.25 | $269 | Oracle Rbd7 V7.0 |
| Digital | AlphaServer 4100 5/400 4/DECchip21164/400MHz |
7985.15 | $174 | Oracle Rbd7 V7.0 |
| Digital | AlphaServer 4100 5/400 4/DECchip21164/400MHz |
7598.63 | $152 | Sybase SQL Server 11.0 |
| HP | HP 9000 Model D370 2/PA-RISC 8000/160MHz |
5822.23 | $148 | Sybase SQL Server 11.0.3 |
| HP | HP 9000 Model K460 4/PA-RISC 8000/180MHz |
12321.87 | $187 | Sybase SQL Server 11.0.3 |
| IBM | RS6000 PowerPC Server J40 8/Power PC 604/112MHz |
5774.07 | $243 | Sybase SQL Server 11.0.3 |
| SGI | Challenge XL Server 16/R4400/250MHz |
6313.78 | $479 | Informix OnLine V.7.11.UDI |
| Sun | Ultra Enterprise 4000 12/UltraSPARC/167MHz |
11465.93 | $189 | Sybase SQL Server 11.0.2 |
| Sun | Ultra Enterprise 3000 6/UltraSPARC/167MHz |
6662.47 | $152 | Sybase SQL Server 11.0.2 |
Масштаб системы расширяется путем увеличения количества товарных складов, причем каждый товарный склад должен поддерживать:
максимально 11.5 tpmC MQTh (приводимая в отчете метрика); примерно 26 транзакций различной сложности в минуту; 10 терминалов со средним временем обдумывания и ввода данных равным 23 секунды; 367 Мбайт (неформатированных) данных для хранения истории за период в 180 дней.Таким образом, рейтинг в 10000 tpmC MQTh предполагает примерно 0.5 терабайт внешней памяти!
Будущие тесты TCP
Сравнительно недавно (см. ComputerWorld-Moscow, N15, 1995) TPC объявил об отмене тестов TPC-A и TPC-B. Отныне для оценки систем будут применяться существующий тестовый пакет TPC-C, новые тесты TPC-D и TPC-E, а также два еще полностью не разработанных теста. Представленный в первом квартале 1995 года тест TPC-D предназначен для оценки производительности систем принятия решений. Для оценки систем масштаба предприятия во втором квартале 1995 года TPC должен был представить тест
TPC-E и его альтернативный вариант, не имеющий пока названия. Кроме того, TPC продолжает разработку тестовых пакетов для оценки баз данных и систем клиент/сервер. Первые результаты, полученные с помощью этих новых методов, уже начали публиковаться.
Типовой процессорный модуль
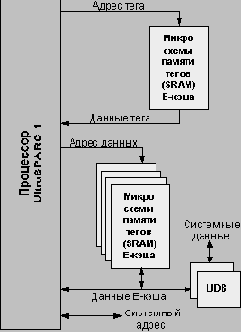
состоит из собственно процессора
Типовой процессорный модуль (рисунок 5.8). UltraSPARC- 1 состоит из собственно процессора UltraSPARC-1, микросхем синхронной статической памяти (SRAM), используемых для построения памяти тегов и данных внешнего кэша и двух кристаллов буферов системных данных (UDB). UDB изолируют внешний кэш процессора от остальной части системы и обеспечивают буферизацию данных для приходящих и исходящих системных транзакций, а также формирование, проверку контрольных разрядов и автоматическую коррекцию данных (с помощью ECC-кодов). Таким образом, UDB позволяет интерфейсу работать на тактовой частоте процессора (за счет снижения емкостной нагрузки).
Типовые значения ключевых параметров для кэшпамяти рабочих станций и серверов
На рисунке 3.21 представлен типичный набор параметров, который используется для описания кэш-памяти.
Рассмотрим организацию кэш-памяти более детально, отвечая на четыре вопроса об иерархии памяти.
Точность прогноза для адресов возврата
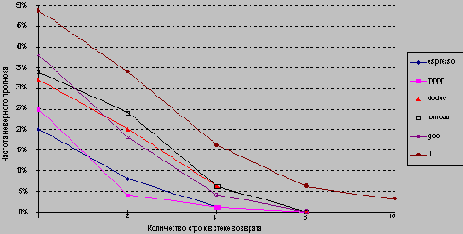
Схемы прогнозирования условных переходов ограничены как точностью прогноза, так и потерями в случае неправильного прогноза. Как мы видели, типичные схемы прогнозирования достигают точности прогноза в диапазоне от 80 до 95% в зависимости от типа программы и размера буфера. Кроме увеличения точности схемы прогнозирования, можно пытаться уменьшить потери при неверном прогнозе. Обычно это делается путем выборки команд по обоим ветвям (по предсказанному и по непредсказанному направлению). Это требует, чтобы система памяти была двухпортовой, включала кэш-память с расслоением, или осуществляла выборку по одному из направлений, а затем по другому (как это делается в IBM POWER-2). Хотя подобная организация увеличивает стоимость системы, возможно это единственный способ снижения потерь на условные переходы ниже определенного уровня. Другое альтернативное решение, которое используется в некоторых машинах, заключается в кэшировании адресов или команд из нескольких направлений (ветвей) в целевом буфере.
Трафик символьного терминала
Общей ошибкой пользователей является представление о том, что сетевой трафик, связанный с терминальными серверами, может перегрузить Ethernet. Это неправильно. Рассмотрим, например, 64-портовый сетевой терминальный сервер, который может управлять каждым портом, работающим со скоростью 38400 бод, или 38400 символов в секунду. (В каждом байте данных содержится 8 бит информации, но рейтинг бод включает биты старта и стопа). Если каждый порт работает на полной скорости 38400 бод, то всего за одну секунду по сети будет пересылаться 2457600 байт данных (или примерно 1.9 Мбит, т.е. около 20% максимальной загрузки Ethernet) с главной системы в терминальный сервер для дальнейшего распределения. Конечно имеются некоторые накладные расходы (дополнительные байты TCP/IP), связанные с этим уровнем трафика, но они составляют примерно 50 байт на пакет, т.е. примерно 4% для этого уровня трафика. Это сценарий наихудшего случая, например, когда на полной скорости работают 64 принтера. Типичный же уровень трафика намного ниже: один 2000-символьный экран может отображаться один раз в минуту. При этих условиях 64-портовый терминальный сервер обрабатывает примерно 35 байт в секунду на один порт или всего примерно 2 Кбайт/с.
Операции по вводу символов с клавиатуры терминала можно вообще не рассматривать, поскольку даже самая быстрая машинистка печатает только 20 символов в секунду (более типичный случай 1.0 - 1.5 символов в секунду). Даже если операции ввода обрабатываются в режиме cbreak, наибольшая нагрузка, которая будет генерироваться всеми пользователями, может составлять 1300 символов в секунду (по 20 символов в секунду на каждый порт при 64 портах). После учета максимальных накладных расходов TCP/IP это дает общий поток в 80 Кбайт/с . Типичные нагрузки (64 порта по 1.5 символа в секунду) будут составлять порядка 15 Кбайт/с с учетом накладных расходов.
представляет собой однопроцессорный сервер,
Ultra Enterprise 1 представляет собой однопроцессорный сервер, построенный на базе микропроцессора UltraSPARC 1 с тактовой частотой 143 или 167 МГц в настольной конструкции. Объем кэш-памяти второго уровня составляет 512 Кб, оперативная память может расширяться от 32 Мб до 1 Гб, а максимальная емкость дисков может достигать 324 Гб.
в настольной конструкции, построенный на
Ultra Enterprise 2 - симметричный двухпроцессорный сервер в настольной конструкции, построенный на базе процессоров UltraSPARC 1 с тактовой частотой 167 или 200 МГц и объемом кэш-памяти второго уровня 512 Кб или 1 Мб. Максимальный объем оперативной памяти может достигать 2 Гб, а дисков 1 Тб. Сервер имеет 4 слота расширения периферийной шины SBus, 1 слот UPA и оснащается интерфейсом Fast/Wide SCSI-2 и контроллером 10/100 Мбит/с FastEthernet.
Семейство серверов Ultra Enterprise 3000,
Семейство серверов Ultra Enterprise 3000, Ultra Enterprise 4000 представляют собой мощные, многоцелевые симметричные мультипроцессорные системы с повышенным уровнем готовности в компактной конструкции. Пропускная способность системной шины 2.5 Гбайт/с позволяет легко объединить до 6 или 12 процессоров (в системах 3000 и 4000 соответственно). Модульная конструкция позволяет легко варьировать количество процессорных плат и плат ввода вывода, а, следовательно, приспосабливать конфигурацию системы к конкретным нуждам заказчика. В системах 3000 объем оперативной памяти может достигать 6 Гбайт, максимальная емкость внутренних дисков - 42 Гбайт, а полная емкость поддерживаемой дисковой памяти превышать 2 Тбайта. В системах 4000 эти показатели равны соответственно 12 Гбайт, 16.8 Гбайт и более 4 Тбайт. Повышенный уровень готовности серверов обеспечивается возможностью замены большинства компонентов системы без выключения питания, применением методов избыточности в системах питания и охлаждения, а также специальным системным монитором SyMON, выполняющим постоянное диагностирование компонентов с целью предупреждения отказов системы.
и 6000 являются очень мощными
Семейства серверов 5000 и 6000 являются очень мощными системами, обеспечивающими работу с огромными базами данных. Эти серверы оформлены в стоечной конструкции, но используют унифицированные с серверами 3000 и 4000 компоненты. Запас пропускной способности системной шины (2.5 Гбайт/с) позволяет строить системы с 14 (модели 5000) и 30 (модели 6000) процессорами. Максимальный объем оперативной памяти в системах 5000 составляет 14 Гбайт, максимальная емкость внутренних дисков 216 Гбайт, а общая дисковая память может достигать более 6 Тбайт. Для систем 6000 эти показатели составляют 30 Гбайт, 162 Гбайт и более 10 Тбайт соответственно. Пропускная способность платы ввода/вывода, которая включает две шины SBus, 3 слота SBus, контроллер FastEthernet, контроллер Fast/Wide SCSI и два гнезда волоконно-оптических каналов, составляет 200 Мбайт/с. Подбирая необходимое количество процессорных плат и плат ввода/вывода можно практически создать любую необходимую пользователю конфигурацию системы.
Таблица 4.13. Основные характеристики корпоративных серверов компании SUN Microsystems
| МОДЕЛЬ | Enterprise 5000 | Enterprise 6000 | ||||
| ЦП | ||||||
| Тип процессора | UltraSPARC | |||||
| Тактовая частота (МГц) | 167 | 167 | 167 | 167 | 167 | 167 |
| Число процессоров | 8 | 10 | 12 | 10 | 16 | 24 |
| Размер кэша (Кб) (в процессоре/на плате) |
16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU |
| Пропускная способность системной шины (Гб/сек) |
2.5 | 2.5 | 2.5 | 2.5 | 2.5 | 2.5 |
| ПАМЯТЬ | ||||||
| Минимальный объем (Мб) | 64 | 64 | 64 | 64 | 64 | 64 |
| Максимальный объем (Гб) | 14 | 14 | 14 | 30 | 30 | 30 |
| ВВОД/ВЫВОД | ||||||
| Количество слотов | 3-21SBus | 3-21SBus | 3-21SBus | 3-45SBus | 3-45SBus | 3-45SBus |
| Максимальная пропускная способность платы в/в (Мб/сек) | 200 | 200 | 200 | 200 | 200 | 200 |
| Периферийные интерфейсы | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 |
| Максимальная емкость внутренних дисков (Гб) |
216 | 216 | 216 | 162 | 162 | 162 |
| Максимальная емкость дисковой памяти (Тб) |
6+ | 6+ | 6+ | 10+ | 10+ | 10+ |
| Сетевые интерфейсы основной/дополнительные |
10/100Мб/с Ethernet/ FDDI, ATM, TokenRing |
10/100Мб/с Ethernet/ FDDI, ATM, TokenRing |
||||
| ПРОИЗВОДИТЕЛЬНОСТЬ | ||||||
| TPC-C | - | - | 11466 | - | - | 17000 |
| $/tpmC | - | - | 191 | - | - | - |
| NFS op/sec | 10151 | 12031 | 13536 | - | 17771 | 21014 |
| SPECrate_int92 | 44670 | 55140 | 65327 | 55140 | 86520 | 127913 |
| SPECrate_fp92 | 62370 | 77190 | 91702 | 77190 | 118120 | 165385 |
| AIM III (job/minute/ users) | 12180/ 9176 | 14790/ 10666 |
18560/ 11453 | - | 23200/ 15000 | 33640/ 15000 |
Таблица 4.14. Основные характеристики серверов рабочих групп компании SUN Microsystems
| МОДЕЛЬ | SPARCserver 5 | SPARCserver 20 | |||
| Model 110 | Model 71 | Model712MP | Model151 | Model152MP | |
| ЦП | |||||
| Тип процессора | microSPARC II | SuperSPARC-II | hyperSPARC | ||
| Тактовая частота (МГц) | 110 | 75 | 75 | 150 | 150 |
| Число процессоров | 1 | 1 | 2 | 1 | 2 |
| Системная шина (бит) | 64 | 64 | 64 | 64 | 64 |
| Размер кэша (Кб) (в процессоре/на плате) |
24 | 36/1024 | 36/1024 per CPU |
8/512 per CPU |
8/512 per CPU |
| Пропускная способность системной шины (Мб/сек) | 105 | 105 | 105 | 105 | 105 |
| ПАМЯТЬ | |||||
| Минимальный объем (Мб) | 32 | 32 | 64 | 64 | 64 |
| Максимальный объем (Мб) | 256 | 512 | 512 | 512 | 512 |
| ВВОД/ВЫВОД | |||||
| Тип шины | Sbus | Sbus | Sbus | Sbus | Sbus |
| Количество слотов | 3 | 4 | 4 | 4 | 4 |
| Максимальная пропускная способность подсистемы в/в (Мб/сек) | 52 | 52 | 52 | 52 | 52 |
| Периферийные интерфейсы | SCSI-2 | SCSI-2 | SCSI-2 | SCSI-2 | SCSI-2 |
| Минимальная емкость дисковой памяти (Гб) | 4.2 | 4.2 | 4.2 | 4.2 | 4.2 |
| Максимальная емкость дисковой памяти (Гб) | 118 | 339 | 339 | 339 | 339 |
| Количество последовательных портов |
2 | 2 | 2 | 2 | 2 |
| Количество параллельных портов | 1 | 1 | 1 | 1 | 1 |
| Сетевые интерфейсы основной/дополнительные |
Ethernet/FDDI, ATM, Token Ring, FastEthernet |
Ethernet/ FDDI, ATM, Token Ring, FastEthernet |
Ethernet/ FDDI, ATM, Token Ring, FastEthernet |
Ethernet/ FDDI, ATM, Token Ring, FastEthernet |
Ethernet/ FDDI, ATM, Token Ring, FastEthernet |
| ПРОИЗВОДИТЕЛЬНОСТЬ | |||||
| Транзакция/сек | 145 | 200 | 305 | 240 | 315 |
| SPECrate_int92 | 1864 | 2984 | 5726 | 4018 | 7310 |
| SPECrate_fp92 | 1549 | 2875 | 5439 | 4938 | 8758 |
| SPECrate_base_int92 | 1630 | 2761 | 5332 | 3734 | 7004 |
| SPECrate_base_fp92 | 1494 | 2595 | 4923 | 4464 | 7945 |
Таблица 4.15. Основные характеристики серверов отделов компании Sun
Microsystems
| МОДЕЛЬ | SPARCserver 1000E | SPARCcenter 2000E | ||||
| ЦП | ||||||
| Тип процессора | SuperSPARC | |||||
| Тактовая частота (МГц) | 85 | 85 | 85 | 85 | 85 | 85 |
| Число процессоров | 2 | 4 | 8 | 2 | 12 | 20 |
| Системная шина (бит) | 64 | 64 | 64 | 64 | 64 | 64 |
| Размер кэша (Кб) (в процессоре/на плате) |
36/1024 per CPU | 36/1024 per CPU | 36/1024 per CPU | 36/2048 per CPU | 36/2048 per CPU | 36/2048 per CPU |
| Пропускная способность системной шины (Мб/сек) | 250 | 250 | 250 | 500 | 500 | 500 |
| ПАМЯТЬ | ||||||
| Минимальный объем (Мб) | 32 | 64 | 64 | 64 | 64 | 64 |
| Максимальный объем (Мб) | 2048 | 2048 | 2048 | 5120 | 5120 | 5120 |
| ВВОД/ВЫВОД | ||||||
| Тип шины | Sbus | Sbus | Sbus | Sbus | Sbus | Sbus |
| Количество слотов | 3-12 | 3-12 | 3-12 | 4-40 | 4-40 | 4-40 |
| Максимальная пропускная способность подсистемы в/в (Мб/сек) | 90 | 90 | 90 | 180 | 180 | 180 |
| Периферийные интерфейсы |
SCSI-2 | SCSI-2 | SCSI-2 | SCSI-2 | SCSI-2 | SCSI-2 |
| Стандартная емкость дисковой памяти (Мб) |
1050, 2100 |
1050, 2100 |
1050, 2100 |
1050, 2100 |
1050, 2100 |
1050, 2100 |
| Максимальная емкость дисковой памяти (Гб) | 764 | 764 | 764 | 4860 | 4860 | 4860 |
| Количество последовательных портов |
2-8 | 2-8 | 2-8 | 2-10 | 2-10 | 2-10 |
| Сетевые интерфейсы основной/дополнительные |
Ethernet/ FDDI,ATM, TokenRing, FastEthernet | Ethernet/ FDDI,ATM, TokenRing, FastEthernet |
||||
| ПРОИЗВОДИТЕЛЬНОСТЬ | ||||||
| Транзакция/сек | - | - | 10400 | - | - | 27440 |
| NFS op/sec | - | - | 3950 | 1750 | 5950 | 6700 |
| SPECrate_int92 | 5988 | 11508 | 21758 | 6546 | 35332 | 57997 |
| SPECrate_fp92 | 5805 | 11322 | 20851 | 6284 | 35948 | 54206 |
| SPECrate_base_int92 | 5480 | 10557 | 20225 | 5875 | 33067 | 53714 |
| SPECrate_base_fp92 | 5232 | 9943 | 18741 | 5742 | 32531 | 51489 |
| AIM III (job/minute/ users) | 2037/ | 3654/ | 6062/ | 2237/ | 9637/ | 12104/ |
| 1849 | 3327 | 5386 | 2028 | 8004 | 9436 |
Таблица 4.15. (Продолжение). Основные характеристики серверов отделов
компании Sun Microsystems
| МОДЕЛЬ | Enterprise 3000 | Enterprise 4000 | ||||
| ЦП | ||||||
| Тип процессора | UltraSPARC | |||||
| Тактовая частота (МГц) | 167 | 167 | 167 | 167 | 167 | 167 |
| Число процессоров | 2 | 4 | 6 | 8 | 10 | 12 |
| Размер кэша (Кб) (в процессоре/на плате) |
16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU | 16+16/512 per CPU |
| Пропускная способность системной шины (Гб/сек) |
2.5 | 2.5 | 2.5 | 2.5 | 2.5 | 2.5 |
| ПАМЯТЬ | ||||||
| Минимальный объем (Мб) | 64 | 64 | 64 | 64 | 64 | 64 |
| Максимальный объем (Гб) | 6 | 6 | 6 | 12 | 12 | 12 |
| ВВОД/ВЫВОД | ||||||
| Количество слотов | 3-9SBus | 3-9SBus | 3-9SBus | 3-21SBus | 3-21SBus | 3-21SBus |
| Максимальная пропускная способность платы в/в (Мб/сек) |
200 | 200 | 200 | 200 | 200 | 200 |
| Периферийные интерфейсы | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 | F&WSCSI2 |
| Максимальная емкость внутренних дисков (Гб) |
42 | 42 | 42 | 16.8 | 16.8 | 16.8 |
| Максимальная емкость дисковой памяти (Тб) | 2+ | 2+ | 2+ | 4+ | 4+ | 4+ |
| Сетевые интерфейсы основной/дополнительные |
10/100Мб/с Ethernet/ FDDI, ATM, TokenRing |
10/100Мб/с Ethernet/ FDDI, ATM, TokenRing |
||||
| ПРОИЗВОДИТЕЛЬНОСТЬ | ||||||
| TPC-C | - | - | - | - | - | 11466 |
| $/tpmC | - | - | - | - | - | 189 |
| NFS op/sec | 3629 | 6113 | 8103 | 10151 | 12031 | 13536 |
| SPECrate_int92 | 11550 | 22850 | 34817 | 44670 | 55140 | 65327 |
| SPECrate_fp92 | 16170 | 31920 | 46309 | 62370 | 77190 | 91702 |
| AIM III (job/minute/ users) | 2982/ | 6090/ | 9280/ | 12180/ | 14790/ | 18560/ |
| 2632 | 5022 | 7440 | 9176 | 10666 | 11453 |
UltraSPARCI
Процессор UltraSPARC-1 представляет собой высокопроизводительный, высокоинтегрированной суперскалярный процессор, реализующий 64-битовую архитектуру SPARC-V9. В его состав входят: устройство предварительной выборки и диспетчеризации команд, целочисленное исполнительное устройство, устройство плавающей точки с графическим устройством, устройство управления памятью, устройство загрузки/записи, устройство управления внешней кэш-памятью, устройство управления интерфейсом памяти и кэш-памяти команд и данных (рисунок 5.7).
Управление интерфейсом памяти (MIU)
В процессоре UltraSPARC-1 применяется специальная подсистема ввода/вывода (MIU), которая обеспечивает управление всеми операциями ввода и вывода, которые осуществляются между локальными ресурсами: процессором, основной памятью, схемами управления и всеми внешними ресурсами системы. В частности, все системные транзакции, связанные с обработкой промахов кэш-памяти, прерываниями, наблюдением за когерентным состоянием кэш-памяти, операциями обратной записи и т.д., обрабатываются MIU. MIU взаимодействует с системой на частоте меньшей, чем частота UltraSPARC-1 в соотношении 1/2, или 1/3.
Управление командами плавающей точки
Конвейер целочисленного устройства включает шесть ступеней: Чтение из кэша команд (IR), Чтение операндов (OR), Выполнение/Чтение из кэша данных (DR), Завершение чтения кэша данных (DRC), Запись в регистры (RW) и Запись в кэш данных (DW). На ступени ID выполняется выборка команд. Реализация механизма выдачи двух команд требует небольшого буфера предварительной выборки, который обеспечивает предварительную выборку команд за два такта до начала работы ступени IR. Во время выполнения на ступени OR все исполнительные устройства декодируют поля операндов в команде и начинают вычислять результат операции. На ступени DR целочисленное устройство завершает свою работу. Кроме того, кэш-память данных выполняет чтение, но данные не поступают до момента завершения работы ступени DRC. Результаты операций сложения (ADD) и умножения (MULTIPLY) также становятся достоверными в конце ступени DRC. Запись в универсальные регистры и регистры плавающей точки производится на ступени RW. Запись в кэш данных командами записи (STORE) требует двух тактов. Наиболее раннее двухтактное окно команды STORE возникает на ступенях RW и DW. Однако это окно может сдвигаться, поскольку записи в кэш данных происходят только когда появляется следующая команда записи. Операции деления и вычисления квадратного корня для чисел с плавающей точкой заканчиваются на много тактов позже ступени DW.
Конвейер проектировался с целью максимального увеличения времени, необходимого для выполнения чтения внешних кристаллов SRAM кэш-памяти данных. Это позволяет максимизировать частоту процессора при заданной скорости SRAM. Все команды загрузки (LOAD) выполняются за один такт и требуют только одного такта полосы пропускания кэш-памяти данных. Поскольку кэши команд и данных размещены на разных шинах, в конвейере отсутствуют какие-либо потери, связанные с конфликтами по обращениям в кэш данных и кэш команд.
Процессор может в каждом такте выдавать на выполнение одну целочисленную команду и одну команду плавающей точки. Полоса пропускания кэша команд достаточна для поддержания непрерывной выдачи двух команд в каждом такте. Отсутствуют какие-либо ограничения по выравниванию или порядку следования пары команд, которые выполняются вместе. Кроме того, отсутствуют потери тактов, связанных с переключением с выполнения двух команд на выполнение одной команды. Специальное внимание было уделено тому, чтобы выдача двух команд в одном такте не приводила к ограничению тактовой частоты. Чтобы добиться этого, в кэше команд был реализован специально предназначенный для этого заранее декодируемый бит, чтобы отделить команды целочисленного устройства от команд устройства плавающей точки. Этот бит предварительного декодирования команд минимизирует время, необходимое для правильного разделения команд.
Потери, связанные с зависимостями по данным и управлению, в этом конвейере минимальны. Команды загрузки выполняются за один такт, за исключением случая, когда последующая команда пользуется регистром-приемником команды LOAD. Как правило компилятор позволяет обойти подобные потери одного такта. Для уменьшения потерь, связанных с командами условного перехода, в процессоре используется алгоритм прогнозирования направления передачи управления. Для оптимизации производительности циклов передачи управления вперед по программе прогнозируются как невыполняемые переходы, а передачи управления назад по программе - как выполняемые переходы. Правильно спрогнозированные условные переходы выполняются за один такт.
Количество тактов, необходимое для записи слова или двойного слова командой STORE уменьшено с трех до двух тактов. В более ранних реализациях архитектуры PA-RISC был необходим один дополнительный такт для чтения тега кэша, чтобы гарантировать попадание, а также для того, чтобы объединить старые данные строки кэш-памяти данных с записываемыми данными. PA 7100 использует отдельную шину адресного тега, чтобы совместить по времени чтение тега с записью данных предыдущей команды STORE. Кроме того, наличие отдельных сигналов разрешения записи для каждого слова строки кэш-памяти устраняет необходимость объединения старых данных с новыми, поступающими при выполнении команд записи слова или двойного слова. Этот алгоритм требует, чтобы запись в микросхемы SRAM происходила только после того, когда будет определено, что данная запись сопровождается попаданием в кэш и не вызывает прерывания. Это требует дополнительной ступени конвейера между чтением тега и записью данных. Такая конвейеризация не приводит к дополнительным потерям тактов, поскольку в процессоре реализованы специальные цепи обхода, позволяющие направить отложенные данные команды записи последующим командам загрузки или командам STORE, записывающим только часть слова. Для данного процессора потери конвейера для команд записи слова или двойного слова сведены к нулю, если непосредственно последующая команда не является командой загрузки или записи. В противном случае потери равны одному такту. Потери на запись части слова могут составлять от нуля до двух тактов. Моделирование показывает, что подавляющее большинство команд записи в действительности работают с однословным или двухсловным форматом.
Все операции с плавающей точкой, за исключением команд деления и вычисления квадратного корня, полностью конвейеризованы и имеют двухтактную задержку выполнения как в режиме с одинарной, так и с двойной точностью. Процессор может выдавать на выполнение независимые команды с плавающей точкой в каждом такте при отсутствии каких-либо потерь. Последовательные операции с зависимостями по регистрам приводят к потере одного такта. Команды деления и вычисления квадратного корня выполняются за 8 тактов при одиночной и за 15 тактов при двойной точности. Выполнение команд не останавливается из-за команд деления/вычисления квадратного корня до тех пор, пока не потребуется регистр результата или не будет выдаваться следующая команда деления/вычисления квадратного корня.
Процессор может выполнять параллельно одну целочисленную команду и одну команду с плавающей точкой. При этом "целочисленными командами" считаются и команды загрузки и записи регистров плавающей точки, а "команды плавающей точки" включают команды FMPYADD и FMPYSUB. Эти последние команды объединяют операцию умножения с операциями сложения или вычитания соответственно, которые выполняются параллельно. Пиковая производительность составляет 200 MFLOPS для последовательности команд FMPYADD, в которых смежные команды независимы по регистрам.
Потери для операций плавающей точки, использующих предварительную загрузку операнда командой LOAD, составляют один такт, если команды загрузки и плавающей арифметики являются смежными, и два такта, если они выдаются для выполнения одновременно. Для команды записи, использующей результат операции с плавающей точкой, потери отсутствуют, даже если они выполняются параллельно.
Потери, возникающие при промахах в кэше данных, минимизируются посредством применения четырех разных методов: "попадание при промахе" для команд LOAD и STORE, потоковый режим работы с кэшем данных, специальная кодировка команд записи, позволяющая избежать копирования строки, в которой произошел промах, и семафорные операции в кэш-памяти. Первое свойство позволяет во время обработки промаха в кэше данных выполнять любые типы других команд. Для промахов, возникающих при выполнении команды LOAD, обработка последующих команд может продолжаться до тех пор, пока регистр результата команды LOAD не потребуется в качестве регистра операнда для другой команды. Компилятор может использовать это свойство для предварительной выборки в кэш необходимых данных задолго до того момента, когда они действительно потребуются. Для промахов, возникающих при выполнении команды STORE, обработка последующих команд загрузки или операций записи в части одного слова продолжается до тех пор, пока не возникает обращений к строке, в которой произошел промах. Компилятор может использовать это свойство для выполнения команд на фоне записи результатов предыдущих вычислений. Во время задержки, связанной с обработкой промаха, другие команды LOAD и STORE, для которых происходит попадание в кэш данных, могут выполняться как и другие команды целочисленной арифметики и плавающей точки. В течение всего времени обработки промаха команды STORE, другие команды записи в ту же строку кэш-памяти могут происходить без дополнительных потерь времени. Для каждого слова в строке кэш-памяти процессор имеет специальный индикационный бит, предотвращающий копирование из памяти тех слов строки, которые были записаны командами STORE. Эта возможность применяется к целочисленным и плавающим операциям LOAD и STORE.
Выполнение команд останавливается, когда регистр-приемник команды LOAD, выполняющейся с промахом, требуется в качестве операнда другой команды. Свойство "потоковости" позволяет продолжить выполнение как только нужное слово или двойное слово возвращается из памяти. Таким образом, выполнение команд может продолжаться как во время задержки, связанной с обработкой промаха, так и во время заполнения соответствующей строки при промахе.
При выполнении блочного копирования данных в ряде случаев компилятор заранее знает, что запись должна осуществляться в полную строку кэш-памяти. Для оптимизации обработки таких ситуаций архитектура PA-RISC 1.1 определяет специальную кодировку команд записи ("блочное копирование"), которая показывает, что аппаратуре не нужно осуществлять выборку из памяти строки, при обращении к которой может произойти промах кэш-памяти. В этом случае время обращения к кэшу данных складывается из времени, которое требуется для копирования в память старой строки кэш-памяти по тому же адресу в кэше (если он "грязный") и времени, необходимого для записи нового тега кэша. В процессоре PA 7100 такая возможность реализована как для привилегированных, так и для непривилегированных команд.
Последнее улучшение управления кэшем данных связано с реализацией семафорных операций "загрузки с обнулением" непосредственно в кэш-памяти. Если семафорная операция выполняется в кэше, то потери времени при ее выполнении не превышают потерь обычных операций записи. Это не только сокращает конвейерные потери, но и снижает трафик шины памяти. В архитектуре PA-RISC 1.1 предусмотрен также другой тип специального кодирования команд, который устраняет требование синхронизации семафорных операций с устройствами ввода/вывода.
Управление кэш-памятью команд позволяет при промахе продолжить выполнение команд сразу же после поступления отсутствующей в кэше команды из памяти. 64-битовая магистраль данных, используемая для заполнения блоков кэша команд, соответствует максимальной полосе пропускания внешней шины памяти 400 Мбайт/с при тактовой частоте 100 МГц.
В процессоре предусмотрен также ряд мер по минимизации потерь, связанных с преобразованиями виртуальных адресов в физические.
Конструкция процессора обеспечивает реализацию двух способов построения многопроцессорных систем. При первом способе каждый процессор подсоединяется к интерфейсному кристаллу, который наблюдает за всеми транзакциями на шине основной памяти. В такой системе все функции по поддержанию когерентного состояния кэш-памяти возложены на интерфейсный кристалл, который посылает процессору соответствующие транзакции. Кэш данных построен на принципах отложенного обратного копирования и для каждого блока кэш-памяти поддерживаются биты состояния "частный" (private), "грязный" (dirty) и "достоверный" (valid), значения которых меняются в соответствии с транзакциями, которые выдает или принимает процессор.
Второй способ организации многопроцессорной системы позволяет объединить два процессора и контроллер памяти и ввода-вывода на одной и той же локальной шине памяти. В такой конфигурации не требуется дополнительных интерфейсных кристаллов и она совместима с существующей системой памяти. Когерентность кэш-памяти обеспечивается наблюдением за локальной шиной памяти. Пересылки строк между кэшами выполняются без участия контроллера памяти и ввода-вывода. Такая конфигурация обеспечивает возможность построения очень дешевых высокопроизводительных многопроцессорных систем.
Процессор поддерживает ряд операций, необходимых для улучшения графической производительности рабочих станций серии 700: блочные пересылки, Z-буферизацию, интерполяцию цветов и команды пересылки данных с плавающей точкой для обмена с пространством ввода/вывода.
Процессор построен на базе технологического процесса КМОП с проектными нормами 0.8 микрон, что обеспечивает тактовую частоту 100 МГц.
Управление внешней кэшпамятью (Eкэшем)
Одной из важнейших проблем построения системы является согласование производительности процессора со скоростью основной памяти. Основными методами решения этой проблемы (помимо различных способов организации основной памяти и системы межсоединений) являются увеличение размеров и многоуровневая организация кэш-памяти. Устройство управления внешней кэш-памятью (ECU) процессора UltraSPARC-1 позволяет эффективно обрабатывать промахи кэш-памяти данных (D-кэша) и команд (Е-кэша). Все обращения к внешней кэш-памяти (E-кэшу) конвейеризованы, выполняются за 3 такта и осуществляют пересылку 16 байт команд или данных в каждом такте. Такая организация дает возможность эффективно планировать конвейерное выполнение программного кода, содержащего большой объем обрабатываемых данных, и минимизировать потери производительности, связанные с обработкой промахов в D-кэше. ECU позволяет наращивать объем внешней кэш-памяти от 512 Кбайт до 4 Мбайт.
ECU обеспечивает совмещенную во времени обработку промахов обращений по чтению данных из Е-кэша с операциями записи. Например, во время обработки промаха по загрузке ECU разрешает поступление запросов по записи данных в E-кэш. Кроме того, ECU поддерживает операции наблюдения (snoops), связанные с обеспечением когерентного состояния памяти системы.
Упрощенная блок схема процессора Pentium
В настоящее время компания Intel разработала и выпустила новый процессор, продолжающий архитектурную линию x86. Этот процессор получил название P6 или PentiumPro. Он работает с тактовыми частотами 150: 166: 180 и 200 МГц. PentiumPro обеспечивает полную совместимость с процессорами предыдущих поколений. Он предназначен главным образом для поддержки высокопроизводительных 32-битовых вычислений в области САПР, трехмерной графики и мультимедиа: а также широкого круга коммерческих приложений баз данных. По результатам испытаний на тестах SPEC (8.58 SPECint95 и 6.48 SPECfp95) процессор PentiumPro по производительности целочисленных операций в текущий момент времени вышел на третье место в мировой классификации, уступая только 180 МГц HP PA-8000 и 400 МГц DEC Alpha (см. Рисунок 5.2). Для достижения такой производительности необходимо использование технических решений, широко применяющихся при построении RISC-процессоров:
выполнение команд не в предписанной программой последовательности, что устраняет во многих случаях приостановку конвейеров из-за ожидания операндов операций; использование методики переименования регистров, позволяющей увеличивать эффективный размер регистрового файла (малое количество регистров - одно из самых узких мест архитектуры x86); расширение суперскалярных возможностей по отношению к процессору Pentium, в котором обеспечивается одновременная выдача только двух команд с достаточно жесткими ограничениями на их комбинации.Упрощенная блоксхема отображения целочисленных команд
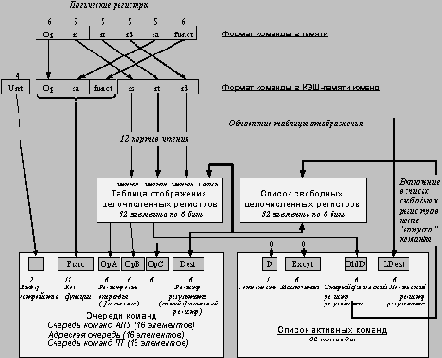
Когда в процессе переименования из списка свободных регистров выбирается очередной номер физического регистра, он передается в таблицу отображения, которая обновляется. При этом старый номер регистра, соответствующий определенному в команде логическому регистру результата, помещается из таблицы отображения в список активных команд. Этот номер остается в списке активных команд до тех пор, пока соответствующая команда не "выпустится" (graduate), т.е. завершится в заданном программой порядке. Команда может "выпуститься" только после того, как успешно завершится выполнение всех предыдущих команд.
Микропроцессор R10000 содержит 64 физических и 32 логических целочисленных регистра. Список активных команд может содержать максимально 32 элемента. Список свободных регистров также может максимально содержать 32 значения. Если список активных команд полон, то могут быть 32 "зафиксированных" и 32 временных значения. Отсюда потребность в 64 регистрах.
Устройства архивирования информации
В качестве носителя для резервного копирования информации обычно используется магнитная лента. Резервное копирование предполагает использование различных стратегий и различных конфигураций оборудования в зависимости от требований пользователя. При планировании и создании системы этим вопросам приходится уделять большое внимание, так как обычно требования к системе резервного копирования выходят далеко за рамки простого обеспечения емкости носителя, превышающей емкость дисковой памяти системы, или выбора скорости операций копирования на магнитную ленту. Среди этих вопросов следует выделить, например, такие как определение количества клиентов, копирование данных которых должно осуществляться одновременно; цикличность операций копирования, т.е. по каким дням и в какие часы такое копирование должно осуществляться, а также уровень копирования (полное, частичное или смешанное); определение устройств на которых должно выполняться резервное копирование и т.д.
В настоящее время в большинстве систем накопители на магнитных лентах (НМЛ) обычно подсоединяются к компьютеру с помощью шины SCSI. Очень часто к этой же шине подсоединяются и дисковые накопители. К сожалению, высокий коэффициент использования шины SCSI практически всеми применяемыми в настоящее время типами НМЛ становится критическим фактором при организации резервного копирования и восстановления информации особенно в больших серверах с высокой степенью готовности. В таблице 5.1 приведены типичные параметры НМЛ. Очевидно такая высокая загрузка шины SCSI (до 20 - 65 % пропускной способности шины) при работе НМЛ накладывает определенные ограничения как на конфигурацию и типы применяемых НМЛ, так и на организацию самого резервного копирования.
Таблица 3.1
| Тип НДЛ | Емкость | Скорость передачи данных |
Скорость пересылки по шине |
Коэффициент использования шины SCSI |
| 4 мм 8 мм 8 мм 1/2" 9 дор. 1/4" QIC |
5 Гб 2.3 Гб 5 Гб 120 Мб 150 Мб |
920 Кб/c 220 Кб/c 500 Кб/c 780 Кб/c 200 Кб/c |
5 Мб/с (синх.) 1.2 Мб/с (асинх.) 3 Мб/с (асинх.) 1.2 Мб/с (асинх.) 1.0 Мб/с (асинх.) |
25 % 25 % 20 % 65-75 % 28 % |
Наиболее популярным в настоящее время являются НМЛ с 8 и 4 мм цифровой аудио- лентой (DAT), использующие технологию спирального сканирования. В отличие от традиционных НМЛ со стационарными головками и ограниченным числом дорожек, эти устройства осуществляют чтение и запись данных на медленно двигающуюся магнитную ленту с помощью головок, размещаемых на быстро вращающемся барабане. При этом дорожки пересекают ленту с края на край и расположены под небольшим углом к направлению, перпендикулярному направлению движения ленты. Иногда эту технологию называют "поперечной записью". На сегодняшний день подобные устройства дают наивысшую поверхностную плотность записи. Например, накопитель EXB-8200 компании Exabyte Corp. позволяет записывать около 35 мегабит на квадратный дюйм 8 мм ленты, а накопитель EXB-8500 - около 75 мегабит на квадратный дюйм. Устройства DAT записывают данные на 4 мм ленту с плотностью 114 мегабит на дюйм, что близко к теоретическому пределу плотности записи. Дальнейшее ее увеличение требует смены типа носителя или использования технологии компрессии (сжатия) данных.
На сегодняшний день продолжают использоваться и старые типы катушечных НМЛ, которые используют стандартную магнитную ленту шириной 0.5 дюйма. Они главным образом применяются для обмена информацией со старыми ЭВМ и поддерживают плотность записи 6250, 1600 и 800 бит на дюйм.
Наиболее популярными в течение многих лет были 150-250 Мб картриджи QIC с лентой шириной 1/4 дюйма. В настоящее время существует 10 производственных стандартов для картриджей конструктива 5.25" и 9 стандартов мини-картриджей конструктива 3.5". В мае 1994 года появился новый формат для записи 2 Гбайт (без сжатия) на микрокартридже QIC-153 c барий-ферритовой лентой длиной 400 футов. QIC-картриджи вмещают до 1200 футов магнитной ленты, при этом данные записываются на дорожках, расположенных вдоль ленты. Число дорожек может достигать 48. В зависимости от формата (QIC-40, QIC-80, QIC-3GB(M) и т.д.) мини-картриджи имеют емкость (без сжатия) от 40 Мбайт до 3 и более Гбайт. Картриджи наибольшей емкости позволяют записать до 13 Гбайт данных. В настоящее время наблюдается рост числа накопителей QIC с картриджами емкостью до 5 Гбайт и форматом записи 5GB(M). В 1995 году ожидалось появление накопителей QIC формата 25 Мбайт с постоянной скоростью передачи 2.4 Мбайт/с. Такие системы составят серьезную конкуренцию 8 мм накопителям типа Exabyte, которые сейчас доминируют на рынке систем хранения большой емкости.
Одним из сравнительно новых направлений в области резервного копирования является появление устройств ленточных массивов (аналогичных дисковым массивам), используемых главным образом в системах высокой готовности. Примером такого устройства может служить CLARiiON Series 4000 tape array компании Data General. Оно может иметь в своем составе до пяти 4 мм DAT накопителей общей емкостью до 25 Гбайт. Устройство относится к разряду открытых систем и совместимо со всеми UNIX-платформами компаний IBM, Sun, Hewlett-Packard, Unisys и ICL.
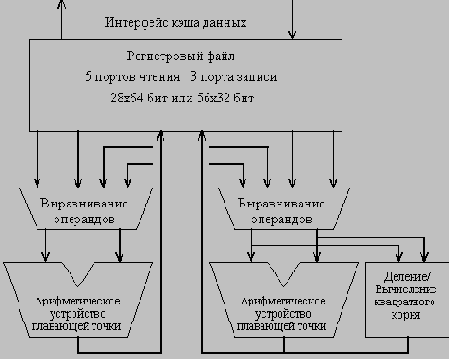
Устройства плавающей точки
В микропроцессоре R10000 реализованы два основных устройства плавающей точки. Устройство сложения обрабатывает операции сложения, а устройство умножения - операции умножения. Кроме того, существуют два вторичных устройства плавающей точки, которые обрабатывают длинные операции деления и вычисления квадратного корня.
Время выполнения команд сложения, вычитания и преобразования типов равно двум тактам, а скорость их поступления в устройство составляет 1 команда/такт. Эти команды обрабатываются в устройстве сложения. Команды преобразования целочисленных значений в значения с плавающей точкой с однократной точностью имеют задержку в 4 такта, поскольку они должны пройти через устройство сложения дважды.
В устройстве умножения обрабатываются все операции умножения с плавающей точкой. Время их выполнения составляет два такта, а скорость поступления - 1 команда/такт. Устройства деления и вычисления квадратного корня выполняют операции с использованием итерационных алгоритмов. Эти устройства не конвейеризованы и не могут начать выполнение следующей операции до тех пор, пока не завершилось выполнение текущей команды. Таким образом, скорость повторения этих операций примерно равна задержке их выполнения. Порты умножителя являются общими и для устройств деления и вычисления квадратного корня. В начале и в конце операции теряется по одному такту (для выборки операндов и для записи результата).
Операция с плавающей точкой "умножить-сложить", которая в вычислительных программах возникает достаточно часто, выполняется с использованием двух отдельных операций: операции умножения и операции сложения. Команда "умножить-сложить" (MADD) имеет задержку 4 такта и скорость повторения 1 команда/ такт. Эта составная команда увеличивает производительность за счет устранения выборки и декодирования дополнительной команды.
Устройства деления и вычисления квадратного корня используют раздельные цепи и могут работать одновременно. Однако очередь команд плавающей точки не может выдать для выполнения обе команды в одном и том же такте.
Устройство плавающей точки (FPU)
В процессоре UltraSPARC-1 реализован исчерпывающий набор графических команд, которые обеспечивают аппаратную поддержку высокоскоростной обработки двухмерных и трехмерных изображений, обработку видеоданных и т.д. GRU выполняет операции сложения, сравнения и логические операции над 16-битовыми и 32-битовыми целыми числами, а также операции умножения над 8-битовыми и 16-битовыми целыми. В GRU поддерживаются однотактные операции определения расстояния между пикселами, операции выравнивания данных, операции упаковки и слияния.
Устройство управления памятью (MMU)
Высокая суперскалярная производительность процессора поддерживается высокой скоростью поступления для обработки команд и данных. Обычно эта задача ложится на иерархию памяти системы. Устройство управления памятью процессора UltraSPARC-1 выполняет все операции обращения к памяти, реализуя необходимые средства поддержки виртуальной памяти. Виртуальное адресное пространство задачи определяется 64-битовым виртуальным адресом, однако процессор UltraSPARC-1 поддерживает только 44-битовое виртуальное адресное пространство. Соответствующее преобразование является функцией операционной системы.
В свою очередь MMU обеспечивает отображение 44-битового виртуального адреса в 41-битовый физический адрес памяти. Это преобразование выполняется с помощью полностью ассоциативных 64-строчных буферов: iTLB - для команд и dTLB - для данных. Каждый из этих буферов по существу представляет собой полностью ассоциативную кэш-память дескрипторов страниц. В каждой строке TLB хранится информация о виртуальном адресе страницы, соответствующем физическом адресе страницы, а также о допустимом режиме доступа к странице и ее использовании. Процесс преобразования виртуального адреса в физический заканчивается сразу, если при поиске в кэш-памяти TLB происходит попадание (соответствующая строка находится в TLB). В противном случае замещение строки TLB осуществляется специальным аппаратно-программным механизмом. MMU поддерживает четыре размера страниц: 8K, 64K, 512K и 4Мбайт.
Как уже было отмечено, MMU реализует также механизмы защиты и контроля доступа к памяти. В результате выполняющийся процесс не может иметь доступ к адресному пространству других процессов, и кроме того, гарантируется заданный режим доступа процесса к определенным областям памяти (на базе информации о допустимом режиме доступа к страницам памяти). Например, процесс не может модифицировать страницы памяти, доступ к которым разрешен только по чтению, или которые зарезервированы для размещения системных программ и т.д.
Наконец, MMU выполняет функции определения порядка (приоритет) обращений к памяти со стороны ввода/вывода, D-кэша, I-кэша и схем преобразования виртуального адреса в физический.
Устройство загрузки/записи и TLB
Внешняя кэш-память второго уровня управляется с помощью внутреннего контроллера, который имеет специальный порт для подсоединения кэш-памяти. Специальная магистраль данных шириной в 128 бит осуществляет пересылки данных на внутренней тактовой частоте процессора 200 МГц, обеспечивая максимальную скорость передачи данных кэш-памяти второго уровня 3.2 Гбайт/с. В процессоре имеется также 64-битовая шина данных системного интерфейса.
Кэш-память второго уровня имеет двухканальную множественно-ассоциативную организацию. Максимальный размер этой кэш-памяти - 16 Мбайт. Минимальный размер - 512 Кбайт. Пересылки осуществляются 128-битовыми порциями (4 32-битовых слова). Для пересылки больших блоков данных используются последовательные циклы шины:
Четырехсловные обращения (128 бит) используются для команд кэш-памяти (CASHE); Восьмисловные обращения (256 бит) используются для перезагрузки первичного кэша данных; Шестнадцатисловные обращения (512 бит) используются для перезагрузки первичного кэша команд; Тридцатидвухсловные обращения (1024 бит) используются для перезагрузки кэш-памяти второго уровня.Утилиты резервного копирования
При использовании "чистых" дисковых разделов, выбор прост: в действительности единственными командами UNIX, работающими с "чистыми" разделами, являются dd и
compress. При хранении таблиц СУБД в файловых системах USF можно выбрать, например, команды tar, cpio и usfdump. Большинство пользователей предпочитают usfdump(1) (dump(1) для Solaris 1.X), или ее эквивалент в Online Backup (hsmdump для Solaris 2.X). Большинство СУБД имеют утилиты для выделения из базы данных "чистых" данных и их копирования на внешний носитель, но эти операции обычно выполняются намного медленнее, чем простое копирование "чистых" разделов диска.
Увеличение производительности кэшпамяти
Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом:
Среднее время доступа = Время обращения при попадании + Доля промахов x Потери при промахе
Эта формула наглядно показывает пути оптимизации работы кэш-памяти: сокращение доли промахов, сокращение потерь при промахе, а также сокращение времени обращения к кэш-памяти при попадании. Ниже на рисунке 3.23 кратко представлены различные методы, которые используются в настоящее время для увеличения производительности кэш-памяти. Использование тех или иных методов определяется прежде всего целью разработки, при этом конструкторы современных компьютеров заботятся о том, чтобы система оказалась сбалансированной по всем параметрам.
| Метод | Доля промахов |
Потери при промахе |
Время обращения при попадании | Сложность аппаратуры | Примечания |
| Увеличение размера блока | + | - | 0 | ||
| Повышение степени ассоциативности | + | - | 1 | ||
| Кэш-память с вспомогательным кэшем | + | 2 | |||
| Псевдоассоциативные кэши | + | 2 | |||
| Аппаратная предварительная выборка команд и данных | + | 2 | Предварительная выборка данных затруднена | ||
| Предварительная выборка под управлением компилятора | + | 3 | Требует также неблокируемой кэш-памяти | ||
| Специальные методы для уменьшения промахов | + | 0 | Вопрос ПО | ||
| Установка приоритетов промахов по чтению над записями | + | 1 | Просто для однопроцессорных систем | ||
| Использование подблоков | + | + | 1 | Сквозная запись + подблок на 1 слово помогают записям | |
| Пересылка требуемого слова первым | + | 2 | |||
| Неблокируемые кэши | + | 3 | |||
| Кэши второго уровня | + | 2 | Достаточно дорогое оборудование | ||
| Простые кэши малого размера | - | + | 0 | ||
| Обход преобразования адресов во время индексации кэш-памяти | + | 2 | |||
| Конвейеризация операций записи для быстрого попадания при записи | + | 1 |
Увеличение разрядности основной памяти
Кэш-память первого уровня во многих случаях имеет физическую ширину шин данных соответствующую количеству разрядов в слове, поскольку большинство компьютеров выполняют обращения именно к этой единице информации. В системах без кэш-памяти второго уровня ширина шин данных основной памяти часто соответствует ширине шин данных кэш-памяти. Удвоение или учетверение ширины шин кэш-памяти и основной памяти удваивает или учетверяет соответственно полосу пропускания системы памяти.
Реализация более широких шин вызывает необходимость мультиплексирования данных между кэш-памятью и процессором, поскольку основной единицей обработки данных в процессоре все еще остается слово. Эти мультиплексоры оказываются на критическом пути поступления информации в процессор. Кэш-память второго уровня несколько смягчает эту проблему, т.к. в этом случае мультиплексоры могут располагаться между двумя уровнями кэш-памяти, т.е. вносимая ими задержка не столь критична. Другая проблема, связанная с увеличением разрядности памяти, определяется необходимостью определения минимального объема (инкремента) для поэтапного расширения памяти, которое часто выполняется самими пользователями на месте эксплуатации системы. Удвоение или учетверение ширины памяти приводит к удвоению или учетверению этого минимального инкремента. Наконец, имеются проблемы и с организацией коррекции ошибок в системах с широкой памятью.
Примером организации широкой основной памяти является система Alpha AXP 21064, в которой кэш второго уровня, шина памяти и сама память имеют разрядность в 256 бит.
Вертикальная когерентность кэшей
Каждый процессор для своей работы использует двухуровневый кэш со свойствами охвата. Это означает, что кроме внутреннего кэша первого уровня (кэша L1), встроенного в каждый процессор PowerPC, имеется связанный с ним кэш второго уровня (кэш L2). При этом каждая строка в кэше L1 имеется также и в кэше L2. В настоящее время объем кэша L2 составляет 1 Мбайт на каждый процессор, а в будущих реализациях предполагается его расширение до 4 Мбайт. Сама по себе кэш-память второго уровня позволяет существенно уменьшить число обращений к памяти и увеличить степень локализации данных. Для повышения быстродействия кэш L2 построен на принципах прямого отображения. Длина строки равна 32 байт (размеру когерентной гранулированности системы). Следует отметить, что, хотя с точки зрения физической реализации процессора PowerPC, 32 байта составляют только половину строки кэша L1, это не меняет протокол когерентности, который управляет операциями кэша L1 и гарантирует что кэш L2 всегда содержит данные кэша L1.
Кэш L2 имеет внешний набор тегов. Таким образом, любая активность механизма наблюдения за когерентным состоянием кэш-памяти может быть связана с кэшем второго уровня, в то время как большинство обращений со стороны процессора могут обрабатываться первичным кэшем. Если механизм наблюдения обнаруживает попадание в кэш второго уровня, то он должен выполнить арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Поэтому глобальная память может работать на уровне тегов кэша L2, что позволяет существенно ограничить количество операций наблюдения, генерируемых системой в направлении данного процессора. Это, в свою очередь, существенно увеличивает производительность системы, поскольку любая операция наблюдения в направлении процессора сама по себе может приводить к приостановке его работы.
Вопросы балансировки нагрузки
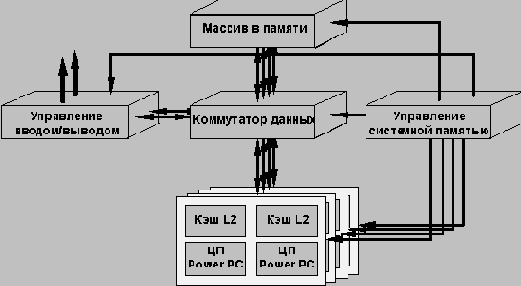
Вопросы производительности
Помимо достижения определенной гибкости за счет использования TP-мониторов, такая организация оказывается выгодной и с точки зрения увеличения производительности системы. TP-монитор всегда представляет собой многопотоковую программу. Поскольку TP-монитор открывает свое собственное соединение с СУБД, одновременно устраняя необходимость выполнения каждым прикладным процессом прямых запросов к СУБД, число одновременно работающих пользователей СУБД существенно сокращается. В подавляющем большинстве случаев СУБД обслуживает только одного "пользователя" -
TP-монитор. Это особенно важно, когда СУБД относится к классу "2N", поскольку в этом случае используется только один теневой процесс (для обеспечения соединения с TP-монитором), а не по одному процессу на каждый процесс конечного пользователя (Рисунок 2.4). Это может существенно сократить накладные расходы, связанные с переключением контекста на сервере СУБД.
Возможности масштабирования системы
ServerNet обеспечивает широкие возможности для масштабирования системы. Обычно расширение выполняется с помощью встроенных кабельных соединений, а также установки в гнезда расширения ServerNet плат маршрутизаторов. Кроме того, добавление каждого ЦП обеспечивает увеличение числа линий связи ServerNet и эффективно расширяет общую пропускную способность в/в системы. В отличие от других массивно-параллельных архитектур сети ServerNet не ограничены только регулярными топологиями типа гиперкубов или торов. Сеть ServerNet позволяет увеличить число линий связи в любом месте, где требуется дополнительная пропускная способность. Приложения с умеренными требованиями к системе межсоединений могут довольствоваться минимальным количеством связей, а следовательно, использовать достаточно дешевую сеть, в то время как приложения с высокой интенсивностью обработки данных могут рассчитывать на организацию сети с большей связностью.
Компания Tandem разработала системы Guardian и NonStop Kernel в расчете на распределенную обработку данных. В течение более двадцати последних лет компания постепенно выявляла и удаляла узкие места в программном обеспечении, ограничивающие возможности масштабирования системы. Чтобы добиться эффективного использования распределенных аппаратных средств при выполнении сложных запросов к базе данных, в базу данных NonStop SQL также были добавлены новые возможности.
В настоящее время в области масштабируемых распределенных вычислений начали широко использоваться также стандартные системы UNIX. В ряде научных приложениях кластеры рабочих станций начали заменять суперкомпьютеры. Предполагается, что эта тенденция станет главной движущей силой для усиленной разработки приложений и операционной среды распределенных вычислений.
В отличие от NonStop Kernel, которая сразу же была разработана как распределенная операционная система, большинство доступных ОС таким свойством не обладают. В качестве механизма масштабирования в этих системах обычно используется симметричная мультипроцессорная обработка (SMP). Этот механизм предполагает реализацию в системе единой разделяемой (общей) памяти, разделяемой системы в/в и когерентности кэш-памяти.
Новая архитектура обеспечивает гибкую реализацию разделяемой памяти. Как показано на Рисунок 4.8, несколько ЦП могут быть связаны друг с другом с помощью шины когерентности. Вместо использования единой глобальной памяти, память в системе распределена по ЦП. Это приводит к неодинаковому времени доступа к памяти, однако аппаратура поддерживает глобальное адресное пространство и когерентность кэш-памяти.
Временные параметры ДЗУПВ (в последней строке приведены ожидаемые параметры)
Хотя для организации кэш-памяти в большей степени важно уменьшение задержки памяти, чем увеличение полосы пропускания. Однако при увеличении полосы пропускания памяти возможно увеличение размера блоков кэш-памяти без заметного увеличения потерь при промахах.
Основными методами увеличения полосы пропускания памяти являются: увеличение разрядности или "ширины" памяти, использование расслоения памяти, использование независимых банков памяти, обеспечение режима бесконфликтного обращения к банкам памяти, использование специальных режимов работы динамических микросхем памяти.
Вторичная когерентность кэшпамяти
Вторичная когерентность кэш-памяти требуется для поддержки когерентности кэшей L1&L2 различных процессорных узлов, т.е. для обеспечения когерентного состояния всех имеющихся в мультипроцессорной системе распределенных кэшей (естественно включая поддержку когерентной буферизации ввода/вывода как по чтению, так и по записи).
Вторичная когерентность обеспечивается с помощью проверки каждой транзакции, возникающей на шине MPB_SysBus. Такая проверка позволяет обнаружить, что запрашиваемая по шине строка уже кэширована в процессорном узле, и обеспечивает выполнение необходимых операций. Это делается с помощью тегов кэша L2 и логически поддерживается тем фактом, что L1 является подмножеством L2.
и локальных сетей ПК самым
Появление в 80-х годах персональных компьютеров (ПК) и локальных сетей ПК самым серьезным образом изменило организацию корпоративных вычислений. Однако и сегодня освоение сетевых вычислений в масштабе предприятия и Internet продолжает оставаться не простой задачей. В отличие от традиционной, хорошо управляемой и безопасной среды вычислений предприятия, построенной на базе универсальной вычислительной машины (мейнфрейм) с подсоединенными к ней терминалами, среда локальных сетей ПК плохо контролируется, плохо управляется и небезопасна. С другой стороны, расширенные средства сетевой организации делают возможным разделение бизнес-информации внутри групп индивидуальных пользователей и между ними, внутри и вне корпорации и облегчают организацию информационных процессов в масштабе предприятия. Чтобы ликвидировать брешь между отдельными локальными сетями ПК и традиционными средствами вычислений, а также для организации распределенных вычислений в масштабе предприятия появилась модель вычислений на базе рабочих групп.
Как правило, термины серверы рабочих групп и сетевые серверы используются взаимозаменяемо. Сервер рабочей группы может быть сервером, построенным на одном процессоре компании Intel, или суперсервером (с несколькими ЦП), подобным изделиям компаний Compaq, HP, IBM и DEC, работающим под управлением операционной системы Windows NT. Это может быть также UNIX-сервер начального уровня компаний Sun, HP, IBM и DEC.
По мере постепенного вовлечения локальных сетей в процесс создания корпоративной вычислительной среды, требования к серверам рабочих групп начинают включать в себя требования, предъявляемые к серверам масштаба предприятия. Для этого прежде всего требуется более мощная сетевая операционная система. Таким образом, в настоящее время между поставщиками UNIX-систем, а также систем на базе Windows NT, увеличивается реальная конкуренция.
Рынок северов локальных сетей/рабочих групп представляет собой быстро растущий сегмент рынка. В период 1995-1996 годов мировой рынок серверов локальных сетей вырос на 32% по количеству поставок и на 39% по прибыли. Аналитическая компания IDC считает, что в период 1995-2000 года ежегодные темпы роста в этом секторе рынка будут составлять 16.1% по числу поставок и 16.9% - по прибыли. При этом IDC прогнозирует ежегодные темпы роста количества поставок мало масштабируемых UNIX-систем в 13%, а темпы роста количества поставок UNIX ПК в 8.9%.
Рынок серверов рабочих групп по их функциональному назначению может быть поделен на две основные части: с одной стороны это файл-серверы и принт-серверы, а с другой - серверы приложений. Из этих двух частей рынка серверов рабочих групп подавляющее большинство поставленных в прошлом систем составляют файл-серверы (в мировом масштабе 71% в 1995 году), но область серверов приложений представляет собой огромный потенциал для роста в будущем. В 1995 году количество поставок серверов приложений составило 29% от общего числа поставленных в мире сетевых серверов, причем большинство этих серверов использовались в качестве серверов баз данных. IDC прогнозирует рост доли этого типа серверов до 42% к 2000 году. Доля файл-серверов сократится до 58%.
Серверы приложений для рабочих групп могут поддерживать следующие типы приложений:
Приложения рабочих групп - календарь, расписание, поток работ, управление документами. Средства организации совместных работ - Lotus notes, электронные конференции. Прикладные сервисы для приложений клиент/сервер. Коммуникационные серверы (удаленный доступ и маршрутизация). Internet. Доступ к распределенной информации/данным. Традиционные сервисы локальных сетей - разделение файлов/принтеров. Управление системой/дистанционное управление. Электронная почта. В 1995 году наиболее быстро растущим сегментом на рынке серверов приложений были серверы баз данных, которые составили 33% поставок всех серверов приложений. IDC прогнозирует в период с 1995 по 2000 год ежегодный рост поставок серверов баз данных на уровне 22%, рост поставок серверов рабочих групп для управления потоками работ - на уровне 36%, а серверов Internet - на уровне 99%.
Основу следующего уровня современных информационных систем предприятий и организаций составляют корпоративные серверы различного функционального назначения, построенные на базе операционной системы Unix. Архитектура этих систем варьируется в широких пределах в зависимости от масштаба решаемых задач и размеров предприятия. Двумя основными проблемами построения вычислительных систем для критически важных приложений, связанных с обработкой транзакций, управлением базами данных и обслуживанием телекоммуникаций, являются обеспечение высокой производительности и продолжительного функционирования систем. Наиболее эффективный способ достижения заданного уровня производительности - применение параллельных масштабируемых архитектур. Задача обеспечения продолжительного функционирования системы имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющих предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Повышение уровня готовности предполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности есть способ борьбы за снижение времени простоя системы. Основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности от ремонтопригодности, контролепригодности и т.д.
В последние годы в литературе по вычислительной технике все чаще употребляется термин "системы высокой готовности" (High Availability Systems). Все типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Имеется два типа времени простоя компьютера: плановое и неплановое. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, принятое руководством, для проведения работ по модернизации системы и для ее обслуживания. Неплановое время простоя является результатом отказа системы или компонента. Хотя системы высокой готовности возможно больше ассоциируются с минимизацией неплановых простоев, они оказываются также полезными для уменьшения планового времени простоя.
Существует несколько типов систем высокой готовности, отличающиеся своими функциональными возможностями и стоимостью. Следует отметить, что высокая готовность не дается бесплатно. Стоимость систем высокой готовности на много превышает стоимость обычных систем. Вероятно поэтому наибольшее распространение в мире получили кластерные системы, благодаря тому, что они обеспечивают достаточно высокий уровень готовности систем при относительно низких затратах. Термин "кластеризация" на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: "реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей". Машины, кластеризованные вместе таким способом могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности.
Первой концепцию кластерной системы анонсировала компания DEC, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. В настоящее время на смену VAX-кластерам приходят UNIX-кластеры. При этом VAX-кластеры предлагают проверенный набор решений, который устанавливает критерии для оценки подобных систем.
VAX-кластер обладает следующими свойствами:
Разделение ресурсов. Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным.
Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров внешних накопителей и один из них отказывает, другие контроллеры автоматически подхватывают его работу.
Высокая пропускная способность. Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера.
Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера.
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер.
Работа любой кластерной системы определяется двумя главными компонентами: высокоскоростным механизмом связи процессоров между собой и системным программным обеспечением, которое обеспечивает клиентам прозрачный доступ к системному сервису.
В настоящее время широкое распространение получила также технология параллельных баз данных. Эта технология позволяет множеству процессоров разделять доступ к единственной базе данных. Распределение заданий по множеству процессорных ресурсов и параллельное их выполнение позволяет достичь более высокого уровня пропускной способности транзакций, поддерживать большее число одновременно работающих пользователей и ускорить выполнение сложных запросов. Существуют три различных типа архитектуры, которые поддерживают параллельные базы данных:
Симметричная многопроцессорная архитектура с общей памятью (Shared Memory SMP Architecture). Эта архитектура поддерживает единую базу данных, работающую на многопроцессорном сервере под управлением одной операционной системы. Увеличение производительности таких систем обеспечивается наращиванием числа процессоров, устройств оперативной и внешней памяти. Архитектура с общими (разделяемыми) дисками (Shared Disk Architecture). Это типичный случай построения кластерной системы. Эта архитектура поддерживает единую базу данных при работе с несколькими компьютерами, объединенными в кластер (обычно такие компьютеры называются узлами кластера), каждый из которых работает под управлением своей копии операционной системы. В таких системах все узлы разделяют доступ к общим дискам, на которых собственно и располагается единая база данных. Производительность таких систем может увеличиваться как путем наращивания числа процессоров и объемов оперативной памяти в каждом узле кластера, так и посредством увеличения количества самих узлов. Архитектура без разделения ресурсов (Shared Nothing Architecture). Как и в архитектуре с общими дисками, в этой архитектуре поддерживается единый образ базы данных при работе с несколькими компьютерами, работающими под управлением своих копий операционной системы. Однако в этой архитектуре каждый узел системы имеет собственную оперативную память и собственные диски, которые не разделяются между отдельными узлами системы. Практически в таких системах разделяется только общий коммуникационный канал между узлами системы. Производительность таких систем может увеличиваться путем добавления процессоров, объемов оперативной и внешней (дисковой) памяти в каждом узле, а также путем наращивания количества таких узлов. Таким образом, среда для работы параллельной базы данных обладает двумя важными свойствами: высокой готовностью и высокой производительностью. В случае кластерной организации несколько компьютеров или узлов кластера работают с единой базой данных. В случае отказа одного из таких узлов, оставшиеся узлы могут взять на себя задания, выполнявшиеся на отказавшем узле, не останавливая общий процесс работы с базой данных. Поскольку логически в каждом узле системы имеется образ базы данных, доступ к базе данных будет обеспечиваться до тех пор, пока в системе имеется по крайней мере один исправный узел. Производительность системы легко масштабируется, т.е. добавление дополнительных процессоров, объемов оперативной и дисковой памяти, и новых узлов в системе может выполняться в любое время, когда это действительно требуется.
Параллельные базы данных находят широкое применение в системах обработки транзакций в режиме on-line, системах поддержки принятия решений и часто используются при работе с критически важными для работы предприятий и организаций приложениями, которые эксплуатируются по 24 часа в сутки.
В основе реализации иерархии памяти
В основе реализации иерархии памяти современных компьютеров лежат два принципа: принцип локальности обращений и соотношение стоимость/производительность. Принцип локальности обращений говорит о том, что большинство программ к счастью не выполняют обращений ко всем своим командам и данным равновероятно, а оказывают предпочтение некоторой части своего адресного пространства.
Иерархия памяти современных компьютеров строится на нескольких уровнях, причем более высокий уровень меньше по объему, быстрее и имеет большую стоимость в пересчете на байт, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и так далее, пока мы не достигнем основания иерархии.
Иерархия памяти обычно состоит из многих уровней, но в каждый момент времени мы имеем дело только с двумя близлежащими уровнями. Минимальная единица информации, которая может либо присутствовать, либо отсутствовать в двухуровневой иерархии, называется блоком. Размер блока может быть либо фиксированным, либо переменным. Если этот размер зафиксирован, то объем памяти является кратным размеру блока.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание - есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate) или коэффициент попаданий (hit ratio) есть доля обращений, найденных на более высоком уровне. Иногда она представляется процентами. Доля промахов (miss rate) есть доля обращений, которые не найдены на более высоком уровне.
Поскольку повышение производительности является главной причиной появления иерархии памяти, частота попаданий и промахов является важной характеристикой. Время обращения при попадании (hit time) есть время обращения к более высокому уровню иерархии, которое включает в себя, в частности, и время, необходимое для определения того, является ли обращение попаданием или промахом. Потери на промах (miss penalty) есть время для замещения блока в более высоком уровне на блок из более низкого уровня плюс время для пересылки этого блока в требуемое устройство (обычно в процессор). Потери на промах далее включают в себя две компоненты: время доступа (access time) - время обращения к первому слову блока при промахе, и время пересылки (transfer time) - дополнительное время для пересылки оставшихся слов блока. Время доступа связано с задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между устройствами памяти двух смежных уровней.
Чтобы описать некоторый уровень иерархии памяти надо ответить на следующие четыре вопроса:
1. Где может размещаться блок на верхнем уровне иерархии? (размещение блока).
2. Как найти блок, когда он находится на верхнем уровне? (идентификация блока).
3. Какой блок должен быть замещен в случае промаха? (замещение блоков).
4. Что происходит во время записи? (стратегия записи).
Надежные вычислительные машины являются ключевыми
Надежные вычислительные машины являются ключевыми элементами для построения наиболее ответственных прикладных систем в сфере розничной торговли, финансов и телефонной коммутации. На современном этапе развития информационных технологий подобные приложения предъявляют широкий диапазон требований к масштабируемости, поддержке открытых стандартов и обеспечению отказоустойчивости систем. Одной из наиболее известных в мире фирм, работающих в данной области, является компания Tandem. В настоящее время для удовлетворения различных требований рынка надежных вычислений она поставляет две различные линии своих изделий: системы Tandem
NonStop и системы Tandem Integrity.
Системы Tandem NonStop, первые модели которых появились еще в 1976 году, базируются на реализации многопроцессорной обработки и модели распределенной памяти. Для обеспечения восстановления после сбоев аппаратуры и ошибок программного обеспечения эти системы используют механизмы передачи сообщений между процессными парами. База данных NonStop SQL, в основе архитектуры которой лежит модель системы без разделения ресурсов (shared-nothing), показала линейную масштабируемость в приложениях обработки транзакций на конфигурациях, содержащих более 100 процессоров. Первоначально системы NonStop были нацелены на создание приложений оперативной обработки транзакций (OLTP), но в настоящее время интенсивно используются и в других ответственных приложениях (системах передачи сообщений и системах поддержки принятия решений).
Для удовлетворения потребностей рынка в отказоустойчивых системах, позволяющих выполнять без переделок существующие UNIX-приложения, в 1990 году компания Tandem объявила о начале выпуска систем Integrity. Для маскирования ошибок в работе систем Integrity используются методы аппаратной избыточности (трехкратное резервирование), обеспечивающие продолжение непрерывной работы в условиях сбоев без воздействия на приложения. Системы Integrity часто используются в телефонных и сотовых сетях связи, а также в других коммерческих приложениях, требующих реализации надежных систем, удовлетворяющих открытым стандартам.
Хотя указанные две линии изделий компании имеют отличия, они удовлетворяют целому ряду общих требований и используют многие общие технологии и компоненты. Все системы Tandem гарантируют целостность данных и устойчивость к сбоям, и кроме того, обеспечивают масштабируемость и возможность производить модернизацию системы в режиме online. Обе линии изделий NonStop и Integrity позволяют выполнять техническое обслуживание систем в режиме online (установку и замену плат, источников питания и вентиляторов без остановки системы и выключения питания). Применяемые конструкции допускают установку обеих систем в офисных помещениях, стандартных машинных залах вычислительных центров или на телефонных станциях. В системах используются много общих компонентов таких, как накопители на дисках, элементы памяти и микропроцессоры.
В 1991 году компания Tandem начала программу объединения лучших свойств обеих систем в единой линии изделий. Эта программа дает возможность гибкой реализации целого ряда важнейших свойств: устойчивости к сбоям (восстановление после проявления неисправности может выполняться как программными, так и аппаратными средствами), масштабируемости (построение кластеров на базе модели распределенной памяти и реализация мультипроцессорной обработки в разделяемой общей памяти) и использовании нескольких операционных систем (NonStop Kernel, Unix и Microsoft Windows NT).
Основой для объединения архитектур послужила разработка главного транспортного средства - системной сети ServerNet. ServerNet представляет собой многоступенчатую пакетную сеть, используемую как для организации межпроцессорных связей, так и для реализации связей с устройствами ввода/вывода. ServerNet обеспечивает эффективные средства для обнаружения и изоляции неисправностей, а также реализует прямую поддержку альтернативных каналов передачи данных для обеспечения непрерывной работы системы при наличии отказов сети. Разработка этой сети предоставляет новые возможности развития обеих линий изделий, включая большую масштабируемость, интерфейсы с открытыми стандартами шин и улучшенную поддержку мультимедийных приложений.
Выбор конфигурации сервера СУБД
Хотя данный материал предлагает некоторые рекомендации по конфигурированию систем, полезность этих рекомендаций в значительной степени зависит от анализа самого приложения. Важность такого анализа невозможно переоценить! Эффективность работы самого приложения и СУБД намного важнее, чем конфигурация хост-машины. Имеются буквально сотни примеров небольших изменений, проведенных в приложении или в схеме базы данных, которые обеспечивали 100- или 1000-кратное (или даже большее!) увеличение производительности системы. Например, в зависимости от того индексируется или нет таблица с помощью ключа просмотра (lookup key), выполнение оператора select, который запрашивает одну определенную запись, может приводить к тому, что СУБД будет читать из таблицы всего одну запись, либо каждую запись в таблице, содержащей 10 Гбайт данных. Часто для того чтобы оптимально обрабатывать несколько различных шаблонных обращений, генерируемых приложением, таблица должна индексироваться более чем одним ключом или набором ключей. Хорошо осмысленная индексация может иметь весьма существенное воздействие на общую производительность системы (см. разд. 2.2.6.1). После начальной инсталляции системы обязательно нужно произвести сбор статистики о ее работе, чтобы выяснить необходимость внесения изменений в базу данных, даже для приложений собственной разработки или приложений третьих фирм. Часто оказывается возможным улучшить производительность приложения путем реорганизации базы данных даже без обращения к исходному коду приложения.
Другим соображением, которому уделяется недостаточно внимания, но которое часто оказывает огромные воздействие на результирующую производительность системы, являются конфликты по внутренним блокировкам. СУБД должна блокировать доступ к данным при наличии конфликтующих одновременных обращений. Любой другой процесс, который требует доступа к этим данным должен быть отложен до тех пор, пока блокировка не будет снята. Если выбрана неоптимальная стратегия блокировок, то система может оказаться очень плохо работающей.
Каждая СУБД имеет огромное число настраиваемых параметров, некоторые из которых могут серьезно воздействовать на общую производительность системы. Приводимые здесь рекомендации предполагают разумную настройку приложений и СУБД.
Выбор размера буфера ввода/вывода СУБД
Каждая СУБД называет свои буфера данных по разному, но все они выполняют одну и ту же функцию. Oracle называет эту память Глобальной Областью Системы (SGA - System Global Area), в то время как Sybase называет ее Кэшем Разделяемых Данных (Shared Data Cashe). Обычно буфер реализуется как большой массив разделяемой памяти, и его размер определяется специальным параметром в управляющем файле или таблицах СУБД. Размер памяти, необходимый для организации дискового кэша СУБД, меняется в широких пределах от приложения к приложению, но для примерной оценки размера буфера могут быть использованы следующие эмпирические правила.
Практические опыты различных компаний с СУБД Oracle и Sybase показали, что в зависимости от размера базы данных размер области памяти под буфера может варьироваться в очень широких пределах (от 4 Мбайт до более чем 1 Гбайт). Даже указанный больший размер буфера сегодня может быть превышен, поскольку начинают появляться реализованные на базе современных аппаратных платформ значительно большие по размеру базы данных (объемом 50 - 300 Гбайт). Однако следует иметь в виду, что как и при использовании любой кэш-памяти, увеличение размера буфера в конце концов достигает точки насыщения. Очень грубо размер кэша данных можно оценить, выделяя от 50 до 300 Кбайт на каждого пользователя. Каждая из известных систем СУБД имеет механизм сообщений об эффективности использования кэша разделяемых данных. Большинство систем могут также обеспечивать оценку того, какой эффект будет давать увеличение или уменьшение размера кэша.
Возможно самым простым и наиболее полезным является эмпирическое правило, которое называется "правилом пяти минут". Это правило широко используется при конфигурировании серверов баз данных, значительно большая сложность которых делает очень трудным точное определение размера кэша. Существующее в настоящее время соотношение между ценами подсистемы памяти и дисковой подсистемы показывает, что экономически целесообразно кэшировать данные, к которым осуществляются обращения более одного раза каждые пять минут.
Это означает, что данные, к которым обращения происходят более часто, чем один раз в пять минут, должны кэшироваться в памяти. Соответственно, чтобы оценить размер кэша данных необходимо просуммировать объемы всех данных, которые приложение предполагает использовать более часто, чем один раз в пять минут на уровне всей системы. Поэтому при определении необходимого объема памяти системы следует предусмотреть по крайней мере этот размер кэша данных. Дополнительно, следует зарезервировать еще 5-10% для хранения верхних уровней индексов B-деревьев, хранимых процедур и другой управляющей информации СУБД.
Не стоит волноваться из-за того, что чрезмерное увеличение размера кэша обычно не дает существенного эффекта. Указанные прогнозируемые объемы должны использоваться только для получения грубой оценки необходимой конфигурации системы. Каждая коммерческая СУБД обеспечивает механизм для определения стоимости или преимуществ изменения размера различных кэшей СУБД. Когда система инсталлирована и начинает работать, необходимо использовать эти механизмы для определения эффекта от изменения размеров кэша ввода/вывода СУБД. Следует отметить, что результаты часто могут оказаться удивительными. Например, выделение слишком большого объема памяти для кэша разделяемых данных может лишить пользовательское приложение (или, что еще хуже, сам сервер СУБД) требуемой для нормальной работы памяти. Память может также перераспределяться между кэшем разделяемых данных и пулом виртуальной памяти, используемой операционной системой для буферизации операций файловой системы UNIX (UFS).
Хотя основной целью СУБД на макроуровне является управление томами данных, которые по определению имеют очень большой объем и неизбежно во много раз превышают объем основной памяти, буквально десятки исследований многократно показали, что доступ к данным в общем случае подчиняется правилу "90/10": 90% всех обращений выполняются к 10% данных. Более того, совсем недавние исследования показали, что к "горячим" данным, обращения к которым составляют 90% всех обращений, снова применимо правило 90/10. Таким образом, примерно 80% всех обращений к данным связаны с доступом к примерно 1% агрегатированных данных. Следует отметить, что это отношение включает обращения к внутренним метаданным СУБД (включающих индексы B-деревьев и т.п.), обращения к которым обычно скрыты от прикладного программиста. Хотя желательно иметь коэффициент попаданий в кэш примерно на уровне 95%, по экономическим соображениям невозможно слепо обеспечить объем кэша в памяти, позволяющий разместить 10% всех данных: даже для скромных баз данных объемом 5 Гбайт это потребовало бы увеличения размера основной памяти до 500 Мбайт. Однако обычно всегда возможно обеспечить кэш объемом в 1% всех данных даже для очень больших баз данных. Те же самые 500 Мбайт основной памяти, таким образом, позволяют обслужить базу данных объемом 50 Гбайт, а максимальный размер памяти, например, SPARCcenter 2000 (5 Гбайт) компании Sun достаточен для поддержки баз данных объемом 400-500 Гбайт. (При наличии баз данных такого размера для поддержки неизбежно большого числа пользовательских приложений и т.д. очевидно также потребуется существенная часть этой памяти).
Рекомендации:
Размер кэша данных СУБД следует выбирать так, чтобы данные, обращения к которым выполняются чаще одного раза в пять минут, могли бы храниться в кэше. Дополнительно необходимо добавить 5-10%. Если шаблон (образец) обращений не может быть определен, необходимо обеспечить кэш емкостью, соответствующей по крайней мере 1% от чистого объема данных СУБД (не считая индексов и накладных расходов). В крайнем случае размер кэша данных конфигурируется исходя из выделения по 100-150 Кбайт на пользователя.Выбор вычислительной модели
В большинстве прикладных систем СУБД можно выделить три логических части: пользовательский интерфейс (средства представления), обеспечивающий функции ввода и отображения данных; некоторую прикладную обработку, характерную для данной предметной области; и собственно сервисы СУБД. Пользовательский интерфейс и прикладная обработка обычно объединены в одном двоичном коде, хотя некоторые из наиболее продвинутых приложений теперь обеспечивают многопотоковую фронтальную обработку, которая отделена от средств представления. Как правило, по мере роста базы данных сервер СУБД реализуется на выделенной системе, чтобы гарантировать минимизацию помех для его работы.
Выполнение по предположению (speculation)
Поддерживаемое аппаратурой выполнение по предположению позволяет выполнить команду до момента определения направления условного перехода, от которого данная команда зависит. Это снижает потери, которые возникают при наличии в программе зависимостей по управлению. Чтобы понять, почему выполнение по предположению оказывается полезным, рассмотрим следующий простой пример программного кода, который реализует проход по связанному списку и инкрементирование каждого элемента этого списка:
for (p=head; p <> nil; *p=*p.next) {
*p.value = *p.value+1;
}
Подобно циклам for, с которыми мы встречались в более ранних разделах, разворачивание этого цикла не увеличит степени доступного параллелизма уровня команд. Действительно, каждая развернутая итерация будет содержать оператор if и выход из цикла. Ниже приведена последовательность команд в предположении, что значение head находится в регистре R4, который используется для хранения p, и что каждый элемент списка состоит из поля значения и следующего за ним поля указателя. Проверка размещается внизу так, что на каждой итерации цикла выполняется только один переход.
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
Развернув цикл однажды можно видеть, что разворачивание в данном случае не помогает:
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
BNEZ R4,end
LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
end:
Даже прогнозируя направление перехода мы не можем выполнять с перекрытием команды из двух разных итераций цикла, и условные команды в любом случае здесь не помогут. Имеются несколько сложных моментов для выявления параллелизма из этого развернутого цикла:
Первая команда в итерации цикла (LW R5,0(R4)) зависит по управлению от обоих условных переходов. Таким образом, команда не может выполняться успешно (и безопасно) до тех пор, пока мы не узнаем исходы команд перехода. Вторая и третья команды в итерации цикла зависят по данным от первой команды цикла. Четвертая команда в каждой итерации цикла (LW R4,4(R4)) зависит по управлению от обоих переходов и антизависит от непосредственно предшествующей ей команды SW. Последняя команда итерации цикла зависит от четвертой.Вместе эти условия означают, что мы не можем совмещать выполнение никаких команд между последовательными итерациями цикла! Имеется небольшая возможность совмещения посредством переименования регистров либо аппаратными, либо программными средствами, если цикл развернут, так что вторая загрузка более не антизависит от SW и может быть перенесена выше.
В альтернативном варианте, при выполнении по предположению, что переход не будет выполняться, мы можем попытаться совместить выполнение последовательных итераций цикла. Действительно, это в точности то, что делает компилятор с планированием трасс. Когда направление переходов может прогнозироваться во время компиляции, и компилятор может найти команды, которые он может безопасно перенести на место перед точкой перехода, решение, базирующееся на технологии компилятора, идеально. Эти два условия являются ключевыми ограничениями для выявления параллелизма уровня команд статически с помощью компилятора. Рассмотрим развернутый выше цикл. Переход просто трудно прогнозируем, поскольку частота, с которой он является выполняемым, зависит от длины списка, по которому осуществляется проход. Кроме того, мы не можем безопасно перенести команду загрузки через переход, поскольку, если содержимое R4 равно nil, то команда загрузки слова, которая использует R4 как базовый регистр, гарантированно приведет к ошибке и обычно сгенерирует исключительную ситуацию по защите. Во многих системах значение nil реализуется с помощью указателя на неиспользуемую страницу виртуальной памяти, что обеспечивает ловушку (trap) при обращении по нему. Такое решение хорошо для универсальной схемы обнаружения указателей на nil, но в данном случае это не очень помогает, поскольку мы можем регулярно генерировать эту исключительную ситуацию, и стоимость обработки исключительной ситуации плюс уничтожения результатов выполнения по предположению будет огромной.
Чтобы преодолеть эти сложности, машина может иметь в своем составе специальные аппаратные средства поддержки выполнения по предположению. Эта методика позволяет машине выполнять команду, которая может быть зависимой по управлению, и избежать любых последствий выполнения этой команды (включая исключительные ситуации), если окажется, что в действительности команда не должна выполняться. Таким образом выполнение по предположению, подобно условным командам, позволяет преодолеть два сложных момента, которые могут возникнуть при более раннем выполнении команд: возможность появления исключительной ситуации и ненужное изменение состояния машины, вызванное выполнением команды. Кроме того, механизмы выполнения по предположению позволяют выполнять команду даже до момента оценки условия командой условного перехода, что невозможно при условных командах. Конечно, аппаратная поддержка выполнения по предположению достаточно сложна и требует значительных аппаратных ресурсов.
Один из подходов, который был хорошо исследован во множестве исследовательских проектов и используется в той или иной степени в машинах, которые разработаны или находятся на стадии разработки в настоящее время, заключается в объединении аппаратных средств динамического планирования и выполнения по предположению. В определенной степени подобную работу делала и IBM 360/91, поскольку она могла использовать средства прогнозирования направления переходов для выборки команд и назначения этих команд на станции резервирования. Механизмы, допускающие выполнение по предположению, идут дальше и позволяют действительно выполнять эти команды, а также другие команды, зависящие от команд, выполняющихся по предположению.
Аппаратура, реализующая алгоритм Томасуло, который был реализован в IBM 360/91, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо отделить средства пересылки результатов команд, которые требуются для выполнения по предположению некоторой команды, от механизма действительного завершения команды. Имея такое разделение функций, мы можем допустить выполнение команды и пересылать ее результаты другим командам, не позволяя ей однако делать никакие обновления состояния машины, которые не могут быть ликвидированы, до тех пор, пока мы не узнаем, что команда должна безусловно выполниться. Использование цепей ускоренной пересылки также подобно выполнению по предположению чтения регистра, поскольку мы не знаем, обеспечивает ли команда, формирующая значение регистра-источника, корректный результат до тех пор, пока ее выполнение не станет безусловным. Если команда, выполняемая по предположению, становится безусловной, ей разрешается обновить регистровый файл или память. Этот дополнительный этап выполнения команд обычно называется стадией фиксации результатов команды (instruction commit).
Главная идея, лежащая в основе реализации выполнения по предположению, заключается в разрешении неупорядоченного выполнения команд, но в строгом соблюдении порядка фиксации результатов и предотвращением любого безвозвратного действия (например, обновления состояния или приема исключительной ситуации) до тех пор, пока результат команды не фиксируется. В простом конвейере с выдачей одиночных команд мы могли бы гарантировать, что команда фиксируется в порядке, предписанном программой, и только после проверки отсутствия исключительной ситуации, вырабатываемой этой командой, просто посредством переноса этапа записи результата в конец конвейера. Когда мы добавляем механизм выполнения по предположению, мы должны отделить процесс фиксации команды, поскольку он может произойти намного позже, чем в простом конвейере. Добавление к последовательности выполнения команды этой фазы фиксации требует некоторых изменений в последовательности действий, а также в дополнительного набора аппаратных буферов, которые хранят результаты команд, которые завершили выполнение, но результаты которых еще не зафиксированы. Этот аппаратный буфер, который можно назвать буфером переупорядочивания, используется также для передачи результатов между командами, которые могут выполняться по предположению.
Буфер переупорядочивания предоставляет дополнительные виртуальные регистры точно так же, как станции резервирования в алгоритме Томасуло расширяют набор регистров. Буфер переупорядочивания хранит результат некоторой операции в промежутке времени от момента завершения операции, связанной с этой командой, до момента фиксации результатов команды. Поэтому буфер переупорядочивания является источником операндов для команд, точно также как станции резервирования обеспечивают промежуточное хранение и передачу операндов в алгоритме Томасуло. Основная разница заключается в том, что когда в алгоритме Томасуло команда записывает свой результат, любая последующая выдаваемая команда будет выбирать этот результат из регистрового файла. При выполнении по предположению регистровый файл не обновляется до тех пор, пока команда не фиксируется (и мы знаем определенно, что команда должна выполняться); таким образом, буфер переупорядочивания поставляет операнды в интервале между завершением выполнения и фиксацией результатов команды. Буфер переупорядочивания не похож на буфер записи в алгоритме Томасуло, и в нашем примере функции буфера записи интегрированы с буфером переупорядочивания только с целью упрощения. Поскольку буфер переупорядочивания отвечает за хранение результатов до момента их записи в регистры, он также выполняет функции буфера загрузки.
Каждая строка в буфере переупорядочивания содержит три поля: поле типа команды, поле места назначения (результата) и поле значения. Поле типа команды определяет, является ли команда условным переходом (для которого отсутствует место назначения результата), командой записи (которая в качестве места назначения результата использует адрес памяти) или регистровой операцией (команда АЛУ или команда загрузки, в которых местом назначения результата является регистр). Поле назначения обеспечивает хранение номера регистра (для команд загрузки и АЛУ) или адрес памяти (для команд записи), в который должен быть записан результат команды. Поле значения используется для хранения результата операции до момента фиксации результата команды. На рисунке 3.20 показана аппаратная структура машины с буфером переупорядочивания. Буфер переупорядочивания полностью заменяет буфера загрузки и записи. Хотя функция переименования станций резервирования заменена буфером переупорядочивания, нам все еще необходимо некоторое место для буферизации операций (и операндов) между моментом их выдачи и началом выполнения. Эту функцию выполняют регистровые станции резервирования. Поскольку каждая команда имеет позицию в буфере переупорядочивания до тех пор, пока она не будет зафиксирована (и результаты не будут отправлены в регистровый файл), результат тегируется посредством номера строки буфера переупорядочивания, а не номером станции резервирования. Это требует, чтобы номер строки буфера переупорядочивания, присвоенный команде, отслеживался станцией резервирования.
При разработке PowerScale Bull удалось
При разработке PowerScale Bull удалось создать архитектуру с достаточно высокими характеристиками производительности в расчете на удовлетворение нужд приложений пользователей сегодня и завтра. И обеспечивается это не только увеличением числа процессоров в системе, но и возможностью модернизации поколений процессоров PowerPC. Разработанная архитектура привлекательна как для разработчиков систем, так и пользователей, поскольку в ее основе лежит одна из главных процессорных архитектур в компьютерной промышленности - PowerPC.
ServerNet создает надежную инфраструктуру для
ServerNet создает надежную инфраструктуру для построения и крупномасштабных, и небольших отказоустойчивых систем. Она позволяет объединить между собой несколько сотен процессоров и независимо наращивать количество связей между процессорами и периферийными устройствами, обеспечивая масштабируемую полосу пропускания и избыточные каналы передачи данных. Организация связей типа "каждый с каждым" позволяет предотвратить ненужные промежуточные пересылки данных, которые истощают ресурсы процессоров и памяти. ServerNet предоставляет также средства создания горячего резерва и балансировки нагрузки путем коммутации периферийных устройств между собой.
Базирующиеся на ServerNet системы представляют собой существенный шаг вперед в архитектуре коммерческих отказоустойчивых систем. Одна и та же архитектура дает возможность построения отказоустойчивых систем как чисто аппаратными, так и чисто программными средствами. Она обеспечивает также дополнительную гибкость, поддерживая как модель вычислений в разделяемой общей памяти, так и создание кластеров с распределенной памятью. Из одних и тех же компонентов можно создавать системы разного класса выбирая операционные системы, процессоры и механизмы поддержки отказоустойчивости.
Заключительные рекомендации по конфигурированию сетевого ввода/вывода
Для конфигураций клиент/сервер, где клиенты работают на удаленных ПК или рабочих станциях, следует конфигурировать по 20-50 клиентов на одну сеть Ethernet. Количество клиентов в одной сети 16 Мбит/с Token Ring может достигать 100 благодаря прекрасной устойчивости к деградации под нагрузкой. Если фронтальная система обслуживает большое количество клиентов, то между фронтальной системой и сервером СУБД следует предусмотреть специальную выделенную сеть. При этом если приходится манипулировать очень большими объектами данных (более 500 Кбайт на объект), то вместо сетей Ethernet или Token Ring следует применять FDDI. Фронтальная система и сервер СУБД могут объединяться с помощью глобальных сетей, обеспечивающих "достаточную" полосу пропускания. В идеале это предполагает по крайней мере использование неполной линии T1. Такие приложения должны быть относительно малочувствительны к задержке сети. При конфигурировании систем клиент/сервер с использованием глобальных сетей следует исследовать возможность применения мониторов обработки транзакций для снижения трафика клиент/сервер до минимума. В частных сетях обычно нет никаких проблем с использованием терминальных серверов, если только сами разделяемые сети не загружены тяжело для других целей.
