Таблица "совместимости"
Как уже упоминалось, XKB вынужден решать "проблему совместимости" с программами, которые не подозревают о существовании XKB и обращаются с запросами к "core-модулю" X-сервера.
Естественно, модуль XKB может обработать эти запросы, но основная проблема, возникающая при этом, состоит в том, что в модуле XKB вводятся некоторые новые понятия (новые относительно core protocol'а), которые никак не отражены в "традиционных" запросах к клавиатурному модулю.
Во-первых, в XKB больше модификаторов и их поведение может гибко перестраиваться. Поэтому, как уже упоминалось, для совместимости модулю XKB приходится поддерживать восемь "традиционных" модификаторов и осуществлять отображение (преобразование) своих модификаторов в "традиционные".
Более того. XKB вынужден поддерживать "традиционный" формат "сообщения о нажатии/отпускании" клавиши, в котором передается "состояние" клавиатурного модуля, состоящее из набора реальных модификаторов. Даже если модуль XKB общается с XKB-совместимой Xlib, он вынужден, для передачи ей информации о состоянии своих виртуальных модификаторов, "превращать" их в реальные.
(Поэтому, кстати, виртуальный модификатор не оказывает никакого эффекта, если он не "отображен" в какой-нибудь реальный).
Во-вторых, в core protocol "номер группы" имеет другой смысл. Как уже говорилось - групп всего две, переключаются они символом Mode_Switch и в "состоянии клавиатуры" переключение на "дополнительную" группу отображается одним из модификаторов Mod1-Mod5 - тем, который связан с символом Mode_Switch.
Таким образом, в "традиционном" протоколе номер группы отображается одним из модификаторов - "основная группа/альтернативная группа", а в модуле XKB, в "состоянии клавиатуры" явно существует двухбитное поле - "номер группы" (которое, к тому же, не "перекрывается" с набором модификаторов).
Кроме того, в "традиционном" модуле клавиатуры каждая группа состоит ровно из двух "уровней". Хотя при этом допускается, что каждому скан-коду может быть сопоставлен одномерный массив символов длиной до 256. Первые четыре ячейки в нем соответствуют "двум группам, в каждой по два уровня". Остальные ячейки "клиентская" программа может выбирать сама, в зависимости от состояния модификаторов Mod1-Mod5.
Поэтому, для совместимости модуль XKB, при общении со "старыми" программами, вынужден ...
Во-первых, "размазывать" свои подтаблицы-группы в одну строчку "традиционной" таблицы символов (честно говоря, я так и не понял общий алгоритм этого действия, кроме тривиального случая, когда скан-коду соответствует две группы, каждая из двух уровней). Во-вторых, отображать свой "номер группы" в состояние какого-нибудь "реального" модификатора.
Наконец, в core-модуле отсутствуют "действия" - основной механизм, обеспечивающий "гибкость поведения" XKB. В связи с этим возникает проблема - "старая" программа может поменять "привязку" символов к скан-кодам, но, поскольку она не подозревает о том, что к скан-кодам могут быть "привязаны" также и "действия", может возникнуть ситуация, когда такая программа переместить, например, символ "переключатель РУС/ЛАТ" на другую клавишу, а соответствующее "действие" (которое в XKB реально осуществляет это переключение) останется на старом месте.
Для решения этой проблемы в XKB хранится таблица "интерпретаций" (interpretation) управляющих символов. Эта таблица связывает коды символов и вызовы соответствующих "действий" (actions). Естественно, в этой таблице присутствуют только специальные "управляющие" символы ( Caps_Lock, Shift, Num_Lock, "переключатель РУС/ЛАТ" и т.п.).
Кроме самих символов и "действий" в таблице интерпретаций хранится также дополнительная информация - список "реальных модификаторов" и "критерий соответствия" ("любой из модификаторов", "все указанные модификаторы", "только указанные модификаторы" и т.п.).
Каждый раз при изменении "привязки" символа (учтите, что это изменение может происходить при старте X-сервера, как часть "начальной настройки" сервера) модуль XKB проверяет - присутствует ли в этот символ в "таблице интерпретаций". И если символ там есть, то XKB, "присвоив" этот символ требуему скан-коду, добавляет этому скан-коду и соответствующее "действие". Дополнительная информация (модификаторы и "критерий соответствия") тоже может использоваться при "поиске" подходящего места для "действия".
Кроме того, применение "интерпретации" может поменять некоторую другую информацию, связанную со скан-кодом - флаги, отвечающие за "автоповтор" и "залипание" клавиши и "список виртуальных модификаторов".
Напомню, что у каждого скан-кода может быть указан набор "исключений", который защитит информацию, связанную со скан-кодом от применения "интерпретации".
Надо отметить, что помещать все "действия" в "таблицу интерпретаций", а не присваивать их непосредственно скан-кодам - является "хорошим тоном". Поскольку в "таблице интерпретаций" "действие" связывается с символом, а не со скан-кодом, и, к тому же, "перенос" "действий" из "таблицы интерпретаций" в соответствуюшие таблицы "действий" скан-кодов XKB выполняет каждый раз при загрузке конфигурации (в том числе и при старте X-сервера), модуль XKB сам найдет подходящее место для соответствующего "действия" и, таким образом, корректно "свяжет" символы и действия (в таблицах, назначенных скан-кодам).
Так что же делать?
Во-первых, если такое желание юзера не каприз, а вытекает из потребности организации (например, два отдела могут "подглядывать" в документы друг друга, но не менять их, при этом все остальные не должны даже смотреть), то имеет смысл обратиться к администратору. Пусть он создаст новые группы и определит их состав.
Если же у юзера просто ежедневно меняются симпатии и антипатии к другим юзерам этой же машины, то тут помочь практически нечем. Если уж надо "спрятать" файл от кого-то из членов группы, придется прятать от всей группы. Можно еще воспользоваться "полусекретными" директориями, как описано в "Странные" сочетания битов доступа..
И напоследок несколько слов о механизме, который решает все описанные проблемы, но, к сожалению, отсутствует во многих Юниксах (в том числе и в FreeBSD).
Так как же все таки надо поступить?
Способ с "испорченным" паролем более универсальный, но неправильный :-).
Самый правильный путь - подбирать всех демонов таких, которые правильно отрабатывают запрет входа (например, через "account expiration"). Кстати, те демоны, которые у вас "с раздачи" (то есть, из "родного" дистрибутива), должны правильно обрабатывать такой запрет. Проблемы могут возникнуть только с программами от других разработчиков.
Кроме того, для юзеров, запускающих "IP по модему", обычно, другой способ входа недоступен. Поэтому можно смело пользоваться "account expiration" или запретом в /etc/login.access.
Такие разные файлы
Осталось выяснить, что такое файл блочного устройства. Для этого следует рассказать о том, какие вообще "звери" встречаются в файловой системе. Очевидно, там есть обычные файлы и каталоги, но это далеко не все. Файлами с точки зрения Linux являются также:
символьные устройства; блочные устройства; именованные каналы (named pipes); гнезда (sockets); символьные ссылки (symlinks).
Все эти "звери" в чем-то похожи на обычные файлы, а в чем-то отличаются от них (во всяком случае, все они могут быть удалены системным вызовом unlink, что сближает их с обычными файлами и отдаляет от каталогов). Рассмотрим их по порядку.
Технология виртуальных машин позволяет выполнять несколько копий ОС на одном компьютере

Eсли у вас есть спутниковое телевидение, то, возможно, вы видели этой осенью рекламу под названием «Грабеж». Взбудораженный менеджер среднего звена и средних же лет приводит полицию в пустую серверную. «Это грабеж века! — восклицает он. — Все пропало!»
«Что пропало?» — спрашивает один из полицейских.
«Все! — вопит в отчаянии взлохмаченный служащий. — Списки сотрудников, результаты исследований, данные о клиентах...»
Конечно же, положение спасает наш герой, неряшливый с виду системный администратор. Он указывает на мэйнфрейм в дальнем углу комнаты и произносит: «Мы перенесли данные на эту машину. Она сэкономит нам кучу денег. Я уже выслал письмо...»
Музыка нарастает, и, пробиваясь сквозь шум, голос диктора говорит что-то о серверах IBM с ОС Linux, благодаря которым вы сбережете немалые средства. Реклама умалчивает лишь о том, что на сервере IBM одновременно было запущено множество копий Linux в качестве виртуальных машин.
Идея виртуальных машин — нечто под названиями «виртуализация», «виртуальные среды» или «виртуальные серверы» — не нова, операционная система IBM VM дебютировала более 20 лет назад. (Термин «виртуальная машина» также используется для описания продукта VMware, благодаря которому Linux и Windows могут работать бок о бок на одном компьютере.) Тем не менее она только сегодня начинает приобретать популярность вследствие стремления компаний снизить затраты на аппаратное обеспечение и поддержку, а в некоторых случаях — арендную плату огромных серверных ферм.
В рекламе продукции IBM не упоминается (да и с чего бы) о способности виртуальных машин неплохо функционировать на недорогих серверах и рабочих станциях, а также о предложениях по крайней мере со стороны нескольких компаний, включая VMware, SWsoft и Ensim, технологии на базе Linux, наподобие виртуальной машины, для тех, кто не может позволить себе мэйнфрейм IBM zSeries за миллион долларов. Осенью даже появился проект для ядра Linux по обеспечению работы «частных виртуальных серверов» как в Linux, так и в других системах с открытым исходным кодом. Ряд производителей выпускает даже такие продукты, как виртуальные базы данных.
Сайт ConsultingTimes.com предлагает загрузить рекламный видеоролик из «Грабежа» вместе с ценовым сравнением установки IBM и Microsoft Exchange. В статье высказывается мнение, что решение IBM может оказаться менее экономичным при выполнении серверных функций, чем Microsoft Exchange, для тех компаний, где число пользователей не превышает 5000. Однако если у компании 25 тыс. пользователей, вычислительная мощь мэйнфрейма IBM позволяет намного эффективнее сократить расходы в расчете на одно рабочее место.
Темы для строки приглашения
Благодаря возможностям zsh пользователи пишут различные модули расширения. Одним из таких модулей является модуль для установки тем для строк приглашения. Этот модуль загружается с помощью команд:
autoload -U promptinit
promptinit
и позволяет пользователям использовать заранее подготовленные темы для приглашений. Команда prompt -p выдает примеры всех установленных тем строки приглашения.
Теперь давайте сделаем ЭТО
Для создания исполняемых файлов вам нужно выполнить следующие команды:
as86 boot.s -o boot.o
ld86 -d boot.o -o boot
cc write.c -o write
Сперва, мы компилируем объектный файл boot.o из boot.s . Затем конвертируем его в двоичный, boot . Ключ -d заставляет компоновщик ld86 удалить все заголовки и создать "голый" двоичный файл. Если у вас возникли сомнения или появились неясности в этом вопросе, прочтите страницы справочного руководства по as86 и ld86. Последним мы компилируем C-программу и получаем исполняемый файл write.
Вставьте пустую дискету в дисковод и наберите команду (Убедитесь, что у вас есть права на запись в /dev/fd0. И вообще, никто вам не мешает использовать для тех же целей команду dd [dd if=boot of=/dev/fd0 ]. или команду копирования cp [cp boot /dev/fd0 ]. Возможно, автор планирует расширить возможности этой программы для дальнейшего использования в следующих статьях. Прим.перев.):
./write
Перезагрузите машину. Настройте BIOS так, чтобы система грузилась в первую очередь с дискеты. Вставьте дискету в дисковод и дождитесь, пока компьютер загрузится с нее.
Теперь вы можете видеть символ 'A' (белого цвета на синем фоне). Это означает, что программа, которую мы написали и скопировали в загрузочный сектор, была загружена с дискеты и выполнена. Теперь она находится в бесконечном "программном" цикле в конце кода загрузчика. Чтобы вернуться в привычную среду обитания (читай -- Linux 8-) нужно перезагрузить компьютер, предварительно удалив дискету из дисковода.
В дальнейшем, мы сможем вставлять больше кода в нашу программу загрузки, заставляя ее делать более сложные вещи (используя прерывания BIOS, переключение в защищенный режим и прочее.) Следующие части (вторая, третья и пр.) этой статьи станут вашими проводниками на пути усовершенствования кода нашего загрузчика. До встречи!
Termcap
Конечно, любая программа, если она претендует на то, чтобы работать на терминалах разных типов, и не должна знать - как на конкретном терминале очистить экран или какой код выдает клавиша "стрелка вверх".
Для этого в Юниксе существует специальная "база данных свойств терминалов" - termcap. Каждый тип терминала в этой "базе данных" имеет свое название и перечень его "свойств".
Свойствами терминала могут быть
общие характеристики терминала, например
co#80 - количество колонок (в данном случае - 80) li#25 - количество строк (в данном случае - 25) pt - терминал сам отрабатывает код Tab ...
коды, которые нужно выводить на экран для управления курсором, очистки экрана (или части экрана), смены цветов, атрибутов и т.п., например
up=\E[A - как сдвинуть курсор вверх cl=\E[H\E[J - как очистить экран mb=\E[5m - как включить "мерцание" ...
коды, которые выдают "специальные" клавиши терминала, например
k1=\E[M - код от клавиши F1
kD=\177 - код от клавиши Delete
ku=\E[A - код от клавиши "стрелка вверх"
...
Естественно, названия "свойств" (co, li, up, cl, k1, kD ...) являются стандартом, а вот их значения как раз зависят от конкретного типа терминала.
Программа должна
при старте выяснить - как называется терминал, на котором ее запустили, считать из базы данных все свойства этого терминала и в дальнейшей работе "сверяться" с этими данными.
Если ей, например, нужно очистить экран, она должна найти "свойство" cl
и вывести на терминал соответствующую последовательность кодов. А если на ввод от терминала пришла последовательность кодов "Esc[M", она должна найти - какому из "свойств" соответствует эта строчка и, обнаружив, что это - k1, сделать вывод, что пользователь нажал клавишу F1.
Надо сразу заметить, что для выполнения всех этих действий существуют различные библиотеки (ncurses, slang и т.п.). Поэтому, если вы возьметесь писать свою программу (типа редактора), то совсем не обязательно самому делать подробный разбор "свойств" терминала и поиск в них различных клавиш.
Главное, что вам нужно знать - чтобы программы (ваши и чужие) правильно работали с терминалом
нужно "сообщить" программам - как называется ваш терминал в "базе данных" описание "свойств" этого терминала должно точно соответствовать реальным свойствам вашего терминала.
Терминалы
Многие пользователи предпочитают работе мышью работу в терминале, не зря считая ее более эффективной, надежной и быстрой. В нашем дистрибутиве Вы можете выбрать тот терминал, который более всего Вам понравился. А выбор
достаточно широк, начиная от элегантного XTerm и заканчивая красивым ETerm. Обязательно загляните в меню терминалы и попробуйте все возможные варианты, для того, что бы выбрать свой единственный. В терпиналах, которые
входят в русскую редакцию Mandrake Linux, можно без всяких проблем набирать текст на любом поддерживаемом системой языке.
Terminfo
Кроме termcap существует еще одна "база данных свойств терминала" terminfo. Ее назначение точно такое же как и у termcap (просто они "зародились" в разных ветвях Юникса). Отличается она только названиями "свойств" и форматом (termcap
содержит все описания в одном большом текстовом файле, а terminfo хранит каждый тип терминала в отдельном файлике и в двоичном формате).
В стандартной поставке FreeBSD она отсутствует и, как правило, необходимости в ней нет.
Но, если вам придется работать с другими платформами Юникса или какая-нибудь программа пожелает брать данные именно из terminfo (а не удовлетворится termcap'ом), то воспользуйтесь утилитой tconv (смотри man tconv). Она выполняет "конвертирование" из termcap в terminfo и обратно.
Иван Паскаль pascal@tsu.ru
Терминология LVM
VG (volume group) – центральное звено LVM. Группу томов можно понимать как банк дисковых ресурсов. Вкладчиками такого банка является физика, а заёмщиками логика. Все команды для этого уровня именуются vgxxxxx.
PV (physical volume). Под физическим томом следует понимать обычное блочное устройство – целый диск, раздел на диске и т.п. Все команды для этого уровня именуются pvxxxxx.
LV (logical volume). На логических томах фактически размещаются файловые системы. Все команды для этого уровня именуются lvxxxxx.
PE (physical extent). Каждый физический том «нарезан» на части (по умолчанию 4 Mb). Это минимальный размер дискового ресурса, с которым может оперировать VG (вы можете динамически менять размеры логических томов на величину, строго кратную PE).
LE (logical extent). Как и для физики, но взгляд с противоположной стороны (их взаимосвязь называется mapping).
Типы файлов
И в том и в другом формате используются одинаковые "Типы Файлов". Это может быть одно из пяти слов
xkb_keycodes - файл (или блок), в котором числовым значения скан-кодов даются символические имена xkb_types - файл, в котором описываются возможные типы клавиш (тип определяет - сколько различных значений может иметь одна и та же клавиша в зависимости от состояния модификаторов) xkb_compat - файл, в котором описывается "поведение" модификаторов xkb_symbols - основной файл, в котором каждому скан-коду (заданному символическим именем) назначаются все возможные значения, которые может выдавать конкретная клавиша (другими словами - "раскладка клавиатуры"). xkb_geometry - описание расположения кнопок и индикаторов на клавиатуре
Надо отметить, что, если файл состоит из нескольких блоков, то все блоки должны быть одного типа. Отличаются они только именем.
Имя представляет собой произвольное слово в двойных кавычках.
Как можно заметить, в формате заголовка только "ТипФайла" должен присутствовать обязательно, а "Имя" может отсутствовать. Естественно, если файл предствляет собой "простую" конфигурацию или содержит только один блок, то именовать их необязательно. В этом случае, чтобы сослаться в настройках X-сервера на такую конфигурацию достаточно указать имя файла.
Но, если в файле находится несколько блоков, разумеется они должны иметь имена, причем разные. При этом, чтобы сослаться на конкретную конфигурацию, ее указывают в виде
имя_файла(имя_блока)
например,
us(pc104)
/Tmp
Каталог для временных файлов, не имеющих никакого смысла при перезагрузке. Может (и, как я считаю, должен) пересоздаваться во время загрузки системы.
Время последнего доступа к файлу может использоваться для проверки не является ли файл в этом каталоге неиспользуемым (скажем если к файлу не было доступа больше трёх суток и он никем не открыт, то он удаляется), поэтому желательно держать флаг atime.
Запускать файлы из /tmp пытаются некоторые криво написаные программы, если вы с такой встретились ? лучше сделать патч. Если не ставится флаг noexec, то хотя бы nosuid стоять должен.
Файловая система лучше reiserfs ? она лучше всех справляется с большим количеством небольших файлов в одном каталоге.
reiserfs noexec,nodev,atime
Точки повторной обработки
Точки повторной обработки позволяют приложению связать блок своих данных с файлом или каталогом, а диспетчеру объектов Object Manager - выполнить повторный поиск имени, когда прикладная программа обнаруживает точку повторной обработки. Помимо данных в точке повторной обработки хранится программный код, который идентифицирует принадлежность точки повторной обработки определенному приложению. Сами по себе точки повторной обработки бесполезны, но благодаря им программисты могут наращивать функциональность NTFS. В Windows 2000 предусмотрено несколько типов точек повторной обработки, в том числе точки монтирования томов, подсоединения каталогов NTFS и управления иерархическими хранилищами данных (Hierarchical Storage Management, HSM). Я объясню, как работают все эти функции, а затем подробно расскажу о реализации точек повторной обработки.
Любой том NTFS доступен лишь после того, как ему присвоено символьное обозначение. Точки монтирования NTFS5 позволяют привязать том к каталогу монтирования на родительском томе NTFS5, не присваивая символьного обозначения дочернему тому. В результате появляется возможность объединить несколько томов под одной буквой. Например, если смонтировать том, содержащий каталог \articles, к точке монтирования с именем C:\documents, то можно использовать путь C:\articles\documents для доступа к файлам каталога \documents. Точка монтирования представляет собой точку повторной обработки, данные которой состоят из внутреннего имени тома. Внутреннее имя имеет форму \??\Volume{XX-XX-XX-XX}, где X - числа, образующие глобальный уникальный ID (GUID), присвоенный тому операционной системой.
Если открыть файл C:\articles\documents\column.doc, то NTFS обнаруживает точку монтирования, связанную с каталогом \documents. NTFS читает хранящиеся в ней данные точки повторной обработки (имя тома) и передает в Object Manager статус точки повторной обработки. Диспетчер ввода/вывода перехватывает информацию о статусе, анализирует данные и определяет, что NTFS обнаружила точку монтирования. Диспетчер ввода/вывода изменяет искомое имя и заставляет Object Manager (компонент ядра, который отвечает поиску имен) провести повторный поиск с измененным путем \??\Volume{GUID}\documents\column.doc. В процессе повторного поиска анализ имени \documents\co-lumn.doc продолжится на смонтированном томе. Создать точки монтирования и составить их список можно с помощью оснастки Disk Management консоли управления Microsoft Management Console (MMC) или инструмента командной строки Mountvol, поставляемого вместе с Windows 2000.
Точки подсоединения каталогов NTFS похожи на точки монтирования, и диспетчер ввода/вывода и Object Manager выполняют подсоединение так же, как монтирование. Однако точки подсоединения устанавливают связь с каталогами, а не с томами. Точки подсоединения Windows 2000 эквивалентны символьным ссылкам UNIX (но в отличие от символьных ссылок UNIX, точки подсоединения нельзя применять к файлам). Если создать точку подсоединения C:\articles\documents, связанную с каталогом D:\documents, то можно обращаться к файлам в D:\documents, используя путь C:\articles\documents. В точке подсоединения хранится информация о перенаправленном пути, и если NTFS обнаруживает точку подсоединения, то, как и в случае с точкой монтирования, диспетчер ввода/вывода изменяет имя и инициирует повторный поиск имени. Принцип действия точки подсоединения показан на Рисунке 3. Когда приложение открывает C:\directory1\file, NTFS обнаруживает точку повторной обработки в каталоге C:\directory1, указывающую на каталог C:\directory2. Диспетчер ввода/вывода изменяет имя на C:\directory2\file, и приложение в итоге открывает файл C:\directory2\file.
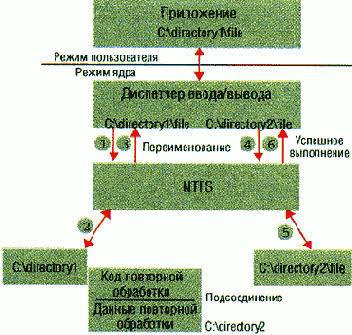 |
| Рисунок 3. Пример точки повторной обработки. |
Повторный анализ пути используется не во всех точках повторной обработки. В системе HSM точки повторной обработки HSM служат для прозрачной миграции редко используемых файлов в резервное хранилище данных. Когда HSM переносит файл в архив, содержимое файла удаляется, а на его месте создается точка повторной обработки. В данных точки повторной обработки содержится информация, используемая системой HSM для поиска файла на архивном носителе. Если впоследствии приложение обращается к хранящемуся в HSM файлу, то HSM-драйвер RsFilter.sys (Remote Storage Filter - фильтр удаленного хранения данных) перехватывает код повторной обработки, пересылаемый NTFS в Object Manager. Драйвер удаляет точку повторной обработки, извлекает файл с архивного носителя, а затем повторяет первоначальный запрос. На этот раз NTFS обращается к файлу, как к любому другому, и операции по перемещению данных не влияют на работу приложения.
Если точка повторной обработки связана с файлом или каталогом, то NTFS создает для нее атрибут с именем $Reparse. В этом атрибуте хранятся код и данные точки повторной обработки. Поэтому NTFS без труда обнаруживает все точки повторной обработки на томе, а в файле метаданных с именем \$Extend\$Reparse хранятся элементы, связывающие номера записи MTF файла и каталога точки повторной обработки с ассоцированными с ними кодами повторной обработки. NTFS сортирует элементы по номеру записи MTF в индексе $R.
Требования
Если одна или несколько таких директорий существует, требования к их содержимому те же самые, что и к обычному каталогу /lib, за исключением того, что /lib<qual>/cpp не требуется.[примечание 13]
[12] Обычно это используется для поддержки 64-битного или 32-битного формата в системах, поддерживающих несколько форматов исполняемых файлов, и требующих библиотек с одним и тем же названием. В этом случае /lib32 и /lib64 могут быть библиотечными каталогами, а /lib - символической ссылкой на один из них.
[13] Наличие /lib<qual>/cpp все же допускается: тем самым допускаются случаи, когда /lib и /lib<qual> есть фактически одно и то же (один из них является символической ссылкой на другой).
Previous: /lib : Основные разделяемые библиотеки и модули ядра
Next: /mnt : Точка монтирования для временно монтируемых файловых систем
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
|
"/opt" <package> |
"Дополнительные пакеты программного обеспечения" Статические объекты пакета |
Дерево 3.12.2.1
Каталоги /opt/bin, /opt/doc, /opt/include, /opt/info, /opt/lib и /opt/man зарезервированы для использования локальным системным администратором. Пакеты могут предоставлять "front-end" файлы, которые локальный системный администратор может разместить в этих зарезервированных каталогах (либо путем копирования, либо установив ссылку), но любой пакет должен нормально функционировать и в случае отсутствия этих зарезервированных директорий.
Программы, вызываемые на исполнение пользователем, должны располагаться в каталоге /opt/<package>/bin. Если пакет ПО содержит в своем составе страницы обычного в UNIX интерактивного руководства man, они должны устанавливаться в каталог /opt/<package>/man, который должен иметь такую же структуру, как и каталог /usr/share/man.
Файлы пакета, которые являются переменными (изменяемыми при выполнении стандартных операций), должны устанавливаться в /var/opt. Дополнительную информацию ищите в разделе о каталоге /var/opt.
Специфичные для хоста конфигурационные данные должны устанавливаться в /etc/opt. Дополнительную информацию ищите в разделе о каталоге /etc.
Никакие файлы пакета не должны размещаться вне каталогов /opt, /var/opt и /etc/opt, кроме тех файлов, которые должны оказаться в других местах по той причине, что иначе пакет не сможет функционировать нормально. Например, файлы блокирования устройств должны располагаться в /var/lock, а файлы устройств должны располагаться в /dev.
Дистрибутивы могут устанавливать программное обеспечение в каталог /opt, но не должны модифицировать или удалять ПО, установленное местным системным администратором, без разрешения этого самого администратора.
Следующие каталоги или символические ссылки на каталоги должны присутствовать в /usr/share
|
"/usr/share" man misc |
"Архитектурно-независимые данные" Он-лайновые руководства Различные архитектурно-независимые данные |
Дерево 4.11.2.1
Следующие каталоги или символические ссылки на каталоги должны иметься в /.
|
"/" bin boot dev etc lib mnt opt sbin tmp usr var |
"Корневой каталог" Основные исполняемые команды Статические файлы для загрузчика Специальные файлы устройств Специфичные для данного хоста конфигурационный данные Основные разделяемые библиотеки и модули ядра Точка монтирования для временно подключаемых файловых систем Дополнительные пакеты программного обеспечения Основные системные утилиты Временные файлы Каталоговая структура второго уровня Переменные данные |
Дерево 3.2.1
Каждый каталог из перечисленных выше подробно рассматривается далее в отдельном разделе. Каждому из каталогов /usr и /var посвящен целый раздел в этом документе в силу сложности этих каталогов.
Previous: Назначение
Next: Рекомендации
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
В каталоге /bin не должно быть подкаталогов.
В /bin должны иметься следующие команды или символические ссылки на соответствующие команды:
| cat | утилита для конкатенации файлов с отображением результата на стандартный вывод |
| chgrp | утилита для изменения атрибута принадлежности файла группе |
| chmod | утилита для изменения прав доступа к файлу |
| chown | утилита для изменения владельцев файла |
| cp | утилита для копирования файлов и каталогов |
| date | утилита для вывода или изменения системной даты и времени |
| dd | утилита для для преобразования и копирования файлов |
| df | утилита, информирующая об использовании дискового пространства в файловых системах |
| dmesg | утилита для вывода сообщений, записанных в буфере ядра |
| echo | утилита для отображения строки текста |
| false | утилита, не выполняющая никаких действий и возвращающая статус завершения "не успешно" |
| hostname | утилита, показывающая или устанавливающая системное имя хоста |
| kill | утилита для посылки сигналов процессам |
| ln | утилита для задания ссылок на файлы |
| login | утилита, открывающая сессию работы пользователя в системе |
| ls | утилита для вывода списка файлов в каталоге |
| mkdir | утилита для создания каталогов |
| mknod | утилита для создания специальных файлов устройств блочного или символьного типов |
| more | утилита для постраничного вывода текста |
| mount | утилита для монтирования файловых систем |
| mv | утилита для перемещения/переименования файлов |
| ps | утилита, возвращающая статус выполняющихся процессов |
| pwd | утилита, возвращающая имя текущего рабочего каталога |
| rm | утилита удаления файлов или каталогов |
| rmdir | утилита удаления пустых каталогов |
| sed | потоковый редактор `sed' |
| sh | командная оболочка Борна |
| stty | утилита для изменения установок или вывода информации об установках терминальной линии |
| su | утилита смены идентификатора пользователя |
| sync | утилита для сброса на диск содержимого буферов кеш-памяти |
| true | утилита, не выполняющая никаких действий и возвращающая статус завершения "успешно" |
| umount | утилита для размонтирования файловых систем |
| uname | утилита для получения информации о системе |
Таблица 3.4.2.1
Если /bin/sh не является настоящей оболочкой Борна, это должна быть жесткая или символическая ссылка на реальную программу оболочки.
Обе команды [ и test должны быть расположены вместе, либо в каталоге /bin, либо в /usr/bin.
В каталоге /etc не должно быть бинарных файлов.
Следующие каталоги или символические ссылки на каталоги должны быть расположены в /etc:
|
"/etc" opt |
"Конфигурационная информация для данного хоста" Конфигурация для /opt |
Дерево 3.7.2.1
Никаких ограничений на внутреннюю структуру каталога /etc/opt/<package> не накладывается.
Если конфигурационный файл должен располагаться в ином месте для того, чтобы пакет или система функционировали должным образом, этот файл может помещаться в каталог, отличный от /etc/opt/<package>.
По крайней мере один из файлов, соответствующих каждому из следующих шаблонов, должен найтись в данном каталоге (это могут быть либо реальные файлы, либо символические ссылки):
| libc.so.* | Динамически подсоединяемые библиотеки C (optional) |
| ld* | Компоновщик/загрузчик времени выполнения (The execution time linker/loader) (optional) |
Таблица 3.9.2.1
Если препроцессор языка Си установлен, /lib/cpp должен быть ссылкой на него, по историческим причинам.[примечание 11]
Внутренний формат для файлов, в которых хранятся идентификаторы процессов (PID), остаются неизменными. Файл должен состоять из идентификатора процесса в коде ASCII, записанном в десятичной нотации, за которым следует символ конца строки. Например, если crond запущен как процесс с номером 25, /var/run/crond.pid будет содержать три символа: два, пять и символ новой строки.
Программы, которые читают PID-файлы, должны быть достаточно гибкими в отношении того, что они воспринимают: то есть они должны игнорировать лишние пробелы, предшествующие ноли, отсутствие завершающего символа новой строки или дополнительные строки в PID-файле. Программы, которые создают PID-файлы, должны использовать простые спецификации, изложенные в предыдущем параграфе.
Файл utmp, в котором хранится информация о том, кто в данный момент использует систему, расположен в этом каталоге.
Программы, которые поддерживают transient UNIX-domain sockets, должны размещать их в этом каталоге.
[37] Непривелигированные пользователи должны быть лишены права записи в каталог /var/run; с точки зрения безопасности предоставление любому пользователю права записи в этот каталог представляет большую угрозу. Файлы с идентификаторами процессов (PID), которые раньше располагались в /etc, должны быть размещены в /var/run. Соглашение об именах этих файлов следующее: <program-name>.pid. Например, PID-файл для демона crond называется /var/run/crond.pid.
Previous: /var/opt : Переменные данные для /opt
Next: /var/spool : Очереди данных для приложений
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
Следующие каталоги или символические ссылки на каталоги должны присутствовать в /usr.
|
"/usr" bin include lib local sbin share |
"Каталоговоая структура второго уровня" Большая часть пользовательских команд Файлы заголовков (header files), включаемые в программы на языке C Библиотеки Каталоговая структура Local (пустая непосредственно после инсталляции системы) Системные утилиты, не являющиеся жизненно-важными (Non-vital system binaries) Архитектурно-независимые данные |
Дерево 4.2.1
Previous: Назначение
Next: Рекомендации
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
Следующие каталоги или символические ссылки на каталоги должны иметься в /usr/local
|
"/usr/local" bin games include lib man sbin share src |
"Каталог для локального ПО" Локальные исполняемые файлы Локально установленные игровые приложения Локальные заголовочные файлы для C Локальные библиотеки Локальные он-лайновые руководства Локальные системные исполняемые файлы Архитектурно-независимые каталоговая структура для локального ПО Локально установленные исходные коды |
Дерево 4.9.2.1
Никаких каталогов, кроме перечисленных выше, не должно быть в /usr/local после первой установки FHS-совместимой системы.
Требования к файловому менеджеру
На мой, разумеется, субъективный, взгляд, файловый менеджер должен обеспечивать удобные средства управления файлами, не более. Но и не менее.
То есть от него нелепо было бы ожидать функций персонального органайзера или развитого текстового редактора. Однако мы вправе расчитывать, что файловый менеджер, вне зависимости от целевой платформы, позволяет просматривать, сортировать по разным параметрам, копировать, перемещать, переименовывать и удалять файлы, а также подкаталоги любой степени вложенности. И делать это простым, наглядным и интуитивно понятным способом.
Для файловых менеджеров на платформе Linux (как и Unix вообще) необходимое условие - эффективное управление правами доступа - смены владельца и группы, разрешение/запрещение на чтение/запись/исполнение и т.д. И желательно, чтобы эту операцию можно было бы осуществлять рекурсивно, включая подкаталоги любого уровня вложенности и содержащиеся в них файлы.
Желательно также, чтобы файловый менеджер имел встроенные средства работы с архивами основных форматов или позволял бы подключать внешние модули для этого. В идеале - чтобы была возможность работы с архивами, как с каталогами, без распаковки: мощности современных машин вполне достаточно, чтобы такая задача была необременительной для процессора.
Это - минимально необходимые функции, без которых применение файлового менеджера неоправданно, проще обойтись средствами оболочки командной строки.
Из роскошного хотелось бы иметь встроенного ftp-клиента или возможность подключения внешнего. Также желательно наличие программ для просмотра файлов наиболее распространенных текстовых и графических форматов. Ну и элементарное редактирование текстовых файлов встроенными или подключаемыми средствами - их наличие стало традицией со времен командира Нортона.
С точки зрения интерфейса все файловые менеджеры можно разделить на две группы - командирского стиля (a la Norton Commander) и Explorer-образные. Какая лучше - однозначно ответить нельзя, определяется сугубо личными привычками и предпочтениями. Мне больше нравится первый, хотя знаю немало людей, у которых вид двух панелей вызывает приступ идиосинкразии. Чрезвычайно ловко, однако, управляющихся с баобабоподобными древами Explorer. Так что, вероятно, мамы всякие нужны, мамы всякие важны. Лишь бы реализовано было хорошо.
Вот с этих позиций я постараюсь рассмотреть несколько файловых менеджеров, с которыми мне довелось пообщаться. Начну со второй группы, поскольку с появлением Windows стиль Explorer стал традиционным для графических сред. А так как нашей первой графической средой в Linux будет, скорее всего, KDE, первыми в этом ряду по справедливости должны стоять штатные
"Третий способ"
Если у вас используется третий способ - через задание "правил", "модели", "схемы".
В этом случае все немного сложнее, поскольку непосредственно xkbcomp не понимает этот способ.
Однако, в этом случае можно "вручную" выполнить преобразование правил/модели/схемы в компоненты настройки (keycodes,symbols и т.п.).
Например, у вас в файле конфигурации написано
XkbRules "xfree86" XkbModel "pc104" XkbLayout "ru" XkbOptions "grp:shift_toggle"
Сначала надо найти файл "правил" (rules). Это будет файл {XKBROOT}/rules/xfree86.
В первой секции, которая после "шаблона"
! model = keycodes geometry
по вашей модели - "pc104" находим название файлов (блоков) для xkb_keycodes
и xkb_geometry. Скорее всего это будет
xkb_keycodes - "xfree86" xkb_geometry - "pc(104)"
Теперь, во второй секции, после "шаблона"
! model layout = symbols
найдем по "модели" - "pc104" и "схеме" - "ru" подходящий файл для xkb_symbols.
Скорее всего, схема "ru" там не упомянута. Но зато есть правило
pc104 * = en_US(pc104)+%l%(v)
где %l надо "заместить" названием "схемы" (layout), а %(v) - названием "варианта".
Поскольку "вариант" у вас не задан, то это правило "развернется" в
xkb_symbols - "en_US(pc104)+ru"
Следующая секция, после "шаблона"
! model layout = compat types
вообще очень простая
* * = complete complete
То есть, независимо от конкретных значений model и layout, и xkb_compat, и xkb_types надо брать из файлов "complete".
Таким образом, для нашего файла полной конфигурации значения
xkb_types - "complete" xkb_compat - "complete"
И, наконец, последняя секция, после "шаблона"
! option = symbols
указывает, что для нашей "опции" - grp:shift_toggle, к уже выбранному файлу для xkb_symbols надо "приплюсовать" еще и блок "group(shift_toggle)"
Теперь не забудьте добавить слова include, скобки в нужном месте и "обрамление" xkb_keymap { ... };
Должно получится
xkb_keymap { xkb_keycodes { include "xfree86" }; xkb_types { include "complete" }; xkb_compat { include "complete" }; xkb_symbols { include "us(pc104)+ru+group(shift_toggle)" }; xkb_geometry { include "pc(pc104)" }; };
Это и есть наша рабочая "полная конфигурация", к которой можно писать "добавки" - исправления/дополнения.
Наконец, надо заметить, что делать все это (и полное описание и фалы-добавки) вы можете в отдельной директории, поскольку xkbcomp при "разборке" include
сначала ищет файла в текущей директории, а только потом в "стандартном" месте - {XROOT}/lib/X11/xkb. Естественно, подразумевается, что мы при экспериментах запускаем xkbcomp, находясь в этой директории.
А вот потом, если вы решите, что "это хорошо", можно будет разложить файлы с исправлениями в соответствующие поддиректории (keycodes, types, symbols
и т.д ) "домашней директории" XKB - {XROOT}/lib/X11/xkb. И подправить файл конфигурации X-сервера так, чтобы он при старте загрузил вашу конфигурацию.
Итак, если вы используете третий способ указания конфигурации XKB, то в файле конфигурации X-сервера, надо задать параметры XkbRules, XkbModel, XkbLayout и, если вам нужно что-то не совсем стандартное - XkbVariant и XkbOptions.
Например,
XkbRules "xfree86" XkbModel "pc104" XkbLayout "ru" XkbVariant "" XkbOptions "ctrl:ctrl_ac"
означает, что XKB должен
в соответствии с правилами, описанными в файле {XKBROOT}/rules/xfree86, выбрать настройки для клавиатуры типа "pc104" (104 кнопки), русского алфавита (английский алфавит будет включен "по умолчанию"), вариант - "стандартный" (то есть, этот параметр можно было не писать) и, наконец, дополнительные опции для вашей "раскладки клавиатуры" - "ctrl:ctrl_aa".
Кстати, что означают различные опции, а также - какие "модели" и "схемы" определены в "правилах" (и что они означают) можно посмотреть в файле xfree86.lst (или другом файле *.lst, если вы выбрали "правила" не xfree86), который находится в той же директории, что и файл "правил", то есть - {XKBROOT}/rules.
Третий способ (через дополнительную переменную номера группы)
Вспомним еще раз - в чем проблема. В том, что основной переключатель должен переходит из одного состояния (текущая группа - Group1), в два разных, в зависимости от состояния какой-то другой клавиши.
Но ведь можно "запомнить" состояние дополнительного переключателя нет только с помощью модификатора.
Напомню, что номер группы может храниться в трех внутренних переменных XKB - locked, latched и base group, значение которых можно менять независимо. Причем для выбора символа у клавиши используется суммарное значение этих переменных - effective group.
Напомню также, что благодаря "методу выравнивания номера группы" (см. "Внутренности":Метод выравнивания..."), если суммарное значение окажется больше, чем количество существующих групп на единицу, то опять получится первая группа и т.д.
Таким образом, можно заставить дополнительный переключатель "запоминать" номер "альтернативной" группы в дополнительной "групповой" переменной, например - base group. А основной переключатель пусть манипулирует значением в другой переменной, например - locked group.
Итак. Пусть дополнительный переключатель запоминает - какая из "русских" групп нам требуется (2 или 3), например, в переменной base group.
Тогда основной переключатель, чтобы перейти из "лат" в из "рус" раскладок должен просто обнулить locked group. А для того, чтобы вернуться обратно в "лат", надо в locked group записать "добавку", достаточно большую, чтобы "метод выравнивания" "завернул" значение обратно к "лат" раскладке.
Таким образом мы нашу проблему (переход из Group1 в два разных состояния) решаем. Правда теперь у на появляется проблема - как вернуться обратно из разных состояний в одно и ту же группу. Но она то, решается очень просто. Поскольку клавиатура при этом находится в разных состояниях (Group2 и Group3), то мы без проблем "подвешиваем" на клавишу два разных "действия", каждое со своим значением "добавки".
Прежде чем переходить написанию конфигурации клавишь, давайте проясним вопрос: что значит "обнулить" переменную с номером группы, и - какие "добавки" нам понадобятся.
Надо сказать об одной тонкости - хотя в "конфигах" группы нумеруются - 1,2,3..., внутри XKB это означает - 0,1,2...
То есть, group1 - на самом деле 0, group2 - 1 и т.д.
Итак. Давайте сначала рассмотрим задачу во внутренних значениях XKB (0,1,2).
Тогда у нас
первая группа ("лат") - 0 вторая группа ("старый рус.") - 1 третья группа ("новый рус.") - 2 максимальный номер группы - 2
При этом
если к 1 добавить 2 - получится снова 0 (3 на единицу больше, чем "максимальный номер группы") аналогично, если к 2 добавить 1 - снова вернемся к группе 0.
Тогда алгоритм работы переключателей мог бы быть таким -
в дополнительной переменной (base group) запоминается номер одной из русских раскладок - то есть, 1 или 2; для того, чтобы перейти из состояния, когда текущая группа "лат", в выбранную "рус", надо просто в locked group записать 0; а для того, чтобы вернуться в "лат" из состояния "рус." надо в переменную base group записать -
2, если текущая группа 1; 1, если текущая группа 2.
Однако, не все так просто. Если мы попытаемся воплотить это в конфигурацию клавиши, то нарвемся на очередную "засаду".
Дело в том, что значения номера группы "запоминаются" только в locked group. В других переменных (base и latched) они "держаться" только пока соответствующая клавиша нажата и "испаряются" оттуда, если клавишу отпустить.
Правда, у нас есть одна "лазейка". Мы можем изменить поведение клавиши (той, что будет менять base group) и сделать ее "залипающей". Тогда XKB при первом нажатии/отжатии клавиши выполнит только ту задачу, которая выполняется при нажатии клавиши, а при повторном нажатии/отжатии наоборот - только то, что выполняется при отжатии клавиши.
Только обратите внимание, что когда мы ее все-таки "отожмем" там получится 0. То есть, мы не сможем держать там "2 или 3", а только "2 или 0", "1 или 0" и т.п.
Ну и ладно. Придется в ней держать не "номер алтернативной раскладки", а только "добавку" к номеру. То есть - не "2 или 3", а "0 или 1".
Тoгда нам придется слегка подправить наш алгоритм -
в дополнительной переменной (base group) запоминается "смещение" от первой "русской" раскладки - 0 или 1; для того, чтобы перейти из состояния "лат", в нужную "рус", надо в locked group записать 1; для того, чтобы вернуться в "лат" из состояния "рус." надо в переменную base group записать -
если текущая группа 1 (в base 0) - 0; если текущая группа 2 (в base 1) - 2.
Теперь, переходя к обозначениям из "конфигов" (group1, group2 и т.д.), получим -
дополнительный переключатель:
ну, 0 или Group1 там получится автоматически при "отжатии" клавиши "запоминать" в base group надо Group2,
основной переключатель:
"действие" для Group1 - записать в locked group значение Group2
для Group2 - записать Group1
для Group3 - записать Group3
Сочиняем описание клавиш (пусть это будут те же <CAPS> и <MENU>)
key <CAPS> { [NoSymbol],[NoSymbol],[NoSymbol], actions[Group1]= [ LockGroup(group=2) ], actions[Group2]= [ LockGroup(group=1) ], actions[Group3]= [ LockGroup(group=3) ] };
key <MENU> { [ NoSymbol ], locks= yes actions[Group1]=[ SetGroup(group=2) ]};
(обратите внимание - мы для дополнительного переключателя опять описываем только одну группу. Все равно он может "перещелкивать" только два состояния, и делать его "чувствительным" к текущей группе нет смысла.)
Можно пробовать.
Правда, надо признаться, что этот метод тоже не лишен недостатков. Если вы начнете менять альтернативную раскладку, когда основной переключатель стоит в положении "какой-нибудь рус." - все будет нормально.
Но вот если "пощелкать" им, когда основной переключатель стоит в состоянии "лат", то результаты будут несколько "странные" (вы можете сами их "просчитать"), поскольку "состояние лат." на самом деле - "хитро" подобранная сумма двух переменных (base и locked).
С другой стороны, с этим можно примириться. Скорее всего в реальной работе вы будете "подгонять" русскую раскладку, когда основной переключатель стоит в сотоянии "рус", а не готовить ее заранее (когда основной переключатель в состоянии "лат").
Замечу также, что это не единственный вариант переключения "с помощью двух переменных group". Можно, например, сделать так, чтобы дополнительный переключатель работал с locked group, а основной - с base group (если посмотреть исходный алгоритм, то там у основного переключателя есть состояние когда он "держит" в "своей" переменной 0). Но этот вариант не лучше в смысле "побочных эффектов", а в описании, пожалуй, сложнее.
Поэтому, пока не этом и остановимся.
Тем более, что у нас остался еще -
Третий способ - самый правильный
Еще один способ описан в "Примеры: Новая 'старая' раскладка".
В нем вводятся две русские раскладки - одна для "неправильных" программ, другая - для "правильных".
Эту раскладку можно положить в X11R6/lib/X11/xkb/symbols, переименовав ее в ru (или подправить название русской раскладки в других файлах конфигурации XKB).
Тогда клавиша "переключатель групп" будет циклически перебирать три группы, что конечно же не очень-то удобно в работе. Чтобы "облегчить жизнь", можно воспользоваться моим индикатором-переключателем клавиатуры xxkb . (Для работы с тремя раскладками надо немного изменить настройки xxkb. Об этом подробно написано в соответствующей инструкции .)
Как я уже заметил, этот способ - самый правильный. "Правильные" программы будут работать с "правильной" раскладкой (если вы настроите xxkb, то эта раскладка будет включаться "по умолчанию"), а для "неправильных" программ вам придется при старте такой программы выбрать "неправильную" раскладку. В этом есть, конечно, некоторые неудобства, но xxkb
сведет их к минимуму.
Иван Паскаль pascal@tsu.ru
Три способа задания полной конфигурации XKB
Весь набор компонентов, необходимых для настройки XKB, описывается в файле конфигурации X-сервера в секции Keyboard.
Трюки BSD - Memory File System
Автор: Станислав Лапшанский, slapsh@kos-obl.kmtn.ru
Опубликовано: 19.02.2002
Оригинал: http://www.softerra.ru/freeos/16111/
Статья является переводом текста Майкла Лукаса (Michael Lucas)
Файловая система MFS (Memory File System – файловая система в оперативной памяти) позволяет создавать виртуальный диск используя оперативную память вашего компьютера. Тем самым вы можете использовать память системы так же как жесткий диск. Вы можете записывать файлы на виртуальный диск так же как на любой жесткий диск вашей системы.
Поскольку файлы на MFS-диске уже находятся в памяти, к ним возможен доступ память-память. Это намного быстрее чем доступ диск-память. Однако как и в случае с оперативной памятью, вы теряете все данные на таком диске, когда выключаете компьютер.
Вы можете использовать MFS для реализации виртуального диска на бездисковых рабочих станциях. Некоторые администраторы используют MFS-диски для хранения history-файлов news-серверов, добиваясь тем самым существенного прироста их производительности. Использование MFS-диска в качестве хранилища lock-файлов систем управления базами данных также может значительно повысить производительность многих операций.
Вы также можете использовать MFS для создания временного виртуального диска для частой компиляции программ, архивации/разархивации или для манипуляций с большими количествами небольших файлов. Однако это не всегда является хорошей мыслью – если на вашей системе не установлено достаточного количества памяти, то MFS-диск легко сможет поставить ее «на колени».
Если памяти достаточно, то вы, например, можете смонтировать MFS-диск в каталоге /usr/obj; вы еще не видели как быстро будет выполнена команда "make world".
Все BSD-подобные системы поддерживают MFS. Я использую FreeBSD в качестве примера. Однако несмотря на то, что команды для организации MFS-дисков в NetBSD и OpenBSD должны быть похожи, я думаю что вам следует обратиться к man-руководству и документации по компиляции ядра этих систем прежде чем двигаться с нами дальше.
После монтирования MFS-диск будет пустым. Вы можете скопировать туда нужные вам файлы или оставить его чистым, как например раздел /tmp.
MFS-диск будет эффективен в случае, когда свопинг системы регулярен. Ядро FreeBSD сохраняет часто используемую информацию в памяти, перемещая реже используемые данные в своп. Такое поведение великолепно подходит для разделов типа /tmp, где доступ к маленьким часто используемым файлам будет осуществляться очень быстро, в то время как большие файлы, которые обычно используются реже и поэтому находятся в своп-файле, будут доступны со скоростью похожей на обычную UFS-систему.
Можно даже использовать MFS-диск большего размера чем физическая оперативная память вашего компьютера. В этом случае MFS будет использовать своп. Это позволяет вам временно разархивировать крупные файлы на такой диск. FreeBSD позволит вам создать MFS-диск большего размера чем общий объем физической и виртуальной (своп) памяти, при попытке использовать который вы можете столкнуться с серьезными проблемами.
MFS как и UFS не может быть загружаемым модулем. Для использования MFS необходимо перекомпилировать ядро с включенными следующими опциями: option MFS #Memory File Sysytem
Теперь скомпилируйте и установите ядро. Перезагрузитесь.
Вы можете монтировать MFS-диск на этапе загрузки. Во- первых узнайте как называется партиция отведенная под своп: grep swap /etc/fstab /dev/ad0s1b none swap sw 0 0
На моей машине это ad0s1b. Если у вас несколько своп-партиций, выберите какую-нибудь одну.
Добавьте похожую строку в /etc/fstab: /dev/ad0s1b /var/db/lockfiles mfs rw 0 0
Вы можете выбрать любые другие стандартные параметры монтирования (см. man 8 mount). Обычно добавляют параметры nosuid, nodev и async. Параметр async не уменьшает надежность системы при использовании его с MFS, в отличии от других файловых систем: в случае краха системы вам так или иначе придется заполнять MFS-диск данными.
В можете смонтировать MFS-диск и после загрузки. Просто укажите точку монтирования и выполните команду mount_mfs: mount_mfs -s 655360 /dev/ad0s1b /usr/obj
Этой командой мы смонтировали 320МБ файловую систему в каталоге /usr/obj. Вы потеряете содержимое этого каталога при перезагрузке, но если вы всегда выполняете операцию сборки цели world с нуля и у вас уже настроен /etc/fstab, то это не проблема.
Флаг -s устанавливает максимальный размер партиции в 512КБ блоках. Если вы хотите создать MFS-диск ограниченный объемом доступной памяти, вы можете пропустить этот флаг. Однако это может создать вам впоследствии определенные проблемы, так что будьте уверены, что это именно то что вам нужно.
Следует отметить один нюанс связанный с монтированием MFS-дисков – этот процесс скрывает все файлы в точке монтирования (это замечание относится к монтированию вообще, применительно к любой файловой системе – примечание переводчика). Например если вы монтируете MFS-диск на каталог /tmp, содержащий файлы, то после монтирования эти файлы не будут доступны системе. Если вы запущенная программа рассчитывает иметь доступ к некоторым файлам в /tmp (скажем как X'ы), это может вызвать некоторые проблемы. Когда вы размонтируете MFS-диск, файлы станут видны вновь. Существует способ видеть одновременно оба набора файлов, если использовать объединенное монтирование, но реализация объединенного монтирования FreeBSD пользуется дурной славой и обладает серьезными проблемами.
Правильно использованная MFS может добавить производительности вашей системе. Неаккуратно использованная, она может привести к разнообразным проблемам. Наслаждайтесь.
Вниманию вебмастеров: использование данной статьи возможно только в соответствии
с правилами использования материалов сайта «Софтерра» (http://www.softerra.ru/site/rules/)
Type
Определяет тип клавиши. Справа от присваивания должно стоять название одного из типов, определенных в файле xkb_types.
Обратите внимание, поскольку разные группы могут иметь разные типы (напомню, что тип определяет количество уровней в группе), то это описание в общем случае должно иметь вид
type[ номер_группы ] = название_типа,
например,
type[ Group1 ] = "ONE_LEVEL", type[ Group2 ] = "ALPHABETIC",
Но, если все группы имеют одинаковое количество уровней и относятся к одному типу, то указание группы (вместе с квадратными скобками) можно пропустить. Например,
type = "ALPHABETIC",
Надо заметить, что для всех клавиш, внутри XKB имется значения типа "по умолчанию". Поэтому, как правило, тип клавиши (группы) не указывется.
Участники разработки
| Brandon S. Allbery | <address omitted> |
| Keith Bostic | <address omitted> |
| Drew Eckhardt | <address omitted> |
| Rik Faith | <address omitted> |
| Stephen Harris | <address omitted> |
| Ian Jackson | <address omitted> |
| John A. Martin | <address omitted> |
| Ian McCloghrie | <address omitted> |
| Chris Metcalf | <address omitted> |
| Ian Murdock | <address omitted> |
| David C. Niemi | <address omitted> |
| Daniel Quinlan | <address omitted> |
| Eric S. Raymond | <address omitted> |
| Rusty Russell | <address omitted> |
| Mike Sangrey | <address omitted> |
| David H. Silber | <address omitted> |
| Thomas Sippel-Dau | <address omitted> |
| Theodore Ts'o | <address omitted> |
| Stephen Tweedie | <address omitted> |
| Fred N. van Kempen | <address omitted> |
| Bernd Warken | <address omitted> |
Таблица 7.6.1
Previous: Благодарности
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
Удаление повторяющихся строк при помощи uniq
Автор - Jacek Artymiak, 20.04.03. Перевод - Валерий Абросимов.
Повторяющие строки не часто становятся проблемой, но иногда это так. И когда это происходит, требуется дополнительная работа для их отфильтровки. Утилита uniq в этом деле очень полезна. Посмотрите, как вы можете сэкономить свое время и избежать головной боли.
После сортировки текстового файла вы можете заметить, что некоторые строки повторяются. Иногда эта повторяющаяся информация не нужна и может быть удалена для сохранения места на диске. Строки в файле не обязательно сортировать, но вы должны помнить, что uniq сравнивает строки по мере прочтения и удаляет только две или больше соседних строк. Следующие примеры показывают как это работает на практике:
Листинг 1. Удаление сдвоенных строк при помощи uniq
$ cat happybirthday.txt
Happy Birthday to You!
Happy Birthday to You!
Happy Birthday Dear Tux!
Happy Birthday to You!
$ sort happybirthday.txt
Happy Birthday Dear Tux!
Happy Birthday to You!
Happy Birthday to You!
Happy Birthday to You!
$ sort happybirthday.txt | uniq
Happy Birthday Dear Tux!
Happy Birthday to You!
Помните, что это плохая идея - использовать uniq или другие утилиты для удаления повторяющихся строк в файлах, содержащих финансовую или другую важную информацию. В таких файлах повторяющиеся строки обозначают ещё один перевод денег на тот же счет и удаление их может привести к проблемам в отношениях с налоговыми органами. Не делайте этого!
Что, если вы хотите сделать свою работу проще и вывести только уникальные или только повторяющиеся строки из файла? Вы можете сделать это при помощи опций -u (unique) и -d (duplicate):
Листинг 2. Применение опций -u и -d
$ sort happybirthday.txt | uniq -u
Happy Birthday Dear Tux!
$ sort happybirthday.txt | uniq -d
Happy Birthday to You!
Вы можете также получить некоторую статистику при помощи опции -c:
Листинг 3. Использование опции -c
$ sort happybirthday.txt | uniq -uc
1 Happy Birthday Dear Tux!
$ sort happybirthday.txt | uniq -dc
3 Happy Birthday to You!
Сравнение целых строк очень полезно, но это - не последняя возможность этой команды. Очень хороша возможность пропускать указанные при помощи опции -f поля. Это может пригодиться при просмотре системных логов. Использование простой uniq не будет работать, так как каждая строка имеет свою отметку времени. Но если вы укажете uniq пропустить все поля времени, то, неожиданно, ваш лог станет гораздо более понятным. Попробуйте uniq -f 3 /var/log/messages и убедитесь сами.
Есть еще одна опция -s, которая работает так же, как и -f, но пропускает указанное количество символов. Вы можете использовать -s и -f вместе. Сначала удалите поля, а затем символы. А что, если вы захотите увидеть строки, только с данными символами? Попробуйте опцию -w.
Вы можете узнать гораздо больше об этой утилите если откроете окно терминала и введете команду man uniq или info uniq, либо запустите браузер и просмотрите man-страницу uniq на gnu.org.
Источник - LinuxBegin.ru
http://linuxbegin.ru
Адрес этой статьи:
http://linuxshop.ru/linuxbegin/article295.html
Универсальная индексация
Некоторые новые свойства NTFS5 основываются на фундаментальной особенности NTFS, именуемой индексацией атрибутов (attribute indexing). Индексация атрибутов заключается в сортировке элементов с атрибутом определенного типа при помощи эффективного механизма хранения, обеспечивающего быстрый просмотр. В версиях NTFS, предшествовавших Windows 2000, индексация допускалась только для индексного атрибута $I30, в котором хранятся элементы каталога. В процессе индексации атрибутов элементы каталога сортируются по имени и сохраняются в B+ дереве (форма двоичного дерева, в каждом узле которого хранится несколько элементов). На Рисунке 1 показана запись MFT каталога, в трех узлах которой содержится девять элементов, по три в каждом узле. Корень B+ дерева находится в атрибуте index root (корень индекса). В записи MFT каталога девять элементов не умещается, поэтому некоторые элементы приходится хранить в другом месте. Для этого NTFS выделяет два буфера размещения индексов (index allocation) для хранения двух записей (как правило, корень индекса и буферы размещения индексов мо-гут хранить элементы для более чем трех файлов, в зависимости от длины имен). Размер записи MFT - 1 Кбайт, а размер буферов размещения индексов - 4 Кбайт.
Красные стрелки указывают, что элементы NTFS хранятся в алфавитном порядке. Если запустить программу, которая открывает файл e.bak в показанном на рисунке каталоге, то NTFS читает атрибут индексного корня, содержащий элементы для d.new, h.txt и i.doc, и сравнивает строку e.bak с именем первого элемента, d.new. NTFS делает вывод, что алфавитный номер e.bak больше, чем d.new, и переходит к следующему элементу - h.txt. Повторив операцию сравнения, NTFS выясняет, что алфавитный номер e.bak меньше, чем h.txt. Затем NTFS отыскивает в записи каталога h.txt номер виртуального кластера (virtual cluster number, VCN) индексного буфера, содержащего элементы каталога, алфавитные номера которых меньше, чем h.txt, но больше, чем d.new. VCN представляет собой порядковый номер кластера в файле или каталоге. На основании информации о размещении кластеров NTFS преобразует VCN в логический номер кластера (Logical Cluster Number, LCN), т. е. номер кластера относительно начала тома. Если элемент каталога для h.txt не содержит VCN индексного буфера, NTFS делает вывод, что каталог h.txt не содержит файла e.bak и сообщает о неудачном завершении поиска.
Получив VCN начального кластера индексного буфера, NTFS читает буфер размещения индексов и просматривает его в поисках совпадений. На Рисунке 1 первый же элемент индексного буфера совпадает с критерием поиска, и NTFS читает номер записи MFT e.bak из элемента каталога e.bak. В элементах каталога хранится и другая информация: в частности, временные отметки (например, время создания и последнего изменения), размер и атрибуты. NTFS хранит эту информацию и в записи MFT файла, но, благодаря дублированию информации в элементе каталога, читать запись MFT файла при составлении списков каталогов и выполнении простых файловых запросов не требуется.
Элементы каталогов сортируются по алфавиту, и именно поэтому в списках каталогов NTFS файлы всегда располагаются в алфавитном порядке. В отличие от NTFS, FAT не сортирует каталог, поэтому списки FAT не сортированы. Кроме того, поскольку элементы NTFS хранятся в B+ дереве, механизм поиска конкретных файлов в больших каталогах очень эффективен; обычно достаточно просмотреть лишь часть каталога. Данный подход отличается от линейного метода FAT, при использовании которого для поиска одного имени иногда приходится просматривать весь каталог.
В версиях NTFS, предшествовавших Windows 2000, индексировались только имена файлов, но NTFS5 обеспечивает универсальную индексацию, сохраняя в индексах произвольные данные и сортируя элементы данных не по имени, а по другим параметрам. Универсальная индексация используется для управления дескрипторами безопасности, информацией о квотах, точках повторной обработки и идентификаторах файловых объектов, т. е. элементами NTFS5, о которых идет речь в данной статье.
Unixfaq
Unix FAQ
Источник: http://nix.h1.ru
Автор: Master
email: tvo@fromru.com
icq: 2362641
Составлено на основе дискуссий в форумах, списках рассылок и личной переписки.
Q: Как монтировать CD-ROM диски и дискеты не набирая каждый раз длинных строчек ?
A: Файл $HOME/.bashrc :
alias cdrom="mount -t auto /dev/hdb /mnt/cdrom"
alias ucdrom="umount /mnt/cdrom"
alias floppy="mount -t auto /dev/hd0 /mnt/floppy"
alias ufloppy="umount /mnt/floppy"
Теперь достаточно набрать cdrom - для монитрования CD-ROM'а, ucdrom - для размонитрования CD-ROM'а, floppy - для монитрования дискеты и ufloppy - для размонитрования дискеты.
Q: Как инсталировать и деинсталировать софт с помощью RPM ?
A: Install: rpm -ivh desired_program.rpm
Uninstall: rpm -e desired_program.rpm
Upgrade: rpm -Uvh desired_program.rpm
Info: rpm -qip desired_program.rpm
Полезные ключи:
--force - забить на сообщения
--nodeps - не проверять зависимости
--replacefiles - заменять все старые файлы на новые не переименовывая их в .rpmsave
Q: Как сделать чтобы после входа в систему с определенной консоли запускались Х-ы ?
A: Файл $HOME/.bash_profile :
if [ `tty` = '/dev/ttyN' ]; then
startx
fi
где N - номер консоли.
Q: Как монтировать FATxx, чтобы были русские имена и файлы были не исполняемыми ?
A: Linux: чтобы были русские имена, необходимо при компиляции ядра не забыть добавить поддержку Native Language Support (NLS).
make [x,menu]config =>
CONFIG_FAT_FS=y
CONFIG_NLS=y
CONFIG_NLS_CODEPAGE_866=y
CONFIG_NLS_KOI8_R=y
CONFIG_MSDOS_FS=y
CONFIG_VFAT_FS=y
Монтировать директории с FATxx следует так:
mount -t vfat-ouser,codepage=866,iocharset=windows-1251,noexec,conv=auto /dev/xxx /xxx
или просто добавить в файл /etc/fstab строку:
/dev/xxx /xxxvfatuser,codepage=866,iocharset=koi8-r,noexec,conv=auto 0 0
FreeBSD: добавить в файл /etc/fstab строку:
/dev/sd0s1 /dos/c msdosrw,-W=koi2dos,-L=ru_RU.KOI8-R 0 0 детальное описание опций -W и -L смотрите в mount_msdos (8)
Q: Какую видеокарту выбирать при покупке, чтобы c Х-ами проблем не было ?
A: В принципе, если карта поддерживает стандарт VESA2 - то по идее проблем с графикой вообще не должно быть - включаем frame buffer и в качестве X-сервера выбираем XServ_FBDev
Хорошо бы на чипе той фирмы, которая сама пишет драйвы (Х-сервера) для видеокарт. Например, NVidia.
Q: Как установить Linux на UDMA66 винт подключенный к UDMA66 контролеру ?
A: См. Linux+UDMA66
Q: Как правильно чистить /tmp ?
A: В дистрибутиве RedHat и основанных на нем для этого существует утилита tmpwatch, которая обычно запускается cron'ом. Для отчистки /tmp можно рубить так:
tmpwatch 1 /tmp
Q: Как отключить сохранение дампа памяти при сбоях ?
A: В файл $HOME/.bash_profile добавьте строку:
ulimit -c 0
Q: Как запретить загрузку Linux со специальными параметрами ?
A: Можно поставить пароль на загрузку со специальными параметрами. В /etc/lilo.conf добавляем в соответствующем разделе:
restricted password=MyPassword
Q: Как отформатировать дискету ?
A: fdformat /dev/fd0H1440
mkfs -t fat16 -m 0 /dev/fd0H1440 1440
Q: Как примонтировать CD, чтобы файлы были с правами -r--r--r-- ?
A: Linux: mount -t iso9660 -oro,noexec,mode=0444,iocharset=koi8-r /dev/cdrom /mnt/cdrom
Q: Как заставить работать win-модем под Линуксом ?
A: См. www.linuxdoc.org/HOWTO/Winmodems-and-Linux-HOWTO.html, http://www.linmodems.org/, http://www.close.u-net.com/
Q: Kак пpавильно чистить логи ?
A: cat /dev/null > log_file
Eсли просто удалить лог, он yдалится только в каталогe. Hа диске он удалится только тогда, когда файл закроют. Полyчаeм ситyацию, когда файл для логов есть, а syslogd в него не пишет. Поэтомy лог надо чистить так, чтобы обнулить (укоротить) уже открытый файл, а не создавать новый.
Q: Как сделать, чтобы ls --color был по умолчанию ?
A: Файл $HOME/.bashrc :
alias ls="ls -F --color=yes"
Q: Как по core оределить ее автора ?
A: size core
gdb -c core
file core
Q: Как узнать, что находится в памяти ?
A: top -n 99999 | less
-n это non-interactive mode, а 99999 - число пpоцессов для показа (вместо default, котоpый обычно 20).
Q: Как убрать beep'ы компьютера ?
A: В консоли Linux: вводим или добавляем в один из стартовых скриптов:
setterm -bfreq 0
В X-ах: в начало файла $HOME/.xinitrc добавляем строку:
xset -b
Если его нет в вашем домашнем каталоге, то используем системный:
/usr/X11R6/lib/X11/xinit/xinitrc
Копируем его в свой домашний каталог с именем .xinitrc и редактируем.
ЗЫ: Пользователи KDE или Gnome могут изменить значение уровня beep на ноль в центре управления (control center).
Q: Как удалить файл командой rm у которого перевый символ имени "-" ?
A: rm ./-name
Q: Как русифицировать консольный редактор joe ?
A: Вначале руссифицируется консоль (консоли в разных системах руссифицируются по разному). Потом редактируем конфигурационный файл. Находится он в каталоге /usr/local/lib, /usr/local/lib/joe или /etc/joe, в зависимости от используемой системы. Копируем файл joerc в свой домашний каталог и переименовываем в .joerc - именно этот файл ищется в первую очередь при загрузке редактора. В первой строке пишем:
-asis
Q: Как включить мышку под левую руку ?
A: Чтобы мышка в X стала заточенной под левую руку нужно подать команду
xmodmap -e "pointer = 3 2 1"
Чтобы при каждом запуске X-ов не вводить эту команду, открываем файл $HOME/.Xmodmap (настройки пользователя для клавиатуры и мышки зачитываются из него), если его нет, то копируем системный /usr/X11R6/lib/X11/xinit/.Xmodmap в свой домашний каталог и добавляем строку:
pointer = 3 2 1
ЗЫ: Пользователи KDE или Gnome могут изменить порядок кнопок на мышке в центре управления (control center).
Q: Linux не видит все 128 Mb RAM (только 64). Как заставить видеть остальное ?
A: Если используется LILO:
В файле lilo.conf в число команд варианта загрузки операционной системы добавить:
append="mem=128M"
Например:
image=/boot/vmlinuz
label=Linux
root=/dev/hda3
append="mem=128M"
Если используется GRUB:
В файле /boot/grub/menu.lst в строку выбора ядра операционной системы для загрузки добавить:
mem=128m
Например:
title Linux
kernel (hd0,2)/boot/vmlinuz root=/dev/hda3 mem=128m
Если используется loadlin:
В файле linux.bat в строку запуска loadlin добавить:
mem=128m
Например:
c:\loadlin\loadlin c:\loadlin\bzImage root=/dev/hde7 mem=128m ro vga=-1
js=0
js=1
js=2
js=3
HotLOG(995,js)
УПРАВЛЕНИЕ БАЗОЙ ДАННЫХ ВРУЧНУЮ
Помимо сценария OpenLDAP поставляется с некоторыми инструментами для работы с базой данных.
Для того чтобы добавить новую запись вручную, в файл /tmp/add.tmp следует поместить что-нибудь вроде нижеприведенного:
| dn: | uid=ftpfoo, dc=my-domain, dc=com |
| objectclass: | ftpAccount |
| uid: | ftpfoo |
| cn: | www.foobar.com |
| homeDirectory: | /home/vhosts/www.foobar.com/ |
| userPassword: | {crypt}AaBbCcDdEeFfg |
Данный пример составлен для виртуального сервера Web www.foobar.com с доступом через ftp по учетной записи ftpfoo. Пароль хранится в шифрованной форме, но, вместо этого, вы можете использовать обычный текст, предварив его ключевым словом {clear}. (Некоторые вопросы, связанные с данной конфигурацией, мы обсудим ниже.)
Далее активизируем ldapadd:
ldapadd -D «cn=Admin, dc=your-domain, dc=com « -w <Пароль> -f \ /tmp/add.tmp
Параметр -D должен ссылаться на пользователя с правом добавления данных. В типичном случае этот параметр идентичен параметру rootdn, который пояснялся ранее при описании файла slapd.conf. Далее, параметр -W — это пароль для пользователя rootdn, который хранится в rootpw.
Такая команда выполняет добавление записи в базу данных от имени пользователя Admin, которому предоставлены требуемые права.
Уничтожить запись еще проще. Следующая команда удаляет запись, созданную предыдущей строкой.
ldapdelete -D « cn=Admin, dc=your-domain, dc=com « -w <Пароль> \ «Uid=ftpfoo»
Для получения более подробной информации об этих командах (и о команде ldapmodify) используйте документацию.
Управление драйвером syscons
Для изменения настроек syscons в системе существуют две утилиты - vidcontrol и kbdcontrol. Как понятно из их названий, первая меняет параметры, относящиеся к изображению на дисплее, а вторая - настройки клавиатуры.
Описание этих утилит можно найти в соответствующих man'уалах. Я только кратко опишу их основные возможности (в разделах "Программа vidcontrol" и "Программа kbdcontrol").
Надо заметить, что обычно основные настройки syscons (русификация, тип курсора, "скринсейвер" и т.п.) делаются во время загрузки системы в соответствующем "стартовом скрипте" (/etc/rc.i386), а параметры, которые им требуются, прописываются в /etc/rc.conf.
Поэтому, вы можете поэкспериментировать с настройками, запуская эти утилиты вручную, но "глобальные" изменения лучше делать редактированием соответствующих строчек в /etc/rc.conf.
Управление файлами
cp источник назначения
Копируем файлы. Например, cp /home/stan/existing_file_name . Скопирует файл в мою текущую рабочую директорию. Используйте параметр "-R" (то есть "recursive(рекурсивно)") для копирования дерева директорий, например , cp -R my_existing_dir/ ~ Скопирует поддиректории текущей директории в мою домашнюю директорию.
mcopy откуда куда
Копирует файлы из/в файловую систему DOS (без монтирования последней). Например, mcopy a:\autoexec.bat ~/junk. Смотрите man mtools для информации о других командах доступа к файлам DOS без монтирования: mdir, mcd, mren, mmove, mdel, mmd, mrd, mformat .... Мы не часто используем команды mtool -- операции с файлами DOS / MS Windows могут быть выполнены при помощи обычных команд Linux после монтирования файловых систем DOS/MS Windows.
mv откуда куда
Перенести или переименовать файл. Одна команда предназначена для переноса и переименования файлов и директорий.
rename строка строка_замены имя_файла
Гибкая утилита для замены части имени файла. Например:
rename .htm .html *.htm
ln откуда куда
Создает жесткую ссылку, называемую куда к файлу, называемому откуда. Ссылка выглядит как копия исходного файла, но в действительности существует только один экземпляр файла, но с двумя (или более) входными точками. Соответственно, любые изменения в файле видны сразу с двух точек. Когда одна из ссылок удаляется, другая(другие) останется(останутся) нетронутыми. На жесткие ссылки есть следующие ограничения: файлы должны принадлежать одной файловой системе, жесткие ссылки на директории и специальные файлы невозможны.
ln -s откуда куда
Создать символьные (мягкие) ссылки, называемые "куда" на файл называемый "откуда". Символьная ссылка просто обозначает путь для поиска "настоящего" файла. В отличие от жестких ссылок, файл и ссылка на него не должны принадлежать одной и той же файловой системе. По сравнению с жесткими ссылками у символьных ссылок есть следующие недостатки: если "настоящий" файл удалить, ссылка "ломается" -- она указывает в никуда; символьные ссылки позволяют создавать циклические ссылки (такие же, как иногда появляются в электронных таблицах и базах данных, например, "a" указывает на "b" и "b" указывает на "a"). Короче, символьные ссылки - это замечательный, хотя и редко используемый, инструмент (реже, чем жесткие ссылки), но они могут создать дополнительный уровень сложности.
rm files
Удаляет файлы. Вы должны быть владельцем файла (или обладать правами "root"). В большинстве систем, у вас спросят подтверждения на удаление; чтобы избежать этого, используйте флаг "-f" (=force(форсировать)), например, rm -f * удалит все файлы из вашей текущей рабочей директории, без всяких вопросов.
mkdir директория
Создать новую директорию.
rmdir директория
Удалить пустую директорию.
rm -r files
(рекурсивное удаление) Удаляет файлы и директории, вместе с их поддиректориями. Поосторожнее с этой программой, если у вас права "root" -- вы легко можете удалить сразу же все файлы вашей системы, и, заметьте, никаких утилит восстановления удаленных файлов в Linux нет (по крайней мере пока). Но если вам действительно хочется знать, как сделать это (на всякий случай), то вот как это делается (под root):
rm -rf /*
rm -rf files
(Рекурсивное удаление без вопросов). То же что и выше, но без вопросов. Осторожнее с этим, особенно с правами "root" -- см. выше.
mc
Загружает файловый менеджер "Midnight Commander" (выглядит как "Norton Commander" для Linux). По мнению некоторых компьютерных динозавров, это - самый лучший файловый менеджер.
konqueror &
(в X-терминале) загружает файловый менеджер KDE. Возможно, это - лучший файловый менеджер. Гораздо лучше чем MS "Windows Explorer". Он поддерживает просмотр Internet, просмотр pdf, и более. Просто здорово.
xwc
(в X-терминале). Другой прекрасный файловый менеджер (называемый также "X Win Commander"). Быстрее чем предыдущий, но не так нагружен возможностями.
nautilus &
(в X-терминале). Действительно хорош. Медленнее чем Konqueror, но дает мне возможность предварительного просмотра содержимого файлов(!). Он даже "предварительно просматривает" содержимое звуковых файлов! Требовательный к скорости, он замечательно работает на моем 1.33 GHz компьютере, но я не могу использовать его на компьютере с процессором 133MHz.
Управление процессами в Linux
Автор: Денис Колисниченко, dhsilabs@mail.ru
Опубликовано: 05.02.2002
Оригинал: http://www.softerra.ru/freeos/15721/
Процессы. Системные вызовы fork() и exec(). Нити.
Перенаправление ввода/вывода
Команды для управления процессами
Материал этой статьи ни в коем случае не претендует на полноту. Более подробно о процессах вы можете прочитать в книгах, посвященных программированию под UNIX.
Управление жесткими дисками и работа со сменными носителями
Естественно, никакая инсталляция операционной системы не обойдется без дисковых накопителей в той или иной форме. Поэтому VMWare при создании виртуальной машины сразу же создает виртуальный жесткий диск, после чего вы можете добавить еще какое-то их количество. Размер этого диска по умолчанию — 4 Гб, но этот размер просто изменить. С точки зрения аппаратной части, этот диск может быть привязан к любому каналу IDE или SCSI — но если вы хотите изменить эти настройки, то делайте это до инсталляции операционной системы, поскольку впоследствии не все системы правильно поймут перестановку диска с одного шлейфа на другой.
С жесткими дисками связано три возможности. Во-первых, файл жесткого диска можно, подобно физическому устройству, «извлечь» из ВМ — то есть сохранить, переписать на другую систему и потом подключить, воссоздав тем самым ВМ в первозданном виде.
Другая возможность — настроить «откат» изменений на диске. Обычно ваши изменения будут храниться на диске так же, как это происходит на обычном компьютере. Режим отката позволяет работать с системой, но после перезагрузки все изменения на диске будут утеряны. Существует также промежуточный вариант, то есть при выключении ВМ будет задан вопрос, сохранить ли изменения.
Наконец, третий вариант — при создании машины сделать не виртуальный диск в файле, а отвести под диск настоящий раздел. Это несколько трудоемкий и не очень эффективный метод. Его назначение, как я понял,- установить ВМ, настроить систему в виртуальном режиме, после чего перенести жесткий диск с настройками на другой компьютер и запускать систему в собственном режиме.
Несколько другая ситуация со сменными носителями. Самое главное отличие — это то, что под VMWare они могут использоваться одновременно и ВМ, и хостом. При этом несколько виртуальных машин тоже разделяют одно устройство, так что никаких проблем не возникает. Кроме того, в VMWare есть возможность вместо физического устройства использовать образ диска — как ISO для CD-ROM, так и образа флоппи-диска для соответствующего юнита.
Под VirtualPC все сделано слабее. Сменные носители монтируются, подобно тому как это происходит в Unix. После того как диск примонтирован, он захватывается ВМ и из других систем не доступен. Если пользователь извлекает носитель, устройство автоматически освобождается — и ВМ теряет его. С этим был связан кошмарный глюк, над которым я бился добрых пять секунд: при инсталляции двухдисковой инсталляции, например ASP Linux, после установки первого диска я вставил второй, но система отказывалась его видеть. Смысл оказался в том, чтобы щелкнуть правой кнопкой на маленькой пиктограмме в строке состояния и снова захватить CD ROM.
Управляющие ("контроловые") символы
Названия управляющих символов, которые можно использовать в таблице раскладки клавиатуры.
код названиеклавиша "по умолчанию"| 0 | nul | [Ctrl]+[@] |
| 1 | soh | [Ctrl]+[A] |
| 2 | stx | [Ctrl]+[B] |
| 3 | etx | [Ctrl]+[C] |
| 4 | eot | [Ctrl]+[D] |
| 5 | enq | [Ctrl]+[E] |
| 6 | acq | [Ctrl]+[F] |
| 7 | bel | [Ctrl]+[G] |
| 8 | bs | [Ctrl]+[H] или [Backspace] |
| 9 | ht | [Ctrl]+[I] или [Tab] |
| 10 | lf или nl | [Ctrl]+[J] или [Ctrl]+[Enter] |
| 11 | vt | [Ctrl]+[K] |
| 12 | nf или np | [Ctrl]+[L] |
| 13 | cr | [Ctrl]+[M] или [Enter] |
| 14 | so | [Ctrl]+[N] |
| 15 | si | [Ctrl]+[O] |
| 16 | dle | [Ctrl]+[P] |
| 17 | dc1 | [Ctrl]+[Q] |
| 18 | dc2 | [Ctrl]+[R] |
| 19 | dc3 | [Ctrl]+[S] |
| 20 | dc4 | [Ctrl]+[T] |
| 21 | nak | [Ctrl]+[U] |
| 22 | syn | [Ctrl]+[V] |
| 23 | etb | [Ctrl]+[W] |
| 24 | can | [Ctrl]+[X] |
| 25 | em | [Ctrl]+[Y] |
| 26 | sub | [Ctrl]+[Z] |
| 27 | esc | [Ctrl]+[[] или [Esc] |
| 28 | fs | [Ctrl]+[\] |
| 29 | gs | [Ctrl]+[]] |
| 30 | rs | [Ctrl]+[^] |
| 31 | ns | [Ctrl]+[-] |
| 32 | sp | [пробел] |
| 127 | del | [Ctrl]+[Backspace] или [Del] на доп. цифровой клавиатуре |
Иван Паскаль pascal@tsu.ru
Управляющие структуры
К управляющим структурам относятся:
1. Конструкция if-fi
2. Конструкция case-esac
Общий синтаксис конструкции if-fi
if список1 then
список2
elif список3 then
список4
else
список5
fi
Конструкция if-fi работает так же, как и в других языках программирования.Если список1 (условие) истинный, выполняется список2, иначе выполняется список3 и проверяется его истинность и т.д. Допускается неограниченная вложенность операторов if.
Список – это список команд. Разделителем команд служит символ «;». Список обязательно должен заканчиваться точкой с запятой. Пример списка: ls; dir; cat file;
При программировании на bash есть один подводный камень, относящийся к логическим выражениям. В других языках программирования выражение «истина» обозначается как «true», а «ложь» – как «false». В языке C с выражением «ложь» сопоставляется нулевое значение переменной, а за истину принимается любое ненулеое значение. В bash все немного по-другому. За истину в конструкции if принимается 0, так как 0 – это код нормального завершения программы (команды). Правильнее конструкцию if трактовать так: если код завершения списка команд, задающего условие в конструкции if, равен 0, то будет выполнен список2. Код завершения последней команды можно узнать с помощью переменной $?.
Например,
if [ $? -ne 0 ]; then echo "Ошибка. См. файл протокола"; fi;
В этом примере мы проверяем код завершения последней команды. Если он не равен нулю (-ne), мы выводим сообщение об ошибке. Кроме опции -ne можно использовать такие опции:
-eq – равно -lt – меньше -gt – больше -le – меньше или равно -ge – больше или равно Сравнение строк:
= – равно != – не равно
Символ "!" является символом логической операции NOT (отрицание). Кроме этого символа, можно использовать опции команды -o и –a, которые обозначают логические операции ИЛИ (OR) и И (AND).
Проверить существование файла можно опцией -e, а существование каталога - d.
Все эти опции являются параметрами программы test. Другими словами, вместо квадратных скобок вы можете использовать команду test, поэтому следующие выражения аналогичны
test –e /etc.passwd
[-e /etc/passwd]
Cинтаксис блока выбора (case – выбор):
case значение in
шаблон1) список1 ;;
...
шаблонN) списокN ;;
esac
Работает этот блок почти также, как в языке С. Однако есть небольшая разница: если найдено совпадение с каким-нибудь шаблоном (например, шаблонN-2) и выполнен соответствующий список команд списокN-2, осуществляется выход из блока. В языке С для достижения этого эффекта нужно было использовать оператор break, иначе выполнялись вы все списки после спискаN-2: списокN-1, списокN.
Вместо дейтсвия по умочанию нужно использовать шаблон *). Этот шаблон будет использоваться, когда не найдено совпадение ни с одним из шаблонов. Например,
case $A in
1) echo "A=1";;
2) echo "A=2";;
*) echo "A<>1 and A<>2";;
esac
Хорошим способом изучения железа PC
Хорошим способом изучения железа PC являетс самостоятельная сборка компьютера из б/у частей. Для запуска Linux нужна машина с процессором от 386. Это не может дорого стоить. Расспросите друзей и знакомых - наверняка что-нибудь найдете.
Загрузите, скомпилируйте и создайте загрузочный диск для Unios. (В качестве их домашней страницы значится http://www.unios.org, но это не работает) Это всего лишь загрузочная программа ``Hello World!'', состоящая из немногим более 100 строк ассемблерного кода. Было бы не плохо увидеть её преобразованной к формату ассемблера GNU as.
Откройте образ загрузочного сектора unios в шеснадцатеричном редакторе. Этот файл содержит 512 байт - ровно один сектор. Найдите "волшебное число" 0xAA55. Проделайте тоже самое с загрузочной дискетой или диском вашего компьютера. Вы можете использовать команду dd для копирования сектора в файл: dd if=/dev/fd0 of=boot.sector. Будьте весьма аккуратны при назначении параметров if
(input file) и of (output file)!
Прочитайте исходные тексты загрузчика LILO.
ЭТО ОПАСНО: будте осторожны с этими упражнениями. Здесь легко ошибиться, испортить главную загрузочную запись (MBR) и привести систему в нерабочее состояние. Убедитесь, что у вас есть работающая загрузочная дискета и вы знаете как с её помощью восстанавливать загрузочные сектора. Ниже приведена ссылка на tomsrtbt - спасательный диск, который я использую и могу рекомендовать. Лучшая предосторожность - использовать машину на которой нет ничего важного.
Установите lilo на дискету. Неважно если там не окажется ничего кроме ядра - вы получите ``kernel panic'', когда ядро будет готово загрузить init, но по крайней мере вы убедитесь, что lilo работает.
Продолжайте и наблюдайте как много системы вы сможете запихнуть на одну дискету. Кажется это второй из лучших способов изучения Linux. За справками обращайтесь к Bootdisk HOWTO и tomsrtbt (ссылки приведены ниже).
Заставьте lilo грузить unios (см. раздел железо/упражнения). Будет совсем круто, если вы сможете проделать это на дискете.
Создайте загрузочную петлю. Пусть lilo в MBR грузит lilo в одном из загрузочных секторов первичных разделов диска. Последнюю надо заставить грузить lilo из MBR... Возможно также использовать MBR и все четыре первичных раздела диска для создания пятиузлового кольца. Наслаждайтесь!
Осмысли следующее: /dev/ hda3 является файлом специального типа и описывает раздел жесткого диска. Однако он находится в файловой системе подобно другим файлам. В момент, когда ядру надо решить который из разделов будет смонтирован в качестве корневого, ядро ещё не имеет файловой системы. Как же ядру прочитать /dev/hda3 чтобы смонтировать раздел?
Постройте собственное ядро, если вы ещё не сделали этого. Прочтите всю документацию по каждой из опций настройки.
Выясните насколько маленькое (работоспособное) ядро вы сможете создать. Вы сможете многому научиться избавляясь от ошибок.
Прочтите ``The Linux Kernel'' (URL приведен ниже) и последовательно отыскивайте соответствующие части исходного кода. На момент напмсания данного документа эта книга описывала ядро версии 2.0.33, которое явно устарело. Возможно будет проще скачать исходные тексты для старой версии. Как приятно обнаруживать куски C-кода озаглавленные ``process'' и ``page''.
Хакайте! Посмотрим, сможете ли вывести какие-либо дополнительные сообщения или что-то ещё.
Используя ldd, выясните какие библиотеки использует ваше любимое приложение.
Используя ldd, выясните какие библиотеки использует программа init.
Создайте игрушечную библиотеку с одной - двумя функциями. Для создания библиотек используется программа ar, так что начать следует с чтения соответствующего ман(уала). Напишите, скомпилируйте и соберите программу, которая будет использовать эту библиотеку.
Найдите директорию rcN.d для вашего "уровня запуска" по умолчанию и выполните команду ls -l, чтобы узнать на какие файлы указывают ссылки.
Измените количество виртуальных терминалов в системе.
Уберите любую не нужную вам подсистему из "уровня запуска" по умолчанию.
Оцените сколько вам удалось сэкономить на старте.
Создайте загрузочную дискету с lilo, ядром и "статически" собранной программой "hello world", причем последнюю назовите /sbin/init. Убедитесь, что система грузится и приветствует вас как положено.
Отследите все сообщения, выдаваемые системой при запуске. Или распечатайте содержимое системного журнала /var/log/messages с момента последнего старта. Затем, начиная с inittab, проследуйте по всем выполненным скриптам, отмечая кто что делает. Вы также можете вставить в скрипты дополнительные сообщения типа
echo "Hello, I am rc.sysinit"
Это упражнение помогает также в изучении техники написания скриптов под bash. Некоторые из скриптов устроены весьма непросто, поэтому справочник по командам bash окажется весьма кстати.
Создайте очень маленькую файловую систему и рассмотрите её с помощью шестнадцатеричного вьюера. Найдите inod'ы, суперблоки и содержимое файла.
Я верю в существование программ, которые представляют файловую систему в графическом виде. Найдите, опробуйте и пришлите мне ссылку и ваши впечатления.
Исследуйте код ядра, относящийся к файловой системе ext2.
Выполните update -d, и обратите внимание на предупреждение в последней строке относительно нарушения границ (?) (``threshold for buffer fratricide''). В настоящий момент это не понятно, давайте исследовать!
Перейдите в директорию /proc/sys/vm выполните cat для файлов этой директории. Посмотрите что с этим можно сделать.
Загляните в системный журнал. Найдите непонятное вам сообщение и отыщите информацию о том что оно значит.
Направьте все сообщения на терминал (tty). (Потом верните всё обратно).
Основы bash легки в изучении. Однако вам не следует останавливаться: глубины невообразимы. Заведите привычку всегда искать лучшие пути для выполнения работы.
Читайте скрипты, найдите вещи которые вы не понимаете.
Создайте файл /etc/ passwd вручную. Пароли могут быть установлены в null и изменены программой passwd после регистрации. Прочтите ман на этот файл. Запустите его командой man 5 passwd чтобы получить информацию о файле, а не о программе.
Уровни области подкачки
Страницы с собственными данными первоначально являются страницами, копируемыми при записи или заполняемыми нулями. Когда выполняется изменение, и, соответственно, копирование, начальное хранилище объекта (обычно файл) не может больше использоваться для хранения копии страницы, когда VM-системе нужно использовать ее повторно для других целей. В этот момент на помощь приходит область подкачки. Область подкачки выделяется для организации хранилища памяти, которая иначе не может быть доступна. FreeBSD создает структуру управления подкачкой для объекта VM, только когда это действительно нужно. Однако структура управления подкачкой исторически имела некоторые проблемы.
Во FreeBSD 3.x в структуре управления областью подкачки предварительно выделяется массив, который представляет целый объект, требующий хранения в области подкачки--даже если только несколько страниц этого объекта хранятся в области подкачки. Это создает проблему фрагментации памяти ядра в случае, когда в память отображаются большие объекты или когда ветвятся процессы, занимающие большой объем памяти при работе (RSS). Также для отслеживания памяти подкачки в памяти ядра поддерживается `список дыр', и он также несколько фрагментирован. Так как 'список дыр' является последовательным списком, то производительность при распределении и высвобождении памяти в области подкачки неоптимально и ее сложность зависит от количества страниц как O(n). Также в процессе высвобождения памяти в области подкачки требуется выделение памяти в ядре, и это приводит к проблемам блокировки при недостатке памяти. Проблема еще более обостряется из-за дыр, создаваемых по чередующемуся алгоритму. Кроме того, список распределения блоков в области подкачки легко оказывается фрагментированной, что приводит к распределению непоследовательных областей. Память ядра также должна распределяться по ходу работы для дополнительных структур по управлению областью подкачки при выгрузке страниц памяти в эту область. Очевидно, что мест для усовершенствований предостаточно.
Во FreeBSD 4. x подсистема управления областью подкачки была полностью переписана мною. При этом структуры управления областью подкачки распределяются при помощи хэш-таблицы, а не через линейный массив, что дает им фиксированный размер при распределении и работу с гораздо меньшими структурами. Вместо того, чтобы использовать однонаправленный связный список для отслеживания выделения пространства в области подкачки, теперь используется побитовая карта блоков области подкачки, выполненная в основном в виде древовидной структуры с информацией о свободнов пространстве, находящейся в узлах структур. Это приводит к тому, что выделение и высвобождение памяти в области подкачки становится операцией сложности O(1). Все дерево также распределяется заранее для того, чтобы избежать распределения памяти ядра во время операций с областью подкачки при критически малом объеме свободной памяти. В конце концов, система обращается к области подкачки при нехватке памяти, так что мы должны избежать распределения памяти ядра в такие моменты для избежания потенциальных блокировок. Наконец, для уменьшения фрагментации дерево может распределять большой последовательный кусок за раз, пропуская меньшие фрагментированные области. Я не сделал последний шаг к заведению 'указателя на распределение', который будет передвигаться по участку области подкачки при выделении памяти для обеспечения в будущем распределения последовательных участков, или по крайней мере местоположения ссылки, но я убежден, что это может быть сделано.
UseModMapMods
Служит для указания "критерия" LevelOneOnly. Если справа стоит слово "level1" или "levelone", то "критерий" проверяется. Если слова "anylevel" или "any" - игнорируется. Кстати, "по умолчанию" он игнорируется, так что строчки вида
useModMapMods = anylevel;
особого смысла не имеют.
User ID
Уникальный номер юзера. Он однозначно соответствует имени (Name) и используется внутри системы.
User-Mode Linux
«Linux в пользовательском режиме» (User-Mode Linux, UML) – самый универсальный эмулятор. Он работает немного не так, как традиционные эмуляторы аппаратного обеспечения – он позволяет вам создавать виртуальные машины, имеющие оборудование, которого может и не быть на вашем компьютере. Это может быть очень удобно для тестирования различных конфигураций аппаратного обеспечения, потому что вам не придется идти в магазин и покупать необходимое дополнительное оборудование.
UML состоит из набора патчей к ядру Linux, которые позволяют вам «загружать» другие операционные системы в консольных окнах. Приятная особенность – это то, что виртуальные операционные системы не требуют для запуска прав root'а. Поэтому каждый пользователь может загружать у себя сколько угодно операционных систем независимо от других пользователей.
Процесс виртуализации настолько полный, что вы даже можете запускать X11 на виртуальных системах. Но это может вас запутать, особенно если у вас загружено много виртуальных систем, потому что их X11-приложения располагаются на одном рабочем столе с обычными программами X Window.
Так же с помощью UML можно создать загрузочный диск с определенной конфигурацией, которую вам нужно загрузить. Конечно же, как и в любой хорошей программе для Linux, все необходимые компоненты и настройки могут загружаться через сеть.
Из всех перечисленных здесь систем, UML – самая многофункциональная и самая сложная. Если у вас есть большое количество времени и желания на изучение всех её возможностей – изучайте, и вы не пожалеете.
Станислав Иевлев
Наверняка вы знакомы с эмуляторами операционных систем и определенных машин. User Mode Linux - особый вид виртуальной машины - он ничего не эмулирует. Ведь это просто ядро Linux запущенное как обычная программа (в пользовательском режиме - user mode). Такое необычное сочетание влечет за собой массу интересного. Use Mode Linux может предоставить вам возможности которые вы нигде больше не получите (разве только в виртуальных машинах, но работать там все будет на порядок медленнее):
Если обвалится ядро User Mode Linux, то хост-ядро (ядро системы в которой вы запустили UserMode) будет продолжать функционировать.
Вы можете запускать ядро UML как непривилегированный пользователь.
Вы можете отлаживать ядро UML как любой другой процесс.
Вы можете использовать его как "песочницу" для проверки новых приложений, в том числе и графических.
Вы можете запросто и одновременно запускать различные дистрибутивы.
Можно использовать виртуальную машину для работы ''опасных" сетевых служб, таких как ftp и www. Взломщик может поломать (даже удалить) систему виртуальной машины, но хост-система останется невредимой и легко восстановит виртуальное ядро.
В конце концов это просто очень забавная программа.
Для того чтобы попробовать User Mode Linux проделайте следующие процедуры:
Установите пакеты umlinux (ядро User Mode),uml-net-tools (утилиты для работы сетевых служб User Mode), uml-rootfs (пример корневой файловой системы).
Пользователь, желающий попробовать User Mode Linux, должен дать команду uml_install. В результате, в его домашнем каталоге будет создан подкаталог UML, содержащий корневую файловую систему и все необходимые ссылки. Для размещения корневой файловой системы потребуется около 200М свободного дискового пространства.
Если вы желаете использовать сетевые возможности - перед запуском User Mode Linux запустите с правами администратора cкрипт uml_net_start - будет запущен сервер виртуальной сети и сконфигурированы необходимые сетевые интерфейсы.
Для запуска User Mode Linux перейдите в каталог UML и дайте оттуда команду "./linux" .
В систему входите как пользователь root без пароля. По завершению работы, дайте команду halt.
UML реализован в дистрибутиве Linux-Mandrake RE Spring 2001
Free software for free people/Usr
Обычно достаточно большой раздел (1-2Gb), который редко разбивается на подразделы. Без LVM я бы не рекомендовал его разбивать, однако при его наличии это может иметь смысл.
Насколько мне известно noatime на этом разделе не может дать никаких неприятных последствий.
/Usr/include : Файлы заголовков, включаемые в программы на C
Эти символические ссылки требуются, если компиляторы языков C или C++ установлены и только для систем, не основанных на glibc.
/usr/include/asm -> /usr/src/linux/include/asm-<arch> /usr/include/linux -> /usr/src/linux/include/linux
/Usr/local : Каталог для локального ПО
Каталоговая структура /usr/local используется системным администратором в тех случаях, когда он устанавливает программное обеспечение, которое будет использоваться локально в рамках данного хоста. Этот каталог не должен перезаписываться при обновлениях системного программного обеспечения. Он может использоваться для программ и данных, не попавших в каталог /usr, доступ к которым разрешен с других хостов.
Локально устанавливаемое программное обеспечение должно располагаться не в /usr, а в /usr/local, если только его установка производится не в целях замены или обновления ПО в /usr. (Программное обеспечение, расположенное в / или /usr может быть перезаписано при обновлениях системы (хотя мы рекомендуем, чтобы дистрибутивы не перезаписывали данные в /etc в таких обстоятельствах). По этой причине локально устанавливаемое программное обеспечение не должно размещаться за пределами каталога /usr/local без достаточных на то оснований. )
Следующие каталоги или символические ссылки на каталоги должны иметься в /usr/local :
bin - Локальные исполняемые файлы
games - Локально установленные игровые приложения
include - Локальные заголовочные файлы для C
lib - Локальные библиотеки
man - Локальные онлайновые руководства
sbin - Локальные системные исполняемые файлы
share - Архитектурно-независимые структура каталогов для локального ПО
src - Локально установленные исходные коды.
Никаких каталогов, кроме перечисленных выше, не должно быть в /usr/local после первой установки FHS-совместимой системы.
/Usr/share : Архитектурно-независимые данные
Структура каталогов /usr/share предназначена для всех файлов, которые предназначены только для чтения и не зависят от архитектуры. Так, например, компьютеры на платформах i386, Alpha и PPC могут поддерживать один общий каталог /usr/share, который монтируется на остальных компьютерах. Заметим, однако, что /usr/share обычно рассчитан на одну версию ОС и не предназначен для того, чтобы быть разделяемым различными операционными системами или различными версиями одной и той же ОС. Примерами файлов, которые размещаются в этом каталоге, могут служить файлы документации (man, doc) или базы данных (dict, terminfo, zoneinfo). Любая программа или пакет, который содержит или требует данных, не подлежащих модификации, должны хранить эти данные в каталоге /usr/share (или /usr/local/share, если пакет установлен локально). Рекомендуется использовать для этих целей подкаталоги каталога /usr/share.
Данные игровых программ, сохраняемые в /usr/share/games, должны быть чисто статическими данными. Любые модифицируемые файлы, такие как файлы с результатами игр, протоколы игр и так далее, должны размещаться в каталоге /var/games.
В каталоге /usr/share создаются следующие подкаталоги или символические ссылки
man - Он-лайновые руководства
misc - Различные архитектурно-независимые данные
dict - Словари (optional)
doc - Различная документация (optional)
games - Файлы статических данных для /usr/games (optional)
info - Основная директория для системы GNU Info (optional)
locale - Локальная информация (optional)
nls - Каталоги сообщений для поддержки языков (optional)
sgml - Данные для SGML и XML (optional)
terminfo - Каталог базы данных для terminfo (optional)
tmac - Макросы для troff, не распространяемые с groff (optional)
zoneinfo - Конфигурационные файлы и информация о временной зоне (optional)
Рекомендуется размещать здесь архитектурно-независимые каталоги, создаваемые приложениями. К такого рода каталогам относятся groff, perl, ghostscript, texmf и kbd (Linux) или syscons (BSD). Они могут, однако, из соображений обратной совместимости, по усмотрению разработчика располагаться в /usr/lib. Подобным же образом в дополнение к каталогу /usr/share/games может создаваться каталог /usr/lib/games, если разработчик желает разместить тут какие-то данные для своей игры.
/Usr/share/dict : Словари
Каталог /usr/share/dict содержит списки слов (словари), используемые в системе; обычно в ней находится только файл words для английского языка, который используется утилитой look(1) и различными программами проверки правописания. Файл words может быть ориентирован либо на американский, либо на британский вариант языка. В системах, где необходим как американский, так и британский английский, можно сделать words ссылкой на /usr/share/dict/american-english или /usr/share/dict/british-english.
Списки слов для других языков могут быть добавлены, используя английское название соответствующего языка, например, /usr/share/dict/french, /usr/share/dict/danish, и так далее. В названиях должен, по возможности, использоваться набор символов ISO 8859, соответствующий данному языку; если возможно, надо использовать набор символов Latin1 (ISO 8859-1).
/Usr/share/man : Страницы руководства man
Исходной директорией (<mandir>) для интерактивного руководства man в UNIX-системах является каталог /usr/share/man. Этот каталог содержит информацию о командах и других данных, размещаемых в файловых системах / и /usr.
Страницы интерактивного руководства man разбиты на следующие секции:
man1: Пользовательские программы.
В этой секции содержатся описания общедоступных команд. Здесь расположена большая часть необходимой пользователям документации к программам.
man2: Системные вызовы.
Эта секция описывает все системные вызовы (запросы к ядру на выполнение каких-то операций).
man3: Библиотеки функций и подпрограмм.
В секции 3 описываются библиотеки программных процедур, которые не являются прямыми вызовами сервисов ядра. Эта секция, как и секция 2, представляет интерес только для программистов.
man4: Специальные файлы.
Секция 4 описывает специальные файлы устройств, функции соответствующих драйверов и средства сетевой поддержки, предоставляемые системой. Обычно в эту секцию включается описание файлов устройств, находящихся в каталоге /dev, и интерфейса ядра для средств поддержки сетевых протоколов.
man5: Форматы файлов.
Форматы многих файлов данных документированы в секции 5. Речь идет о различных подключаемых файлах, файлах вывода программ, системных файлах и так далее.
man6: Игры.
В эту секцию включена документация к играм, демо и другим тривиальным программам. Разные люди могут иметь разные мнения о том, насколько важно то, что размещено здесь.
man7: Разное.
Страницы руководства, которые трудно отнести к какому-то иному разделу, размещаются в секции 7. Здесь вы найдете, к примеру, описание troff и других средств для обработки текста.
man8: Системное администрирование.
В этой секции документированы программы, используемые системным администратором для выполнения системных операций и поддержки работоспособности системы. Некоторые из этих программ бывают полезны иногда и обычным пользователям.
Деление страниц руководства на секции и нумерация секций от "1" до "8" определено традициями. В общем случае имена файлов для страниц руководства, расположенных в определенной секции, оканчиваются расширением вида .<section>, совпадающим с номером секции. Для каждой секции создается отдельный каталог с именем <mandir>/<locale>/man<section>/<arch>, где компонент <section> задает секцию руководства, а разъяснения того, что имеется в виду под <locale> и <arch> даются ниже.
Примечание: Если, например, /usr/local/ man не содержит файлов руководства в секции 4 (Устройства), то каталог /usr/local/man/man4 может не создаваться.
Для поддержки страниц руководства, написанных на разных (или нескольких) языках, вводятся отдельные подструктуры каталога /usr/share/man. Способ именования специфичных для языка подкаталогов /usr/share/man основан на Приложении E стандарта POSIX 1003.1, которое задает формат строки, идентифицирующей локаль, - это общепринятый метод определения особенностей, определяемых культурой той или иной страны. Строка <locale> имеет следующий формат:
<language>[_<territory>][.<character-set>][,<version>]
Поле <language> должно браться из стандарта ISO 639 (коды для представления названий языков). Оно должно состоять из двух символов и записываться только в нижнем регистре.
Поле <territory> должно состоять из двух символов, записываемых только в верхнем регистре (заглавными буквами), и представляет собой, если это возможно, двухбуквенный код из спецификации ISO3166.
Поле <character-set> представляет собой стандартное описание кодировки. Если поле <character-set> представлено только цифрами, эти цифры представляют номер международного стандарта, описывающего набор символов. Рекомендуется, если это возможно, чтобы это было числовое представление (в особенности стандартов ISO), не включающее дополнительных символов пунктуации, и чтобы любые символы были в нижнем регистре.
После поля <character-set> может располагаться параметр <version>, который отделяется запятой. Этот параметр может использоваться для выделения каких-то дополнительных версий кодировки. Но разработчики стандарта FHS не рекомендуют использовать поле <version>, если только это не является необходимым.
Системы, которые используют только один язык и набор символов для всех страниц интерактивного руководства, могут опустить подстроку <locale>, и хранить все страницы руководства в <mandir>. Например, системы, в которых страницы руководства имеются только на английском языке, причем в кодировке ASCII, могут хранить все страницы документации (каталоги man<section>) прямо в /usr/share/man. (Фактически это традиционное их местоположение.)
Страны, для которых есть общепринятый стандарт кодового набора символов, могут опустить поле <character-set>, но стандарт настоятельно рекомендует включить его, особенно для стран с несколькими конкурирующими стандартами.
В тексте стандарта приведены следующие примеры формирования имен каталогов для различных стран и кодировок:
| Язык | Территория | Набор символов | Каталог |
| Английский | -- | ASCII | /usr/share/man/en |
| Английский | Великобритания | ASCII | /usr/share/man/en_GB |
| Английский | Соединенные Штаты | ASCII | /usr/share/man/en_US |
| Французский | Канада | ISO 8859-1 | /usr/share/man/fr_CA |
| Французский | Франция | ISO 8859-1 | /usr/share/man/fr_FR |
| Немецкий | Германия | ISO 646 | /usr/share/man/de_DE.646 |
| Немецкий | Германия | ISO 6937 | /usr/share/man/de_DE.6937 |
| Немецкий | Германия | ISO 8859-1 | /usr/share/man/de_DE.88591 |
| Немецкий | Швейцария | ISO 646 | /usr/share/man/de_CH.646 |
| Японский | Япония | JIS | /usr/share/man/ja_JP.jis |
| Японский | Япония | SJIS | /usr/share/man/ja_JP.sjis |
| Японский | Япония | UJIS (или EUC-J) | /usr/share/man/ja_JP.ujis |
Кроме того, некоторые большие массивы страниц руководства, относящихся к определенным приложениям, могут иметь дополнительный суффикс, добавляемый к имени файла со страницей руководства. Например, для системы обработки почты MH файлы руководства должны иметь дополнительный суффикс mh в имени файла. Все страницы руководства для системы X Window System должны иметь дополнение x к имени файла.
Требование размещения страниц интерактивного руководства для различных языков в соответствующих подкаталогах каталога /usr/share/man распространяется также на другие структуры каталогов с руководствами, такие как /usr/local/man и /usr/X11R6/man. (Это требование применяется также к каталоговой структуре /var/cache/man, рассматриваемой ниже.)
/Usr/share/misc : Различные архитектурно-независимые данные
Этот каталог содержит различные архитектурно-независимые файлы, для которых не требуется отдельный подкаталог в /usr/share (но разработчики могут при желании разместить их также в /usr/lib). Вот некоторые из таких файлов: airport, birthtoken, eqnchar, getopt, gprof.callg, gprof.flat, inter.phone, ipfw.samp.filters, ipfw.samp.scripts, keycap.pcvt, mail.help, mail.tildehelp, man.template, map3270, mdoc.template, more.help, na.phone, nslookup.help, operator, scsi_modes, sendmail.hf, style, units.lib, vgrindefs, vgrindefs.db, zipcodes.
Следующие файлы или символические ссылки на файлы должны иметься в /usr/share/misc, если соответствующие подсистемы установлены.
ascii - таблица набора символов ASCII (ASCII character set table),
magic - список магических чисел для команды file, используемый по умолчанию,
termcap - база данных с параметрами терминалов,
termcap.db - база данных с параметрами терминалов.
Этот каталог содержит различные архитектурно-независимые файлы, для которых не требуется отдельный подкаталог в /usr/share.
/Usr/src : Исходные коды
Для систем, основанных на glibc, нет никаких специфических правил для этого каталога. Для систем, основанных на версиях библиотеки libc, предшествующих glibc, применяются следующие правила:
Единственными исходными кодами, которые должны быть размещены в определенном месте, являются исходные коды ядра Linux. Они размещаются в /usr/src/linux.
Если установлен компилятор C или C++, а полная версия исходных кодов ядра не установлена, то подключаемые файлы из исходных кодов ядра должны размещаться в следующих каталогах:
/usr/src/linux/include/asm-<arch> /usr/src/linux/include/linux
где <arch> - название архитектуры системы (например, i386).
Замечание: /usr/src/linux может быть символической ссылкой на дерево каталогов с исходными кодами ядра.
Установка
Если вы хотите установить собранный RPM, запустите следующую команду из-под root:
# rpm -Uvh bash-completion-xxxxxxxx-x.noarch.rpm
После чего вы обнаружите новый файл в своей системе, /etc/bash_completion. Если вы не добавляли параметр --noscripts при вызове rpm, когда делали установку, скрипт RPM, вызываемый после установки, изменит ваш /etc/bashrc так, чтобы он содержал следующий кусок кода:
# START bash completion -- do not remove this line bash=${BASH_VERSION%.*}; bmajor=${bash%.*}; bminor=${bash#*.} if [ "$PS1" ] && [ $bmajor -eq 2 ] && [ $bminor '>' 04 ] && [ -f /etc/bash_completion ]; then # interactive shell # Source completion code . /etc/bash_completion fi unset bash bmajor bminor # END bash completion -- do not remove this line
Если вы устанавливаете файл с исходниками, упакованный либо gunzip, либо bunzip2, положите его куда-нибудь в своей системе и добавьте вышеуказанный код либо в /etc/bashrc, либо в ~/.bashrc. Если вы положили исходник куда-нибудь еще, кроме /etc/bash_completion, вам нужно отредактировать начало, чтобы переменная $BASH_COMPLETION указывала на правильное расположение файла bash_completion.
Строка, которая вам нужна:
[ -z "$BASH_COMPLETION" ] && declare -r BASH_COMPLETION=/etc/bash_completion
Установка DOS
Вставьте дискету GRUB. Когда вы увидите меню, вставьте загрузочную дискету DOS. Выберите из меню раздел 2 (floppy). Нажмите enter. Загрузится дискета, а разделы 1 и 3 будут скрыты.
Запустите FDISK и проверьте, что устройство C: является разделом 2. Затем установите DOS:
SYS C:
Установка других операционных систем после Linux
При инсталляции MS-DOS и Windows 95/98 ее стандартный загрузчик автоматически записывается в MBR, а признак активности в таблице разделов ставится на раздел MS-DOS (Windows). Этот загрузчик умеет только передавать управление на первый сектор активного раздела. Поэтому, если вначале будет установлена Linux, а затем Windows или MS-DOS, то Linux перестанет загружаться. Говорят, что Windows NT и Windows 2000 загрузчик из MBR не трогают (правда, я этот факт не проверял).
С проблемами, возникающими при установке после Linux другой ОС обычно можно справиться, загрузившись в Linux с помощью загрузочной дискеты, откорректировав конфигурационный файл LILO (добавив в него вызов новой ОС) и запустив /sbin/lilo (если LILO установлен в MBR), либо сделав активным раздел LILO (если он установлен в первичный раздел).
За техническими подробностями об ext3,
За техническими подробностями об ext3, пожалуйста, обращайтесь к работе Stephen Tweedie и его дискуссии.
Файловая система ext3 является прямым потомком ext2. Одной из самых ценных особенностей ext3 является 100%-ная обратная совместимость с ext2, так как ext3 - это не что иное как ext2 с поддержкой журналирования. Очевидным недостатком ext3 является то, что в ней не реализована все та функциональность современных файловых систем, которая повышает скорость манипулирования данными и качество их распределения на дисках.
ext3 существует как патч к ядру 2.2.19 kernel, так что сначала получите ядро linux-2.2.19 с ftp://ftp.kernel.org/pub/linux/kernel/v2.2/ или с одного из зеркал. Сам патч лежит на ftp://ftp.linux.org.uk/pub/linux/sct/fs/jfs/ или ftp.kernel.org/pub/linux/kernel/people/sct/ext3, или же на одном из зеркал.
Неважно какой сайт вы выбрали - вам нужно получить следующие файлы:
ext3-0.0.7a.tar.bz2: патч к ядру. e2fsprogs-1.21-WIP-0601.tar.bz2: набор программ e2fsprogs с поддержкой ext3 Скопируйте файл ядра Linux linux-2.2.19.tar.bz2 и файл ext3-0.0.7a.tar.bz2 в каталог /usr/src и распакуйте их: mv linux linux-old tar -Ixvf linux-2.2.19.tar.bz2 tar -Ixvf ext3-0.0.7a.tar.bz2 cd linux cat ../ext3-0.0.7a/linux-2.2.19.kdb.diff | patch -sp1 cat ../ext3-0.0.7a/linux-2.2.19.ext3.diff | patch -sp1 Первый .diff-файл - это копия патчей для отладчика ядра kdb (от SGI). Второй - это файловая система ext3.
Теперь сконфигурируйте ядро, сказав "YES" в пункте "Enable Second extended fs development code" (Разрешить использование дополнительного программного кода для экперименальных файловых систем) в разделе "Файловая система", а потом постройте ядро.
Когда ядро скомпилируется и установится, установите e2fsprogs: tar -Ixvf e2fsprogs-1.21-WIP-0601.tar.bz2 cd e2fsprogs-1.21 ./configure make make check make install Вот и все. Следующий шаг - это установка ext3 на раздел диска. Перезагрузитесь с новым ядром. Теперь у вас появляется выбор: либо создать новую журналирующую файловую систему, либо журналировать уже существующую.
Создание новой файловой системы ext3. Просто используйте mke2fs из установленного пакета e2fsprogs, и не забудьте указать ключ "-j" при запуске mke2fs. mke2fs -j /dev/xxx где /dev/xxx - это устройство, на котором вы будете создавать файловую системы ext3. Флаг "-j" говорит mke2fs, чтобы была создана файловая система ext3 со скрытым журналом. Можно контролировать размер журнала, используя флаг flag -Jsize=<n> (n - это нужный размер журнала в Мб). Обновление существующей файловый системы ext2 до ext3. Просто запустите tune2fs: tune2fs -j /dev/xxx Это можно проделывать либо на смонтированной, либо на несмонтированной файловой системе. Если файловая система смонтирована, то в корне файловой системы создается файл .journal; если же нет - то скрытый inode (блок данных с информацией о файле) используется для журнала. Таким образом, все происходит без какого-то риска для жизни существующих на файловых системах данных. Смонтировать файловую систему ext3 можно командой: mount -t ext3 /dev/xxx /mount_dir Так как ext3 - это по сути журналирующая ext2, то корректно размонтированная файловая система ext3, может затем быть снова смонтирована как ext2 без использования каких-то дополнительных команд.">
