Драйверы устройств
Как уже говорилось в лекции 10, часть системы, отвечающая за взаимодействие с каким-нибудь внешним устройством и называемая "драйвер", в Linux либо входит в ядро, либо оформляется в виде модуля ядра и подгружается по необходимости. Следовательно, файл-дырка, обращение к которому приводило к "no such device or address", вполне может и заработать (в этом одна из причин огромного количества устройств в /dev). Гуревич наотрез отказался объяснять Мефодию, как добавить новый драйвер, до тех пор, пока тот не будет лучше разбираться в архитектуре компьютеров вообще и в аппаратной части IBM-совместимых компьютеров в частности. Поэтому все, что смог понять Мефодий, не имея таких знаний, сводилось к следующему. Во-первых, если существуют различия между тем, как по умолчанию загружает модули система и тем, как на самом деле это необходимо делать, различия должны быть описаны в файле /etc/modules.conf. Во-вторых, после изменения этого файла, добавления нового устройства, обновления самих модулей и т.п. следует запускать утилиту depmod, которая заново выстраивает непротиворечивую последовательность загрузки модулей. В-третьих, интересно (но в отсутствие знаний - малопознавательно) запускать утилиту lspci, которая показывает список устройств (распознаваемых по стандарту PCI), найденных на компьютере.
Файловая система
Из лекции 3 Мефодий узнал, как пользоваться файловой системой и какую структуру она имеет с точки зрения программы, работающей с файлами в ней. О том, как огранизована файловая система изнутри, написан ряд больших статей, защищено немало кандидатских (и несколько докторских) диссертаций. Разработка файловой системы - сложный и интересный процесс, требующий одновременно владения высшей математикой, статистикой, умения безошибочно программировать и досконального знания того, как работает то или иное дисковое устройство. Поэтому файловых систем не так много, и каждая из них устроена по-своему, в соответствии с тем, как решал тот или иной коллектив разработчиков задачу быстрого и надежного доступа к файлам.
Файлы-дырки и другие типы файлов
Кое-какие идеи динамического именования устройств присутствуют и в статической схеме. Так, файлы /dev/mouse или /dev/cdrom на самом деле представляют собой символьные ссылки на соответствующие файлы-дырки. Если тип мыши или лазерного привода изменится, достаточно изменить эти ссылки и перезапустить соответствующие службы:
Пример 11.2. Идентификация внешних устройств в /dev/ (html, txt)
Файл-дырка не имеет размера: сколько в него ни записывай, в файл на диске ничего не попадет. Вместо этого ядро передает все записанное драйверу, отвечающему за файл-дырку, а тот по-своему обрабатывает эти данные. Точно так же работает и чтение из файла-дырки: все запрашиваемые данные в нее подсовывает драйвер. Большинство драйверов - дисковые, звуковые, последовательных и параллельных портов и т.п. - обращаются за данными к какому-нибудь внешнему устройству или передают их ему. Но есть и такие, которые сами все "выдумывают": это и /dev/null, черная дыра, в которую что угодно можно записать, и все пропадет безвозвратно, и /dev/zero, из которого можно считать сколько угодно нулей (на запись оно ведет себя как /dev/null), и /dev/urandom, из которого можно считать сколько угодно относительно случайных байтов.
Изучив выдачу команды ls -lL (ключ "-L" заставляет ls выводить информацию не о символьной ссылке, а о файле, на который она указывает), Мефодий обнаружил, что та вместо размера файла-дырки (который равен нулю) выводит два числа. Первое из этих чисел называется старшим номером устройства (major device number), оно, упрощенно говоря, соответствует драйверу, отвечающему за устройство. Второе называется младшим номером устройства (minor device number), оно соответствует способу работы с устройством, а для дисковых носителей - разделу. В частности, из примера видно, что устройствами /dev/random и /dev/urandom занимается один и тот же драйвер со старшим номером 1. При этом часть устройств (по преимуществу - дисковые) имеет тип "b", а другая часть - "c" (этот тип имеют, например, терминалы). Тип указан в атрибутах файла первым символом. Это блочные (block) устройства, обмен данными с которыми возможен только порциями (блоками) определенного размера, и символьные (character) устройства, запись и чтение с которых происходит побайтно. Блочные устройства, вдобавок, могут поддерживать команды прямого доступа вида "прочитать блок номер такой-то" или "записать данные на диск, начиная с такого-то блока".
Блочные и символьные устройства - полноправные объекты файловой системы, такие же, как файлы, каталоги и символьные ссылки. Есть еще два типа специальных файлов - каналы и сокеты. Канал-файл (или fifo) называют еще именованным каналом (named pipe): это такой же объект системы, как и тот, что используется командной оболочкой для организации конвейера (его называют неименованным каналом), разница между ними в том, что у fifo есть имя, он зарегистрирован в файловой системе. Это - типичный файл-дырка, причем дырка двухсторонняя: любая программа может записать в канал (если позволяют права доступа) и любая программа может оттуда прочитать. Создать именованный канал можно с помощью команды mkfifo:
Пример 11.3. Использование именованного канала (html, txt)
Здесь важно, что утилита head показывает начало не "файла" hole, а именно последней записываемой порции данных, как и подобает трубе1).
Канал. Объект Linux, используемый в межпроцессном взаимодействии. Доступен в виде двух дескрипторов: один открыт на запись, другой - на чтение. Все данные, записываемые в первый дескриптор, немедленно можно прочитать из второго. Различают неименованный канал, уничтожаемый с закрытием обоих дескрипторов, и именованный канал (FIFO) - файл-дырку, создаваемый в файловой системе.
Что же касается сокетов, то это - более сложные объекты, предназначенные для связи двух процессов и передачи информации в обе стороны. Сокет можно представить в виде двух каналов (один "туда", другой "обратно"), однако стандартные файловые операции открытия/чтения/записи на нем не работают. Процесс, открывший сокет, считается сервером: он постоянно "слушает", нет ли в нем новых данных, а когда те появляются, считывает их, обрабатывает, и, возможно, записывает в сокет ответ. Процесс-клиент может подключиться к сокету, обменяться информацией с процессом-сервером и отключиться. Точно так же можно передавать данные и по сети - в этом случае указывается не путь к сокету на файловой системе (так называемый unix domain socket), а сетевой адрес и порт удаленного компьютера (например internet socket, если подключаться с помощью сети Internet).
Монтирование и размонтирование
В лекции 3 было рассказано о том, что файловые системы на различных разделах "прививаются" в виде ветвей общего дерева каталогов, растущего из "/". Делается это при помощи команды mount -o настройки_монтирования устройство точка_монтирования, где устройство - это имя блочного файла-дырки, точка_монтирования (mountpoint) - полный путь к каталогу, а настройки_монтирования определяют особые параметры, разные для разных файловых систем. После выполнения этой команды содержимое файловой системы, размещенной на устройстве (как правило, дисковом разделе), становится доступным в виде дерева подкаталогов точки_монтирования. Посмотреть список всех смонтированных файловых систем можно с помощью команды mount без параметров:
root@localhost root]# mount /dev/hda5 on / type ext3 (rw) /dev/hda7 on /home type ext3 (rw) /dev/fd0 on /mnt/floppy type subfs (rw,nosuid,nodev,sync) /dev/hdc on /mnt/cdrom type subfs (ro,nosuid,nodev) proc on /proc type proc (rw,gid=19) devpts on /dev/pts type devpts (rw,gid=5,mode=0620) [root@localhost root]# umount /home [root@localhost root]# ls /home [root@localhost root]# mount /dev/hda7 /home [root@localhost root]# ls /home methody shogun tmpuser
Пример 11.7. Просмотр списка смонтированных файловых систем (html, txt)
Оба Linux-раздела смонтированы при старте системы: /dev/hda5 образует корневую файловую систему, а /dev/hda7 используется для хранения пользовательских домашних каталогов1). Суперпользователь может размонтировать файловую систему вручную с помощью команды umount точка_монтирования, если на ней не открыто никаких файлов и никто не использует какой-либо ее каталог в качестве текущего.
Для того чтобы файловые системы монтировались при старте, их описывают в файле /etc/fstab:
/dev/hda5 / ext3 defaults 1 1 devpts /dev/pts devpts gid=5,mode=0620 0 0 /dev/hda7 /home ext3 defaults 1 2 proc /proc proc gid=19 0 0 /dev/hda6 swap swap defaults 0 0 /dev/fd0 /mnt/floppy subfs fs=floppyfss,sync,nodev,nosuid /dev/cdrom /mnt/cdrom subfs fs=cdfss,nodev,nosuid
Пример 11.8. Содержимое /etc/fstab (html, txt)
Первое поле каждой строки этого файла - устройство или название виртуальной файловой системы, второе - точка монтирования, третье - тип файловой системы, четвертое - настройки монтирования, а пятое и шестое относятся к организации резервного копирования и процедуре проверки цельности. Содержимое fstab практически повторяет выдачу mount (dev/cdrom на этой машине - ссылка на /dev/hdc). Здесь указывается и область подкачки, которую ядро не монтирует, а использует напрямую. Утилита mount поддерживает усеченный вариант командной строки mount точка_монтирования, при котором она самостоятельно ищет в /etc/fstab, каким способом должна быть смонтирована точка_монтирования. Для того чтобы при старте системы какое-либо устройство не монтировалось, а усеченным mount его можно было смонтировать вручную, в поле "настройки монтирования" добавляется ключевое слово noauto.
Две последних строки относятся к монтированию съемных (removable) носителей: лазерного и гибкого дисков. Съемные носители приходится монтировать гораздо чаще несъемных - не во время старта системы, а всякий раз, когда носитель сменился, и содержимое нового необходимо пользователю. Мало того, надо разрешить выполнять операцию mount пользователю, который принес дискету и желает поработать с ней. С другой стороны, нельзя всем и каждому давать право запускать mount и особенно umount с любыми параметрами! Существует четыре способа разрешить возникающее противоречие:
Воспользоваться усеченным вариантом mount (запись с настройкой noauto в fstab) и утилитой sudo, при помощи которой позволить пользователю выполнять, скажем, только команды mount /cdrom и umount /cdrom.Воспользоваться усеченным вариантом mount и настройкой owner в fstab, которая позволяет выполнять операцию монтирования хозяину устройства; при этом /dev/hdc отдается во владение первому зарегистрированному пользователю так же, как /dev/audio и прочие устройства персонального использования. Этот способ лучше предыдущего тем, что исключает ситуацию, когда один пользователь смонтирует диск, а другой немедленно его размонтирует.Воспользоваться специальным демоном из пакета autofs, который отслеживает обращения пользователей к некоторому каталогу (например, /mnt/cdrom/auto) и самостоятельно выполняет операцию mount, а если к содержимому носителя долгое время никто не обращался - umount. Этот способ лучше предыдущего тем, что пользователю вообще никаких дополнительных команд подавать не приходится.Воспользоваться специализированным модулем ядра (в примере - subfs), который всегда сообщает программе пользователя, что устройство смонтировано и готово к работе, а поменялся ли носитель, разбирается самостоятельно. Этот способ лучше предыдущего тем, что пользователю не приходится ждать, пока система соизволит размонтировать и "отдать" лазерный диск. Кроме того, subfs может снабжать пользователя данными из кеша, даже если диск давно уже вынут (речь идет, разумеется, об операциях чтения).
Во всех случаях, когда диск монтирует не системный администратор, стоит предпринять некоторые дополнительные действия. Например, диск должен монтироваться так, чтобы с него не работал запуск с подменой идентификатора (setUID), и чтобы на нем нельзя было создавать файлы-дырки (чтобы не потворствовать хулиганству, вроде запуска setUID-оболочки или записи прямо в устройство, соответствующее hda). За это отвечают настройки nosuid и nodev, упомянутые в /etc/fstab.
Кроме того, лазерные приводы имеют "защелку", не позволяющую извлечь диск, пока он используется, а дисководы или устройства USB Flash - нет (хотя, казалось бы, она как раз нужнее там, где происходит запись). Единственная надежда - на то, что пользователь не будет выдергивать дискету из дисковода, пока он занимается записью, и на нем горит зеленая лампочка. Чтобы каждая операция записи немедленно приводила к передаче данных, необходимо полностью отключить кеш записи, то есть использовать синхронный режим работы файловой системы. Это делается при помощи настройки sync.
Область подкачки
Итак, Linux на компьютере из примера использует три раздела: hda5, hda6 и hda7. Тип раздела hda6, "Linux swap", отличается от двух других - по словам Гуревича, "это вообще не файловая система". Это - так называемая область подкачки (swap space), пространство на диске, используемое системой для организации виртуальной памяти. Оказывается, областям оперативной памяти, которые запрашивают процессы у ядра, не всегда соответствуют части физической оперативной памяти. Если процесс долгое время не использует заказанную оперативную память, ее содержимое записывается на диск, в область подкачки - тем самым освобождается место в физической памяти для других процессов. Когда же он "вспомнит" об этой области памяти, ядро подкачает ее с диска, разместит в оперативной памяти (возможно, откачав другие области), и только тогда позволит процессу продолжить работу.
Вполне может сложиться ситуация, когда несколько процессов заказали оперативной памяти больше, чем ее есть в действительности, и преспокойно работают, потому что не используют все заказанное пространство сразу, позволяя системе откачивать неиспользуемые области. К тому же многие процессы (особенно демоны) не работают постоянно, а ждут наступления определенного события, и чем дольше они ждут, тем дольше не используют оперативную память, и тем выше вероятность, что ядро откачает ее.
Следует отдавать себе отчет в том, что если эти процессы вдруг захотят работать одновременно и со всеми областями памяти, ядру придется туго. Большую часть времени система будет проводить, откачивая и подкачивая данные, потому что дисковые операции чтения и записи работают в тысячи раз медленнее, чем запись и чтение из оперативной памяти3). Чтобы хоть как-то облегчить ядру задачу, область подкачки размещают на отдельном разделе, обмен данными с которым работает быстрее, чем чтение и запись в файл, обслуживаемые файловой системой.
Поддерживаемые Linux файловые системы
Если бы на компьютере из примера использовался способ монтирования лазерного диска 1 или 2, то в поле "тип" fstab было бы написано iso9660. Так называется тип файловой системы, обычно используемой на лазерных дисках. Что же касается жестких дисков, то на них может использоваться несколько типов файловых систем, даже на одном Linux-компьютере.
Основная файловая система в Linux называется "Ext2". Имя происходит от слова "extended" (расширенная) и появилось после того, как самая первая версия файловой системы ранних Linux, повторяющая возможности одного из вариантов файловой системы UNIX, окончательно устарела. Пришлось переписать соответствующую часть ядра, расширив уже имеющиеся возможности. Так появилась "ExtFS". Когда и она устарела, возможности снова расширили, и к названию добавилось число "2". Повсеместно используемая в дистрибутивах Linux файловая система "Ext3" - "трижды расширенная" - отличается от Ext2 поддержкой журнализации.
Журналируемая файловая система ведет постоянный учет всех операций записи на диск. Получающийся журнал обращений сам, в свою очередь, записывается на диск. Разница между записью журнала и записью самих данных в том, что данные следует записывать в строго определенное место, а журнал устроен так, чтобы записываться как можно быстрее. Выгода от такой двухступенчатой процедуры особенно остро ощущается после сбоя электропитания: все операции, записи, которые еще не успели завершиться, записаны в журнале, так что стоит после включения компьютера "проиграть" их еще раз, и файловая система войдет в норму! Если часть данных уже была записана на диск, повторная (по требованию журнала) запись тех же самых данных на то же самое место ничем повредить не может. Наконец, если операция записи не попала даже в журнал (что бывает редко), то файловая система все равно останется в рабочем состоянии, каким оно было до начала этой операции.
Журналирование поддерживается и другими файловыми системами, используемыми в Linux - XFS и ReiserFS. ReiserFS вообще похожа скорее на базу данных: внутри нее используется собственная система индексации и быстрого поиска данных, а индексные дескрипторы и каталоги в стиле Linux выполнены в виде одной из возможных надстроек над этой системой. Традиционно считается, что ReiserFS отлично подходит для хранения огромного числа маленьких файлов (что было одной из целей проекта), а XFS - для хранения очень больших файлов, в которых постоянно что-нибудь дописывается или изменяется.
В Linux поддерживается, кроме собственных, немало форматов файловых систем, используемых другими ОС. Если способ записи на эти файловые системы известен и не слишком замысловат, то работает и запись, и чтение, в противном случае - только чтение (чего нередко бывает достаточно). Полностью поддерживаются файловые системы FAT12/FAT16/FAT32 (тип vfat), используемые в MS-DOS и Windows, ранние версии UFS, используемые в системах семейства BSD. Новые версии UFS (например, UFS2 из FreeBSD5, обладающая свойствами, которые не входят в стандарт Linux) поддерживаются только на чтение, как и созданная на основе DEC VMS, но впоследствии многократно переработанная файловая система NTFS из Windows.
Для того чтобы смонтировать файловую систему, имеющую заданный тип, команде mount необходимо указать его с помощью ключа "-t":
[root@localhost root]# fdisk -l . . . Device Boot Start End Blocks Id System /dev/hda1 * 1 25 100768+ 6 FAT16 /dev/hda2 26 520 1995840 5 Extended /dev/hda5 26 282 1036192+ 83 Linux /dev/hda6 283 334 209632+ 82 Linux swap /dev/hda7 335 520 749920+ 83 Linux [root@localhost root]# mount -t vfat /dev/hda1 /mnt/disk [root@localhost root]# ls /mnt/disk autoexec.bat config.sys fdconfig.sys freedos.bss command.com fdconfig.old fdos kernel.sys
Пример 11.9. Монтирование файловой системы FAT16 (html, txt)
Права доступа к устройствам
Некоторые устройства просто обязаны быть доступны пользователю на запись и чтение. Например, виртуальная консоль, за которой работает Мефодий, доступна пользователю methody на запись и на чтение, именно поэтому командный интерпретатор Мефодия может посылать туда символы и считывать их оттуда. В то же время терминал, за которым работает Гуревич, другому пользователю недоступен, а терминалы, за которыми не работает никто, доступны только суперпользователю:
methody@localhost ~ $ who methody tty1 Dec 3 16:02 (localhost) shogun ttyS0 Dec 3 16:03 (localhost) methody@localhost ~ $ ls -l /dev/tty1 /dev/tty2 /dev/ttyS0 crw--w---- 1 methody tty 4, 1 Дек 3 16:02 /dev/tty1 crw------- 1 root root 4, 2 Дек 3 15:51 /dev/tty2 crw--w---- 1 shogun tty 4, 64 Дек 3 16:03 /dev/ttyS0 methody@localhost:~ $ ls -l /usr/bin/write -rwx--s--x 1 root tty 8708 Июн 25 14:00 /usr/bin/write
Пример 11.4. Кому принадлежат терминалы? (html, txt)
Права на владение терминалом передаются с помощью chown пользователю программой login после успешной регистрации в системе. Она же выставляет право записи на терминал членам группы tty. "Настоящих" пользователей в этой группе может и не быть, зато есть setGID-программы, например, write, которая умеет выводить сообщения сразу на все активные терминалы.
Множество устройств в системе, используемой как рабочая станция, также отдаются во владение - на этот раз первому пользователю, зарегистрировавшемуся в системе. Предполагается, что компьютер служит рабочей станцией именно этого пользователя, а все последующие доступа к этим устройствам не получат2). Как правило, так поступают с устройствами, которые могут понадобиться только одному человеку, сидящему за монитором: звуковыми и видеокартами, лазерными приводами, дисководом и т.п.:
Пример 11.5. Кому принадлежат устройства? (html, txt)
При этом для того чтобы обеспечить доступ и другим - псевдо- или настоящим - пользователям, такие устройства также принадлежат определенным группам с соответствующими правами. Практика "раздачи" устройств группам вообще очень удобна: даже если доступ к устройству имеет только суперпользователь, существует возможность написать setGID-программу, которая, не получая суперпользовательских прав, сможет до этого устройства добраться (а можно и просто включить опытного пользователя в такую группу).
Представление устройства в системе
В лекции 10 говорилось о том, что аппаратный профиль компьютера определяется ядром на ранних этапах загрузки системы или в процессе подключения модуля. Это не означает, что устройство, не распознанное ядром, задействовать невозможно. Если неизвестным ядру устройством можно управлять по какому-нибудь стандартному протоколу, вполне возможно, что среди пакетов Linux найдется утилита или служба, способная с этим устройством работать. Например, программа записи на лазерный диск cdrecord знает великое множество разнообразных устройств, отвечающих стандарту SCSI, в то время как ядро, как правило, только позволяет работать с таким устройством как с обычным лазерным приводом (на чтение) и передавать ему различные SCSI-команды.
К сожалению, иногда обратное неверно: если производитель создает новое устройство, управлять которым нужно по-новому, а распознается оно как одно из старых, ошибки неизбежны. Многие стандарты внешних устройств предусматривают строгую идентификацию модели, однако хорошего мало и тут: незначительно изменив схемотехнику, производитель меняет и идентификатор, и устройство перестает распознаваться до тех пор, пока автор соответствующего модуля Linux не заметит этого и не добавит новый идентификатор в список поддерживаемых.
Большинству распознанных устройств, если они должны поддерживать операции чтения/записи или хотя бы управления (ioctl(), описанный ниже), соответствует файл-дырка в каталоге /dev или одном из его подкаталогов. В зависимости от того, выбрана ли в системе статическая или динамическая схема именования устройств, файлов-дырок в /dev может быть и очень много, и относительно мало. При статической схеме именования то, что ядро распознало внешнее устройство, никак не соотносится с тем, что в /dev имеется для этого устройства файл-дырка:
[root@localhost root]# cat /dev/sdg14 cat: /dev/sdg14: No such device or address
Пример 11.1. Обращение к несуществующему устройству (html, txt)
Здесь Мефодий попытался прочитать что-либо из устройства /dev/sdg14, что соответствует четырнадцатому разделу SCSI-диска под номером 7. Такого диска в этой машине, конечно, нет, а файл-дырка для него заведен на всякий случай: вдруг появится? Поскольку появиться может любое из поддерживаемых Linux устройств, таких файлов "на всякий случай" в системе бывает и десять тысяч, и двадцать. Файл-дырка не занимает места на диске, однако использует индексный дескриптор, поэтому в корневой файловой системе, независимо от ее объема, должен быть изрядный запас индексных дескрипторов.
При динамической схеме именования применяется специальная виртуальная файловая система, которая либо полностью подменяет каталог /dev, либо располагается в другом каталоге (например, /sys), имеющем непохожую на /dev иерархическую структуру; в этом случае файлы-дырки в /dev заводит специальная служба. Этот способ гораздо удобнее и для человека, который запустил команду ls /dev, и для компьютера (в случае подключения внешних устройств, например, съемных жестких дисков, "на лету"). Однако он требует соблюдать дополнительную логику "привязки" найденного устройства к имени, иногда весьма запутанную из-за той же нечеткой идентификации. Поскольку происходить это должно в самый ответственный момент, при загрузке системы, динамическую схему именования используют с осторожностью.
Виртуальная файловая система. Механизм отображения в виде файловой системы любых иерархически организованных данных. Существенно упрощает доступ к таким данным, так как позволяет применять обычные операции ввода-вывода: открытие и закрытие файла, чтение и запись и т.п.
No such device or
| [root@localhost root]# cat /dev/sdg14 cat: /dev/sdg14: No such device or address |
| Пример 11.1. Обращение к несуществующему устройству |
| Закрыть окно |
| [root@localhost root]# ls -l /dev/cdrom /dev/mouse lrwxrwxrwx 1 root root 8 Nov 20 23:23 /dev/cdrom -> /dev/hdc lrwxrwxrwx 1 root root 5 Nov 9 01:16 /dev/mouse -> psaux [root@localhost root]# ls -lL /dev/cdrom /dev/mouse /dev/hda1 /dev/ur* /dev/ze* brw-r----- 1 root cdrom 22, 0 Jul 26 16:59 /dev/cdrom brw-rw---- 1 root disk 3, 1 Jul 26 16:59 /dev/hda1 crw------- 1 root root 10, 1 Dec 2 11:58 /dev/mouse crw-r--r-- 1 root root 1, 9 Nov 28 14:10 /dev/urandom crw-rw-rw- 1 root root 1, 5 Jul 26 16:59 /dev/zero |
| Пример 11.2. Идентификация внешних устройств в /dev/ |
| Закрыть окно |
| methody@localhost:~ $ mkfifo hole methody@localhost:~ $ ( date >> hole & head -1 < hole ) 2> /dev/ null Птн Дек 3 15:11:05 MSK 2004 methody@localhost:~ $ ( cal >> hole & head -1 < hole ) 2> /dev/null Декабря 2004 methody@localhost:~ $ rm hole |
| Пример 11.3. Использование именованного канала |
| Закрыть окно |
| methody@localhost ~ $ who methody tty1 Dec 3 16:02 (localhost) shogun ttyS0 Dec 3 16:03 (localhost) methody@localhost ~ $ ls -l /dev/tty1 /dev/tty2 /dev/ttyS0 crw--w---- 1 methody tty 4, 1 Дек 3 16:02 /dev/tty1 crw------- 1 root root 4, 2 Дек 3 15:51 /dev/tty2 crw--w---- 1 shogun tty 4, 64 Дек 3 16:03 /dev/ttyS0 methody@localhost:~ $ ls -l /usr/bin/write -rwx--s--x 1 root tty 8708 Июн 25 14:00 /usr/bin/write |
| Пример 11.4. Кому принадлежат терминалы? |
| Закрыть окно |
| shogun@localhost ~ $ ls -l /dev | grep methody | wc 665 6649 41459 shogun@localhost ~ $ ls -lL /dev/{audio,cdrom,fd0,hda,kmem} crw-rw---- 1 methody audio 14, 4 Июл 26 16:59 /dev/audio brw-r----- 1 methody cdrom 22, 0 Июл 26 16:59 /dev/cdrom brw-rw---- 1 methody floppy 2, 0 Июл 26 16:59 /dev/fd0 brw-rw---- 1 root disk 3, 0 Июл 26 16:59 /dev/hda crw-r----- 1 root kmem 1, 2 Июл 26 16:59 /dev/kmem |
| Пример 11.5. Кому принадлежат устройства? |
| Закрыть окно |
| [root@localhost root]# fdisk -l Disk /dev/hda: 2147 MB, 2147483648 bytes 128 heads, 63 sectors/track, 520 cylinders Units = cylinders of 8064 * 512 = 4128768 bytes Device Boot Start End Blocks Id System /dev/hda1 * 1 25 100768+ 6 FAT16 /dev/hda2 26 520 1995840 5 Extended /dev/hda5 26 282 1036192+ 83 Linux /dev/hda6 283 334 209632+ 82 Linux swap /dev/hda7 335 520 749920+ 83 Linux |
| Пример 11.6. Просмотр таблицы разделов жесткого диска |
| Закрыть окно |
| root@localhost root]# mount /dev/hda5 on / type ext3 (rw) /dev/hda7 on /home type ext3 (rw) /dev/fd0 on /mnt/floppy type subfs (rw,nosuid,nodev,sync) /dev/hdc on /mnt/cdrom type subfs (ro,nosuid,nodev) proc on /proc type proc (rw,gid=19) devpts on /dev/pts type devpts (rw,gid=5,mode=0620) [root@localhost root]# umount /home [root@localhost root]# ls /home [root@localhost root]# mount /dev/hda7 /home [root@localhost root]# ls /home methody shogun tmpuser |
| Пример 11.7. Просмотр списка смонтированных файловых систем |
| Закрыть окно |
| /dev/hda5 / ext3 defaults 1 1 devpts /dev/pts devpts gid=5,mode=0620 0 0 /dev/hda7 /home ext3 defaults 1 2 proc /proc proc gid=19 0 0 /dev/ hda6 swap swap defaults 0 0 /dev/fd0 /mnt/floppy subfs fs=floppyfss,sync,nodev,nosuid /dev/cdrom /mnt/cdrom subfs fs=cdfss,nodev,nosuid |
| Пример 11.8. Содержимое /etc/fstab |
| Закрыть окно |
| [root@localhost root]# fdisk -l . . . Device Boot Start End Blocks Id System /dev/hda1 * 1 25 100768+ 6 FAT16 /dev/hda2 26 520 1995840 5 Extended /dev/hda5 26 282 1036192+ 83 Linux /dev/hda6 283 334 209632+ 82 Linux swap /dev/hda7 335 520 749920+ 83 Linux [root@localhost root]# mount -t vfat /dev/hda1 /mnt/disk [root@localhost root]# ls /mnt/disk autoexec.bat config.sys fdconfig.sys freedos.bss command.com fdconfig.old fdos kernel.sys |
| Пример 11.9. Монтирование файловой системы FAT16 |
| Закрыть окно |
| [root@localhost root]# ls -F / proc 1/ 585/ 793/ 882/ es1371 irq/ modules stat 1041/ 598/ 794/ acpi/ execdomains kcore mounts@ swaps 16/ 6/ 795/ bus/ fb kmsg mtrr sys/ 2/ 681/ 796/ cmdline filesystems ksyms net/ sysrq-trigger 3/ 697/ 797/ cpufreq fs/ loadavg partitions sysvipc/ 4/ 7/ 798/ cpuinfo ide/ locks pci tty/ 492/ 725/ 8/ devices interrupts mdstat scsi/ uptime 5/ 751/ 840/ dma iomem meminfo self@ version 572/ 784/ 844/ driver/ ioports misc slabinfo [root@localhost root]# ls -l /proc/1 total 0 -r--r--r-- 1 root proc 0 Dec 4 16:15 cmdline lrwxrwxrwx 1 root proc 0 Dec 4 16:15 cwd -> / -r-------- 1 root proc 0 Dec 4 16:15 environ lrwxrwxrwx 1 root proc 0 Dec 4 16:15 exe -> /sbin/init dr-x------ 2 root proc 0 Dec 4 16:15 fd -r--r--r-- 1 root proc 0 Dec 4 16:15 maps -rw------- 1 root proc 0 Dec 4 16:15 mem -r--r--r-- 1 root proc 0 Dec 4 16:15 mounts lrwxrwxrwx 1 root proc 0 Dec 4 16:15 root -> / -r--r--r-- 1 root proc 0 Dec 4 16:15 stat -r--r--r-- 1 root proc 0 Dec 4 16:15 statm -r--r--r-- 1 root proc 0 Dec 4 16:15 status [root@localhost root]# cat /proc/1/environ ; echo HOME=/TERM=linux |
| Пример 11.10. Виртуальная файловая система PROCFS |
| Закрыть окно |
| [root@localhost root]# ls -l floppy.flp -rw-r--r-- 1 root root 1474560 Dec 4 16:53 floppy.flp [root@localhost root]# mount -t vfat -o loop floppy.flp /mnt/disk/ [root@localhost root]# ls /mnt/disk/ command.com kernel.sys [root@localhost root]# mount | grep disk /root/floppy.flp on /mnt/disk type vfat (rw,loop=/dev/loop0) |
| Пример 11.11. Монтирование содержимого файла при помощи mount -o loop |
| Закрыть окно |
|
[root@localhost root]# fsck -fy /home fsck 1.35 (28-Feb-2004) /dev/hda7 is mounted. WARNING!!! Running e2fsck on a mounted filesystem may cause SEVERE filesystem damage. Do you really want to continue (y/n)? no check aborted. [root@localhost root]# umount /home [root@localhost root]# fsck /home fsck 1.35 (28-Feb-2004) e2fsck 1.35 (28-Feb-2004) /dev/hda7: clean, 168/93888 files, 7269/187480 blocks [root@localhost root]# fsck -f /home fsck 1.35 (28-Feb-2004) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/hda7: 168/93888 files (0.6% non-contiguous), 7269/187480 blocks |
| Пример 11.12. Использование fsck |
| Закрыть окно |
Принципы организации данных на диске
Во всех файловых системах есть немало общего. Например, в каждой из них решается вопрос метаданных, то есть информации, не имеющей прямого отношения к содержимому, допустим, файла, но описывающей, как до этого содержимого добраться. В файловой системе обычно различается системная область, в которой записываются метаданные, и область данных, где хранятся собственно файлы. Системная область может составлять заметную долю общего дискового пространства, и вот почему.
Различают устройство последовательного доступа (например, накопители на магнитных лентах) и устройства прямого доступа (например, жесткие диски). Чтение (и запись) данных на устройства последовательного доступа идет последовательно: если сейчас записан первый блок носителя, то следующим будет доступен второй, за ним - третий и т.д. Если доступен пятый блок, а нужен первый или тысячный, выполняется длительная операция позиционирования, причем она тем длиннее, чем дальше отстоит нужный блок от текущего: лента перематывается. Работать с устройствами прямого доступа легче: каков бы ни был текущий прочитанный блок, время, за которое будет прочитан любой другой, примерно одинаковое.
Файлы на магнитной ленте удобнее хранить целиком, каждый файл - одним длинным куском. У такого способа есть один существенный недостаток: если на ленту объемом в один гигабайт записать 1024 мегабайтных файла, а потом удалить каждый второй, то образуется полгигабайта свободного места, но кусочками по мегабайту каждый. Тогда запись, скажем, двухмегабайтного файла потребует трех операций: сначала надо переписать какой-нибудь мегабайтный файл на свободное место, затем удалить старую его копию, и только затем записать на образовавшееся место большой файл.
На устройстве прямого доступа можно избежать этой неприятной ситуации, если постановить, что файл может размещаться на нем в области данных по частям, а карта размещения этих частей будет записана в системную область. Если, не мудрствуя, предположить, что в системную область записываются номера полукилобайтных секторов, в которых лежит файл (по 32 бита каждый номер), то выходит, что размер системной области, который может потребоваться, всего в 16 раз меньше файловой. Но в Linux в системную область записываются индексные дескрипторы, размер которых существенно больше. Количество индексных дескрипторов может быть намного меньше количества блоков, но все же системная область занимает примерно такую же (от пяти до десяти процентов) долю общего дискового пространства.
Индексный дескриптор, inode. Внутренний объект файловой системы Linux, однозначно определяющий принадлежащий ей файл. Индексный дескриптор содержит атрибуты файла, размер, указывает расположение файла на диске и т.п. Каждому индексному дескриптору соответствует единственный в данной файловой системе идентификатор - целое число.
На самом деле, даже на жестком диске блоки, расположенные подряд, считываются (и записываются) быстрее, чем блоки, расположенные как попало. Эффект связан с механическим устройством жестких дисков, пояснять которое Мефодию Гуревич не стал, ссылаясь на общеизвестность. Суть его в том, что задержки при чтении данных, находящихся на разных цилиндрах диска, растут линейно, как для ленты (чем дальше, тем дольше). Один из остроумных способов оптимизировать работу с диском состоит в том, чтобы разбить все цилиндры на группы, а внутри каждой группы выделить свою системную область и область данных. Тогда сами файлы и их индексные дескрипторы будут лежать, если это возможно, на соседних цилиндрах, и доступ ускорится.
Другое, более общее решение - использование кеширования, при котором данные с диска частично дублируются в памяти. Если какой-то процесс прочитал данные из файла, эти данные некоторое время находятся в памяти, на случай, если они ему (или кому-нибудь другому) опять понадобятся. Повторное обращение уже не дойдет до диска, система вернет процессу данные из кеша, раз уж они ничем не отличаются от тех, что на диске. Если процесс записал данные на диск, содержимое кеша обновляется, оставаясь актуальным.
Еще эффективней кеш на запись: операции записи накапливаются в памяти, а до диска добираются не сразу, и в том порядке, в каком быстрее пройдет запись, а не в том, в каком были выполнены. Если запись шла во временный файл, который, в конце концов, удалили, обращений к диску может вообще не случиться. Однако с кешированием операций записи следует обращаться бережно: а вдруг сбой в электропитании произойдет именно тогда, когда часть данных уже записана, а часть - еще нет? А если не полностью, кусочками, обновилась системная область, состояние файловой системы после того, как питание опять включат, может оказаться совсем плачевным - настолько, что даже утилита восстановления fsck может оказаться бессильной. Поэтому системные области либо вообще не кешируются на запись, либо делают это исключительно с помощью будущих кандидатов и докторов наук, которые рассчитывают безопасные алгоритмы обновления файловой системы из кеша на запись...
Проверка файловой системы
Если доступная на запись файловая система не была размонтирована перед выключением компьютера, после включения она окажется в нештатном состоянии, независимо от того, испортилось на ней что-либо или нет. Проверкой цельности файловой системы занимается утилита fsck (file system check). На самом деле таких утилит несколько - по одной для каждого из основных типов файловых систем (есть fsck даже для VFAT). Как уже говорилось в лекции 10, fsck запускается при старте Linux, если файловая система находится в нештатном состоянии, или для профилактики, если файловую систему просто давно не проверяли.
В самом лучшем случае fsck не находит ничего подозрительного, и система продолжает загрузку. Чаще всего, даже если в файловой системе не все в порядке, ее журнал не испорчен, и fsck "проигрывает" его, после чего все опять приходит в норму. Запустить fsck можно и вручную, в виде fsck устройство или fsck точка_монтирования, однако прежде следует размонтировать файловую систему:
Пример 11.12. Использование fsck (html, txt)
Со второго раза fsck 1) работать тоже отказалась, ссылаясь на то, что файловая система и так находится в штатном состоянии (ее аккуратно размонтировали). Пришлось применить ключ "-f" (force), который заставляет fsck работать - конечно же, никаких ошибок найдено не было. Сама процедура проверки довольно сложна - она состоит из пяти этапов, каждый из которых отнюдь не тривиален и в этой лекции не описывается. Кстати сказать, для того чтобы проверить корневую файловую систему, ее приходится сначала монтировать только на чтение, находить там /sbin/fsck, проверять и только после этого монтировать на чтение-запись. Если корневая файловая система испорчена настолько, что /sbin/fsck в ней найти невозможно, остается пробовать загрузку с других носителей (например, с установочного CD) и разбираться.
Если какая-то порча файловой системы все-таки обнаружилась, fsck может поступить двояко. Во-первых, все ошибки, которые не приводят к изменению данных на диске, можно попробовать исправить автоматически. Например, индексные дескрипторы, на которые не ссылается ни одно имя (так называемые потерянные файлы, unref files), помещаются в специальный каталог /lost+found под именами, соответствующими номерам этих индексных дескрипторов. Впоследствии администратор может посмотреть в эти файлы и решить, нужны они или нет. Во-вторых, когда fsck встречается с ошибкой, исправление которой приведет к изменению данных на диске, загрузка Linux останавливается, и система переходит в однопользовательский режим. Предполагается, что администратор сам запустит fsck: либо интерактивно (тогда каждому изменению в файловой системе будет требоваться подтверждение с клавиатуры), либо пакетно, с ключом "-y" (тогда считается, что на все запросы администратор заранее ответил "yes").
Когда-то такие запуски fsck -y производили катастрофические разрушения по вине неумелых администраторов, а нынче Мефодий, как ни нажимал "Reset" на многострадальной двухсистемной машине, не смог добиться ничего, кроме двух-трех мгновенных воспроизведений журнала и жестокого нагоняя от Гуревича.
1)
Если стандартный вывод ошибок всего конвейера перенаправлен в /dev/null, то командный интерпретатор не выводит сообщений о запуске и остановке фонового процесса.
2)
Как говорится, "кто первым встал - того и тапки".
3)
Для некоторых других файловых систем, например, для vfat, это неверно.
4)
Осторожнее с программой fdisk! Она предназначена для создания, изменения и удаления разделов диска.
5)
Такая ситуация называется "дребезг" (trashing) и свидетельствует о том, что для текущих задач компьютеру требуется больше физической памяти.
6)
Мефодий заметил, что /tmp и /var не смонтированы никуда, и, следовательно, корневая файловая система, вопреки рекомендациям FHS, слишком часто используется на запись.
7)
Мефодий заметил, что для файловой системы Ext3 запустилась специализированная версия e2fsck, подходящая также и для Ext2.

|
| © 2003-2007 INTUIT.ru. Все права защищены. |
Работа с файловыми системами
Итак, Linux свободно работает (и даже предпочитает работать) с несколькими разделами диска, содержащими, возможно, разные типы файловых систем.
Работа с устройствами
Все файлы-дырки подчиняются одним и тем же правилам работы с файлами: их можно открывать для записи или чтения, записывать данные или считывать их стандартными средствами, а по окончании работы - закрывать. Открытие и закрытие файла (системные вызовы open() и close()) в командном интерпретаторе не представлены отдельной операцией, а выполняются автоматически при перенаправлении ввода (открытия на чтение) или вывода (на запись). Это позволяет работать и с устройствами, и с каналами, и с файлами совершенно одинаково, что активно используется в Linux программами-фильтрами. Каждый тип файлов имеет свою специфику, например, при записи на блочное устройство данные накапливаются ядром в специальном буфере размером в один блок, и только после заполнения буфера записываются. Если при закрытии файла буфер неполон, он все равно передается целиком: часть - данные, записанные пользователем, часть - данные, оставшиеся от предыдущей операции записи). Это, конечно, не означает, что из файла, находящегося на блочном устройстве, легко по ошибке прочитать такой "мусор": длина файла известна, и ядро само следит за тем, чтобы программа не прочла лишнего.
Даже такие, казалось бы, простые устройства, как жесткие диски, поддерживают гораздо больше различных операций, чем просто чтение или запись. Пользователю, как минимум, может потребоваться узнать размер блока (для разных типов дисков он разный) или объем всего диска в блоках. Для многих устройств собственно передача данных - лишь итог замысловатого общения с управляющей программой или ядром. Скажем, для вывода оцифрованного звука на звуковую карту сначала необходимо настроить параметры звукогенератора: частоту, размер шаблона, количество каналов, формат передаваемых данных и многое другое. Для управления устройствами существует системный вызов ioctl() (iputoutput control): устройство надо открыть, как файл, а затем использовать эту функцию. У каждого устройства - свой набор команд управления, поэтому в виде отдельной утилиты ioctl() не встречается, а используется неявно другими утилитами, специализирующимися на определенном типе устройств.
Разметка диска IBM-совместимого компьютера
Таблица разделов, таблица разбиения диска, HDPT. Небольшая часть жесткого диска, описывающая геометрию и тип его разделов. Стандартная таблица разделов диска IBM-совместимого компьютера может содержать не более четырех разделов.
Разбиение диска на разделы - дело (теоретически) несложное: какая-то часть диска должна быть отведена под таблицу разделов, в которой и будет написано, как разбит диск. Стандартная таблица разделов для диска IBM-совместимого компьютера - HDPT (hard disk partition table) - располагается в конце самого первого сектора диска, после предзагрузчика (master boot record, MBR) и состоит из четырех записей вида "тип начало конец", описывающих очередной раздел диска (если раздела нет, поле тип устанавливается в 0). Разделы, упомянутые в HDPT диска, принято называть основными (primary partition). Устройство Linux, соответствующее первому диску компьютера, обычно называется /dev/hda (hard disk "a"). Второй диск получает имя hdb, третий - hdc и так далее. На типичном IBM-совместимом компьютере такое же имя получит и лазерный накопитель. Часто бывает, что жесткий диск - первый в системе (hda), а лазерный накопитель - третий (hdc); второго же вовсе нет. Устройства, соответствующие основным разделам диска, называются /dev/hdбукваномер, для первого диска - от hda1 до hda4. Просмотреть список разделов можно с помощью команды fdisk -l.
Разметка диска и именование устройств
В начале лекции говорилось о том, что младший номер устройства, соответствующего жесткому диску, обычно указывает на определенный раздел этого диска. Поначалу Мефодию казалось, что смысла "пилить" диск на несколько разделов нет: известно, что один большой раздел файловой системы Linux1) вмещает чуть больше данных, чем несколько маленьких того же объема. Кроме того, разбивая диск на разделы, можно не предугадать подходящие размеры этих разделов, и тогда размещение на них файловой системы Linux окажется делом нелегким, если вообще возможным, так как структура дерева каталогов Linux строго определена стандартом FHS (см. лекцию 3).
Раздел диска. Часть жесткого диска, используемая под определенные задачи: файловую систему того или иного типа, область подкачки и т.п. Изменение содержимого и типа одного раздела никак не сказывается на других.
Впрочем, в том же FHS весьма наглядно обоснована необходимость разнесения всего дерева каталогов по разным разделам, каждый из которых будет иметь собственную файловую систему. Каталоги сильно различаются по тому, как часто приходится в них записывать, насколько надежность хранения данных в них важнее быстродействия и насколько ситуация переполнения файловой системы опасна и может помешать работе. Поэтому стоит держать каталог /tmp, требующий очень частой записи, но не требующий надежного хранения данных после перезагрузки, не на том же разделе, что и корневую файловую систему, запись в которую происходит редко (в каталог /etc), но требует повышенной надежности. В отдельный раздел можно поместить весь каталог /usr, так как он вообще не требует операций записи. Наконец, такие каталоги, как /var или /home, суммарный объем файлов в которых с трудом поддается контролю со стороны системы, тоже не следует размещать на том же разделе, что и корневую файловую систему, переполнение которой может быть болезненно воспринято Linux.
К тому же на компьютере может быть установлено несколько операционных систем, и каждой из них понадобится для корневой файловой системы отдельный раздел. В примерах этой и предыдущей лекций Мефодий работает именно за такой машиной: помимо Linux, на ней установлен FreeDOS для запуска одной-единственной программы.
Совмещение нескольких схем разметки
На той самой - двухсистемной - машине fdisk обнаружила пятый, шестой и седьмой разделы, однако не показала ни третий, ни четвертый:
[root@localhost root]# fdisk -l Disk /dev/hda: 2147 MB, 2147483648 bytes 128 heads, 63 sectors/track, 520 cylinders Units = cylinders of 8064 * 512 = 4128768 bytes Device Boot Start End Blocks Id System /dev/hda1 * 1 25 100768+ 6 FAT16 /dev/hda2 26 520 1995840 5 Extended /dev/hda5 26 282 1036192+ 83 Linux /dev/hda6 283 334 209632+ 82 Linux swap /dev/hda7 335 520 749920+ 83 Linux
Пример 11.6. Просмотр таблицы разделов жесткого диска (html, txt)
Дело в том, что четырех разделов редко когда бывает достаточно. Куда же помещать дополнительные поля таблицы разбиения? Создатели IBM PC предложили универсальный способ: один из четырех основных разделов объявляется расширенным (extended partition); он, как правило, занимает все оставшееся пространство диска. Расширенный раздел разбивается на подразделы по тем же правилам, что и весь диск: в самом его начале заводится HDPT с четырьмя записями (соответствующие им разделы называются дополнительными (secondary partition), которые снова можно использовать, причем один из подразделов может быть, опять-таки, расширенным, со своими подразделами и т.д.2)
Чтобы не усложнять эту схему, при разметке диска соблюдают два правила: во-первых, расширенных разделов в таблице разбиения диска может быть не более одного, а во-вторых, таблица разбиения расширенного раздела может содержать либо одну запись - описание дополнительного раздела, либо две - описание дополнительного раздела и описание вложенного расширенного раздела. Соблюдение этого правила позволяет в Linux нумеровать разделы линейно: после четырех основных номер 5 получает дополнительный раздел в первом расширенном, 6 - раздел во втором расширенном, вложенным в первый, и т. п. Сами вложенные расширенные разделы при этом не нумеруются и никакому устройству в /dev/ не соответствуют. В действительности разбиение диска двухсистемной машины Мефодия выглядит как на рис.11.1.
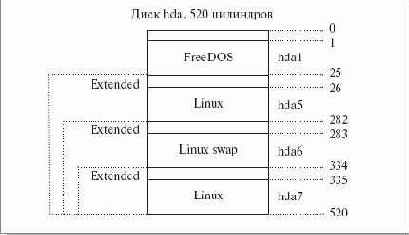
Рис. 11.1. Разбиение диска двухсистемного компьютера
И разделы, и таблицы разбиения принято размещать с начала цилиндра (термин, имеющий отношение к внутреннему устройству жесткого диска), так что при заведении каждого расширенного раздела на этом компьютере тратилось впустую по четыре мегабайта (таков, по сведениям fdisk, размер цилиндра).
Той же тактикой - разбиением не диска, а раздела - пользуются, когда таблица разбиения нестандартна для IBM PC. Например, UNIX-подобные системы семейства BSD используют собственный универсальный формат разбиения (он старше, чем сама идея об IBM PC!), для чего подобной системе выделяется один раздел, и она творит с ним все, что заблагорассудится.
Виртуальные и сетевые файловые системы
В /etc/fstab Мефодий сразу заметил две строки, начинающиеся не с имени устройства, а с названия виртуальной файловой системы, содержимое которой доступно в соответствующей точке монтирования. Виртуальная файловая система обычно не обращается ни к какому внешнему устройству, а "придумывает" все дерево каталогов и находящиеся в них файлы сама. Такова, например, файловая система в памяти (ROMFS, или аналогичная ей TMPFS, поддерживающая операции записи), используемая в стартовом виртуальном диске. Как правило, виртуальные файловые системы используются для того, чтобы предоставить доступ по чтению/записи к некоторой иерархической структуре данных.
Во многих версиях UNIX программа ps работает непосредственно с устройством /dev/kmem (памятью ядра), чтобы добыть оттуда информацию о таблицах процессов; это сложная и даже опасная программа, имеющая доступ к святая святых системы. В Linux ps может быть переписана чуть ли не на shell, потому что таблица процессов и масса другой информации о системе доступны в виде дерева подкаталогов /proc:
Пример 11.10. Виртуальная файловая система PROCFS (html, txt)
В частности, подкаталоги /proc с числовыми именами содержат информацию о процессах с соответствующими PID. Файл exe такого подкаталога - символьная ссылка на запущенную программу, файл cmdline содержит командную строку, а environ - окружение процесса. Мефодий углубился в чтение man proc, руководства по PROCFS, и, как всегда, убедился, что для полного понимания всего, что есть в /proc, ему пока не хватает знаний.
Файловая система devpts - шаг навстречу динамическому именованию устройств. Она предназначена для эмуляторов терминала, таких как sshd, xterm или screen. Задача эмулятора терминала - предоставить пользователю полноценный интерфейс командной строки (с запуском командного интерпретатора, с распознаванием и передачей сигналов и т.п.) в отсутствие терминального оборудования - по сети или из графической подсистемы, или при необходимости сымитировать несколько терминалов. Раньше для этого использовались пары устройств /dev/pty## - /dev/tty##, где ## - двухсимвольный идентификатор. Программа-эмулятор начинала обмениваться данными (от пользователя или из сети) с первым свободным устройством (скажем, ptya2, которое, в свою очередь, было привязано к соответствующему терминальному устройству (ttya2)). Именно с этим устройством и взаимодействовал командный интерпретатор и прочие процессы Linux, находясь в полной уверенности, что это полноценный терминал.
Выходило, что пар tty##-pty## при статическом именовании устройств могло не хватить, даже если создать их очень много (достаточно запустить еще больше эмуляторов терминала). Поэтому придумали завести одно устройство типа pty - /dev/ptmx и виртуальную файловую систему /dev/pts для терминальных файл-дырок. Каждая программа, открывающая ptmx, получает свой дескриптор), а в pts/ заводится очередное терминальное устройство, имя которого совпадает с порядковым номером. Когда дескриптор закрывается, терминальное устройство исчезает.
Среди файловых систем есть и такие, что не выдумывают содержимое сами, а обращаются за ним еще куда-нибудь, например, в сеть. Так работают удаленные файловые системы, например, NFS (network file system), стандартная для всех UNIX-подобных ОС. Вместо поля "устройство" обычно указывается сетевой адрес компьютера-сервера и имя ресурса (название каталога), который необходимо смонтировать по сети. Поддерживается и работа с удаленными файловыми системами Windows, причем как на уровне модулей ядра, с помощью mount -t smbfs, так и без монтирования, с помощью утилиты smbclient. Linux и сама может служить сервером, предоставляющим удаленный доступ к файлам, причем служба samba, занимающаяся файловыми системами для Windows под управлением Linux, работает зачастую быстрее, чем Windows, запущенный на том же компьютере для тех же целей.
Возможности файловых систем этим не исчерпываются. Например, можно смонтировать образ устройства из файла, если вызвать команду mount с ключом -o loop. Образ устройства - это файл, содержимое которого в точности повторяет содержимое устройства; его можно, например, получить с помощью команды cat устройство образ. Именно образами устройств манипулируют программы записи на лазерные носители. Смонтировать образ бывает нужно для проверки или изменения содержимого перед записью, или для хранения содержимого нескольких дисков в исходном виде:
Пример 11.11. Монтирование содержимого файла при помощи mount -o loop (html, txt)
Как заметил Мефодий, mount создает для такого способа монтирования специальное устройство - /dev/loop0, и уже с его помощью работает с файлом.
Обширное поле для экспериментов - так называемая пользовательская файловая система (linux userland file system, LUFS). Это модуль ядра и набор библиотек, позволяющий организовать файловую систему, обращающуюся за информацией к обычному процессу Linux. Так организованы разнообразные сетевые "эмуляторы" файловых систем с использованием протокола FTP или Secure Shell. Так работает и доступ на запись к файловой системе NTFS: некоторая программа обращается к устройству, содержащему файловую систему, задействует драйвер NTFS, взятый из лицензионной копии самой Windows (это можно сделать с помощью библиотек wine, подсистемы, распознающей исполняемые форматы Windows), и обменивается данными с модулем LUFS, который и предоставляет обычный файловый доступ процессам.
[root@localhost root]# ls -l floppy.flp -rw-r--r-- 1 root root 1474560 Dec 4 16:53 floppy.flp [root@localhost root]# mount -t vfat -o loop floppy.flp /mnt/disk/ [root@localhost root]# ls /mnt/disk/ command.com kernel.sys [root@localhost root]# mount | grep disk /root/floppy.flp on /mnt/disk type vfat (rw,loop=/dev/loop0)
Пример 11.11. Монтирование содержимого файла при помощи mount -o loop
Как заметил Мефодий, mount создает для такого способа монтирования специальное устройство - /dev/loop0, и уже с его помощью работает с файлом.
Обширное поле для экспериментов - так называемая пользовательская файловая система (linux userland file system, LUFS). Это модуль ядра и набор библиотек, позволяющий организовать файловую систему, обращающуюся за информацией к обычному процессу Linux. Так организованы разнообразные сетевые "эмуляторы" файловых систем с использованием протокола FTP или Secure Shell. Так работает и доступ на запись к файловой системе NTFS: некоторая программа обращается к устройству, содержащему файловую систему, задействует драйвер NTFS, взятый из лицензионной копии самой Windows (это можно сделать с помощью библиотек wine, подсистемы, распознающей исполняемые форматы Windows), и обменивается данными с модулем LUFS, который и предоставляет обычный файловый доступ процессам.
Изменение конфигурационных файлов
Как правило, конфигурационный файл считывается программой при запуске, отражая, таким образом, ее состояние на момент старта. Изменения настроек работающей программы в конфигурационном файле, как правило, не отражаются. Тому есть несколько причин: не стоит превращать файл, изредка редактируемый пользователем, в файл, изменение которого происходит постоянно; не стоит держать конфигурационный файл всегда открытым; тяжело, изменяя файл автоматически, не испортить структуру комментариев (интерпретируемых не машиной, а пользователем) и т. д. Впрочем, многие утилиты, особенно использующие графическую среду, могут записывать настройки в файл по окончании работы. Большинство конфигурационных файлов весьма удобно редактировать вручную, с помощью Vi или Emacs (для файлов, более или менее похожих, используется общая подсветка синтаксиса, а для наиболее популярных существуют и собственные варианты подсветки).
В /etc хранятся настройки системных служб, в том числе настройки по умолчанию, настройки по умолчанию пользовательских утилит, профили командных интерпретаторов, а также настройки, используемые в процессе загрузки системы (например, modules.conf). Там же располагаются и стартовые сценарии, о которых рассказано в лекции 10. Чего не стоит искать в /etc, так это разнообразных примеров настройки той или иной службы. Считается, что пример – это часть документации, и их следует помещать, например, в /usr/share/doc/название_службы/examples.
Файлы, имеющие отношение к процессу досистемной загрузки, обычно лежат не там, а в /boot; это стоит иметь в виду, так как /boot/grub/menu.lst – тоже часть профиля системы, хотя и довольно специфическая. В профиль системы входит содержимое каталогов etc из так называемых "песочниц", расположенных обычно в /var/lib.
Смысл термина "песочница" вот в чем. В Linux есть замечательный системный вызов chroot() и использующая его утилита chroot, формат командной строки которой chroot каталог команда. Эта утилита запускает команду, изменив окружение таким образом, что та считает каталог корневым. Соответственно, все подкаталоги каталога представляются команде каталогами первого уровня вложенности, и т. д. Если необходимо во что бы то ни стало ограничить область действия некоторой утилиты (например, по причине ее небезопасности), можно запускать ее с помощью chroot. Тогда, даже имея права суперпользователя, эта утилита получит доступ только к каталогу и его подкаталогам, а /etc и прочие важные части системы окажутся в неприкосновенности. Сам каталог как раз и играет роль "песочницы", в которую утилиту "пустили поиграть", позволяя вытворять что угодно. Часто бывает, что в "песочнице" есть и свой каталог etc, содержащий необходимые для запуска утилиты (или системной службы) настройки. Вот этот-то etc из "песочницы" также входит в список каталогов, хранящих профиль системы.
В /etc могут находиться не только файлы, но и подкаталоги (особенно в стиле ".d") и целые поддеревья каталогов. Например, в некоторых дистрибутивах Linux используется подкаталог /etc/sysconfig. Этот каталог создается и заполняется файлами при установке системы или при запуске специального "конфигуратора" – программы-кудесника, задающей наводящие вопросы. Некоторые стартовые сценарии, использующие полученные настройки, также лежат в этом каталоге или его подкаталогах. Если в системе есть каталог /etc/sysconfig, там должны оказаться настройки, относящиеся не к самим службам или утилитам, а к способу их запуска при загрузке, а также языковые и сетевые настройки, тип мыши и т. д.
Конфигурационные файлы в домашнем каталоге
Немало конфигурационных файлов находится в домашнем каталоге пользователя. Этими файлами практически любая утилита может быть перенастроена по сравнению с обычным поведением, или поведением, задаваемым конфигурационным файлом из /etc. В Linux принято предоставлять пользователю возможность задавать профиль любого используемого им инструмента, начиная от простой утилиты и заканчивая графической подсистемой управления "рабочим столом" (см. об этом лекцию 15). Как правило, имена таких файлов или каталогов начинаются на ".", т. е. считаются скрытыми – для того, чтобы не засорять выдачу ls. Если пользователю нужно работать не со своими файлами, а именно с настройками, он всегда может применить ключ "-a" или "-A":
Пример 12.14. Конфигурационные файлы в домашнем каталоге (html, txt)
Многие утилиты создают конфигурационный файл при запуске, если его в домашнем каталоге пользователя нет, поэтому со временем объем ls -A становится все больше. Файл .lpoptions задает параметры подсистемы печати, .pinerc – это настройки почтового клиента pine, .viminfo – файл истории команд редактора Vim, а файл .Xauthority и каталог .xsession.d управляют запуском графической подсистемы X11, описанной в лекции 15. Из файлов в примере некоторые вообще не являются "стандартными": так, .aliases и .i18n просто "втягиваются" стартовым командным сценарием bash, потому что упомянуты в нем явно; строго говоря, они могли бы называться и по-другому. Все конфигурационные, стартовые и прочие вспомогательные файлы принято делать скрытыми, даже если никаких требований к их названиям нет.
Файл .pythonstartup (настройки интерпретатора языка программирования Python) выполняется потому, что имя этого файла задано в переменной окружения PYTHONSTARTUP. Мефодию пришлось дописать строку PYTHONSTARTUP="/home/methody/.pythonstartup"; export PYTHONSTARTUP в ~/.bash_profile и "C-i": complete в ~/.inputrc, чтобы достраивание заработало и в этом интерпретаторе. Еще один файл, .pyhistory, используется в самом .pythonstartup:
methody@localhost:~ $ cat .pythonstartup import atexit, os, readline, rlcompleter historyPath = os.path.expanduser("~/.pyhistory") def save_history(historyPath=historyPath): import readline readline.write_history_file(historyPath) if os.path.exists(historyPath): readline.read_history_file(historyPath) atexit.register(save_history) del os, atexit, readline, rlcompleter, save_history, historyPath
Пример 12.15. Стартовый файл интерпретатора Python (html, txt)
Подавляющее большинство конфигурационных файлов предназначено для того, чтобы их мог редактировать пользователь. Эти файлы часто имеют самодокументированный формат и/или сопровождаются руководством, нередко вынесенным в отдельный от руководства по самой утилите документ.
Конфигурационный файл
Задание профиля с помощью командной строки – метод далеко не всегда удобный. Даже при работе с самой командной строкой используется окружение для сохранения настроек, чтобы не задавать их всякий раз и для всякой команды. Что уж говорить о сложных системных службах, свойства которых должны сохраняться не от сеанса к сеансу, а постоянно (в том числе при перезагрузке системы). Вывод прост: профиль необходимо держать в файле, вроде того, что создается по команде "сохранить настройки".
Однако сам подход к хранению профиля в файле, при котором пользователь не может изменять этот файл напрямую, а пользуется "умными" конфигураторами, удобен только в случаях, когда настроек много, а цена ошибки невелика (например, при настройке внешнего вида рабочего стола). В общем случае довольно сложно задать поведение
системы на основании описания (часто неявного) свойств того, что эта система должна получать в результате. Иными словами, из описания того, что должно получиться, далеко не всегда можно автоматически сделать вывод, как оно должно получаться.
Конфигурационный файл. Текстовый файл, содержащий настройки какой-нибудь части системы (утилиты, демона и т. п.). Как правило, считывается ею при запуске. Типичный для Linux способ организации профиля.
Одним словом, если есть конфигурационный файл, то должны быть и средства редактирования этого файла. Учитывая, что в Linux реализована высокоразвитая система хранения и переработки (как ручной, так и автоматической) данных в текстовом виде, изобретать какой-то новый формат – все равно что изобретать велосипед. Тем более, что именно текст, разделенный на строки и слова, лучше всего подходит тогда, когда есть четкое деление профиля на объекты управления и их свойства (например, настройки какого-нибудь демона и значения этих настроек). Вдобавок, именно со структурированными текстами отменно управляются текстовые редакторы Linux: Vi, Emacs и др:
methody@localhost:~ $ cat .vimrc so $VIMRUNTIME/vimrc_example.vim " Some mappings map :wall!^M map! ^O:wall!^M " Tune up set shiftwidth=2 tabstop=8 history=200 viminfo='50 set showmode showmatch showcmd ruler modeline set autoindent ignorecase smartcase set nohlsearch noincsearch set dir=/var/tmp set wildmode=list:longest,full set wildmenu " Colouring syntax on colorscheme desert
Пример 12.2. Настройки редактора vim (html, txt)
Вот как выглядит конфигурационный файл для Vim, написанный Мефодием на основе файла, взятого у Гуревича. Легко заметить, что файл состоит из команд режима командной строки Vi с комментариями (в отличие от большинства утилит Linux, в Vi комментарии начинаются на """). Символы "^O" и "^M" – это именно соответствующие управляющие символы (вставленные в текстовый файл с помощью "^V", см. лекцию 9). Такой конфигурационный файл легко понимать и изменять.
Как уже было замечено, набор переменных окружения составляет особенный профиль, к которому чувствительны все запускаемые программы – в этом его достоинство. Задаются переменные окружения обычно в командном сценарии, который тоже можно рассматривать как конфигурационный файл). Например, во многих дистрибутивах используется конфигурационный файл .i18n для настройки языковых особенностей клавиатуры, языка вывода сообщений и т. п.1):
methody@localhost:~ $ cat .i18n LANG=ru_RU.KOI8-R LANGUAGE=ru_RU.KOI8-R SYSFONTACM=koi8-r SYSFONT=UniCyr_8x16 DICTIONARY=russian MPAGE="-CKOI8-R" export DICTIONARY MPAGE
Пример 12.3. Файл настройки языковых особенностей (html, txt)
Однако хранить настройки специфической программы (не нужные всем остальным) в окружении – не самое удачное решение: синтаксис, задающий переменную окружения, слишком прост (имя_переменной=значение), а самих переменных становится слишком много, поэтому при просмотре трудно выделить, какая из них к какой группе настроек относится. Если пытаться упаковать все настройки в значение одной переменной, это значение окажется трудночитаемым, и все преимущество текстового формата сойдет на нет. Например, стандартный конфигурационный файл утилиты ls (точнее, только ее цветовых предпочтений) – /etc/DIR_COLORS (его можно подменить личным файлом ~/.dir_colors) занимает около ста строк вместе с комментариями. Команда ls использует не этот файл, а создаваемую утилитой dircolors переменную LS_COLORS, значение которой – 600-символьная строка без всяких комментариев.
Если профиль слишком велик, держать его в одном конфигурационном файле – значит, доставлять пользователю сомнительное удовольствие разбирать этот файл целиком даже при необходимости внести минимальное изменение. Методов борьбы с неудобочитаемостью несколько. В частности, уже известный по лекции 10 механизм ".d": файл разделяется на несколько независимых друг от друга файлов так, что редактировать приходится только один из файлов, а программа во время самонастройки считывает все.
Другой способ опирается на то, что изменения, которые пользователь вносит в профиль, как правило, существенно меньше объема всего профиля. Поэтому может быть выгодно хранить все настройки по умолчанию в каком-нибудь файле, менять который вообще не надо, а файл пользовательских настроек использовать как бы "поверх", изменяя профиль в соответствии с ними после того, как выставлен профиль по умолчанию. Дополнительное преимущество такого способа – в том, что пользователь всегда может подглядеть в "большой" файл, чтобы узнать, как оформляется та или иная настройка. Например, утилита updfstab, которая изменяет содержимое /etc/fstab при появлении или удалении съемного дискового носителя (например, лазерного диска), считывает данные из конфигурационного файла /etc/updfstab.conf. Сам этот файл состоит из единственной строки: include /etc/updfstab.conf.default, что приводит к чтению файла с настройками по умолчанию, где задан способ работы со многими съемными устройствами системы. Если администратору нужно как-то изменить поведение updfstab в отношении определенного устройства, он копирует соответствующую группу настроек из updfstab.conf.default в updfstab.conf после строчки include... и исправляет их. То, что эти группы настроек читаются дважды, не играет особой роли: чтение коротких файлов выполняется быстро.
Наконец, третий способ сделать конфигурационный файл удобочитаемым — секционирование профиля, когда все настройки разбиваются на группы, каждой группе дается собственное имя, и синтаксис конфигурационного файла проектируется так, чтобы границы групп хорошо различались при просмотре. В сущности, этот способ – предок схемы ".d", где группе соответствует отдельный файл, однако нередки ситуации, когда разбивать на файлы неудобно (например, если группы не полностью независимы, поэтому может понадобиться редактировать их сразу несколько). Конфигурационный файл утилиты дозвона wvdial, например, секционируется по адресату (провайдеру) плюс отдельная секция "по умолчанию". Сами секции отделяются друг от друга заголовками, заключенными в квадратные скобки:
root@localhost:~> cat .wvdialrc [Dialer Defaults] Modem = /dev/modem Baud = 115200 Init1 = ATZ Init2 = ATQ0 L0 M4 V1 E1 S0=0 &C1 &D2 +FCLASS=0 Auto DNS = on Modem Type = Analog Modem [Dialer hotspace] Phone = 0123456 Username = fireman Password = Fire!Fire! TOnline = true [Dialer warlock] Phone = 0246813 Username = cop-120 Password = gimmethegun Force Address=10.0.0.120
Пример 12.4. Секционированный конфигурационный файл (html, txt)
Утилита wvdial обладает высокоразвитым искусственным интеллектом: она самостоятельно догадывается, какой именно тип идентификации используется на сервере. Например, "с той стороны" может оказаться терминал Linux, которому требуется сначала ввести обыкновенное входное имя и пароль, затем надо получить командную строку, запустить на сервере сетевой демон pppd, и только после этого запустить pppd на собственной машине. Другой вариант: pppd на сервере уже запущен, а настройки "Username" и "Password" означают идентификационную информацию протокола CHAP, используемого pppd. Обо всем этом и о многом другом wvdial способна догадаться,так же как wvdialconf умел определять, какое же из устройств является модемом.
Однако на любой искусственный интеллект найдется непостижимая ему жизненная ситуация. На одном из серверов (секция "Dialer hotspace") тоже стоит программа с зачатками искусственного интеллекта, которая тоже пытается определить, каким способом хочет идентифицироваться позвонивший. Оттого эти два кудесника, созвонившись, все ждут, пока кто-нибудь не проявит себя... Помогает настройка TOnline, которая заставляет wvdial немедленно задействовать протокол ppp, на что сервер, подумавши "ах, ppp!", с облегчением запускает pppd. Остается вопрос: почему эта полезная настройка никак не отражена в документации (ее нашел в исходных текстах программы Гуревич)? Не потому ли, что пара wvdialconf-wvdial не по-Linux-овски стремится все делать за пользователя, а стало быть, пользовательская документация для разработчиков этой программы – не главное?
Идею чтения настроек по умолчанию можно развить. Оказывается, бывает удобно, когда описание настройки помещено не в руководство, а непосредственно в конфигурационный файл в виде комментариев. Тогда при изменении этой настройки пользователь сразу видит, что она собой представляет, при этом отпадает необходимость сначала находить строчку в файле, а потом искать ее же в руководстве. Такой распространенный способ оформления называется самодокументированием профиля. Например, файл /etc/man.conf, управляющий работой команды man, оформлен в самодокументированном стиле:
methody@localhost:~ $ cat /etc/man.conf . . . # NOCACHE keeps man from creating cache pages ("cat pages") # (generally one enables/disable cat page creation by # creating/deleting the directory they would live in – man # never does mkdir) # # NOCACHE # The command "man -a xyzzy" will show all man pages for xyzzy. # When CMP is defined man will try to avoid showing the same # text twice. (But compressed pages compare unequal.) # CMP /usr/bin/cmp -s . . .
Пример 12.5. Самодокументированный конфигурационный файл (html, txt)
Мефодий, может быть, и не понял бы сразу, зачем команде man использовать утилиту cmp, однако в поясняющем комментарии написано: когда нужно показать несколько руководств разом, они предварительно сравниваются, и показываются только несовпадающие.
Если пойти еще дальше, то можно создать несколько различных файлов с примерами настроек, чтобы пользователь мог взять один из них и довести до нужного ему состояния. Именно такую – демонстрационную – настройку Мефодий и включил в качестве настройки по умолчанию в свой .vimrc (в первой строке). Кстати, на самом деле профиль Vim весьма сложен, но большинство его настроек по умолчанию находятся в различных файлах дерева каталогов /usr/share/vim – эдакая "схема .d/.d", где файлы профиля, соответствующие подгруппам настроек, лежат в подкаталогах, соответствующих группам. Включение определенного настроечного файла может происходить неявно: например, строчка colorscheme desert из .vimrc приводит к чтению /usr/share/vim/colors/desert.vim.
Конфигурационные файлы могут иметь довольно замысловатый синтаксис, если соответствуют сложным структурам данных (таковы, например, настройка irc-клиента irssi) или содержать в себе дополнительные средства самодокументирования (например, файл настройки текстового www-броузера lynx не просто хорошо документирован, но и размечен теми же средствами, какие используются в самом броузере для представления HTML).
Подсистема идентификации
Подсистемой учетных записей пользуется подсистема идентификации, которая в Linux имеет модульную структуру и называется PAM (Pluggable Authentication Modules, т. е. "Подключаемые модули идентификации"). Идея PAM – в том, чтобы унифицировать и, вместе с тем, сделать более гибкими любые процедуры идентификации в системе – начиная от команды login и заканчивая доступом к файлам по протоколу, скажем, FTP. Для этого недостаточно просто написать "библиотеку идентификации" и заставить все программы ее использовать. В зависимости от того, для чего производится идентификация, условия, при которых она будет успешной, могут быть более или менее строгими, а если она прошла успешно, бывает нужно выполнить действия, связанные не с определением
пользователя, а с настройкой системы.
В большинстве дистрибутивов PAM обучен схеме ".d", и настройки каждой службы, которая использует идентификацию, лежат в отдельном файле:
Пример 12.8. Подключаемые модули идентификации (PAM) (html, txt)
В PAM определено четыре случая, требующие идентификации: auth – собственно идентификация, определение, тот ли пользователь, за кого он себя выдает, account – определение, все ли хорошо с учетной записью пользователя, password – изменение пароля в учетной записи, и session – дополнительные действия непосредственно перед или непосредственно после того, как пользователь получит доступ к затребованной услуге. Эти значения принимает первое поле любого файла настройки из pam.d, а в третьем поле записывается модуль, который проверяет какой-нибудь из аспектов идентификации. Второе поле определяет, как успех или неуспех проверки одного модуля влияет на общий успех или неуспех идентификации данного типа (например, required означает, что в случае неуспеха модуля проверка пройдена не будет). Четвертое и последующие поля отведены под параметры модуля:
Пример 12.9. Настройка PAM для login (html, txt)
Такие настройки login обнаружил Мефодий на своем компьютере. Во всех четырех случаях используется включаемый файл system-auth (к нему обращаются и другие службы), с некоторыми дополнениями. Так, во время идентификации pam_nologin.so дополнительно проверяет, не запрещено ли пользователям регистрироваться вообще (как это бывает за несколько минут до перезагрузки системы), а перед входом в систему и после выхода из нее pam_console.so выполняет описанную в лекции 6 "передачу прав на владение устройствами" (и, соответственно, лишение пользователя этих прав).
Каталог /etc/pam.d – замечательный пример того, как профиль определяет поведение системы. В частности, четыре первых строки из system-auth показывают, что в этом дистрибутиве используется не просто "теневой" файл паролей, а схема TCB, описанная в лекции 6. (Как уже известно Мефодию, в этой схеме вместо общего для всех /etc/shadow задействованы файлы вида /etc/tcb/входное_имя/shadow, причем права доступа к ним устроены таким образом, чтобы при выполнении команды passwd можно было обойтись без подмены пользовательского идентификатора на суперпользовательский).
[root@localhost root]# cat /etc/pam.d/login auth include system-auth auth required pam_nologin.so account include system-auth password include system-auth session include system-auth session optional pam_console.so [root@localhost root]# cat /etc/pam.d/system-auth auth required pam_tcb.so shadow count=8 nullok account required pam_tcb.so shadow password required pam_tcb.so use_authtok shadow count=8 write_to=tcb session required pam_tcb.so
Пример 12.9. Настройка PAM для login
Такие настройки login обнаружил Мефодий на своем компьютере. Во всех четырех случаях используется включаемый файл system-auth (к нему обращаются и другие службы), с некоторыми дополнениями. Так, во время идентификации pam_nologin.so дополнительно проверяет, не запрещено ли пользователям регистрироваться вообще (как это бывает за несколько минут до перезагрузки системы), а перед входом в систему и после выхода из нее pam_console.so выполняет описанную в лекции 6 "передачу прав на владение устройствами" (и, соответственно, лишение пользователя этих прав).
Каталог /etc/pam.d – замечательный пример того, как профиль определяет поведение системы. В частности, четыре первых строки из system-auth показывают, что в этом дистрибутиве используется не просто "теневой" файл паролей, а схема TCB, описанная в лекции 6. (Как уже известно Мефодию, в этой схеме вместо общего для всех /etc/shadow задействованы файлы вида /etc/tcb/входное_имя/shadow, причем права доступа к ним устроены таким образом, чтобы при выполнении команды passwd можно было обойтись без подмены пользовательского идентификатора на суперпользовательский).
Подсистема системных журналов
Проста и остроумна в Linux подсистема ведения системных журналов – демон syslogd, управляемый конфигурационным файлом /etc/syslog.conf и ".d"-каталогом /etc/syslog.d. Если какой-нибудь демон или служба желают сообщить системе о том, что наступило событие, которое стоит запомнить, у нее есть два пути. Во-первых, можно просто добавлять очередную запись в файл, который сам этот демон и открыл; этот файл будет журналом его сообщений. Во-вторых, можно воспользоваться системным вызовом syslog(), который переадресует текстовое сообщение специальному демону – syslogd – а уж тот разберется, что с этим сообщением делать: записать в файл, вывести на 12-ю консоль или забыть о нем. Второй путь (централизованная журнализация) предпочтительнее почти всегда; исключение составляет случай, когда сообщения по какой-то причине не могут быть текстовыми или этих сообщений предполагается посылать так много, что syslogd просто не справится.
Все события, о которых сообщается syslogd, подразделяются горизонтально – по типу службы (facility), с которой это событие произошло, и вертикально – по степени его важности (priority). Типов событий насчитывается около двадцати (среди них auth, daemon, kern, mail и т. п., а также восемь неименованных, от local0 до local7). Степеней важности всего восемь, по возрастанию: debug, info, notice, warning, err, crit, alert и emerg. Таким образом, каждое событие определяется парой значений, например, mail.err означает для syslogd событие, связанное с почтой, притом важности, не меньшей err. Из таких пар (с возможной заменой типа или важности на "*", что означает "любые", или none, что означает "никакие") составляется конфигурационный файл /etc/syslog.conf:
[root@localhost root]# cat /etc/syslog.conf *.notice;mail.err;authpriv.err /var/log/messages authpriv.*;auth.* /var/log/security.log *.emerg * *.* /dev/tty12 mail.info /var/log/maillog
Пример 12.10. Настройка системных журналов (html, txt)
В первом поле строки указываются профили сообщений, разделенные символом ";", а во втором – хранилище сообщений (файл, терминал, есть способы отдавать их на обработку программе и пересылать по сети). В примере в файл /var/log/messages попадают все сообщения важности не меньшей, чем notice, за исключением сообщений типа mail и authpriv, которые попадают туда, только если имеют важность не ниже err. Сообщения типа authpriv и auth любой важности попадают в файл /var/log/security.log, а типа mail и важности не ниже info – в файл /var/log/maillog. Сообщения типа emerg (наивысшей важности) выводятся на все терминалы системы, и, наконец, все сообщения выводятся на 12-ю виртуальную консоль.
Во многих системах используется основательно доработанный syslogd, позволяющий фильтровать сообщения не только по типу/важности, но и, например, по отправителю, задавать точные (а не "не меньшие") значения priority и т. п., однако такие доработки нужны для того, чтобы либо вести практически нефильтрованную журнализацию (получаются системные журналы совершенно нечитаемого объема), либо отводить поток сообщений определенной службы в отдельный журнал, опять-таки, не для чтения, а для последующей обработки.
Стоит заметить, что каталог /etc/syslog.d в новых версиях syslogd предназначен для хранения не профильных конфигурационных файлов в стиле ".d", а сокетов, из которых демон может получать сообщения так же, как из сети или в результате системного вызова syslog().
Подсистема учетных записей
Несколько конфигурационных файлов и способы работы с ними заслуживают отдельного рассмотрения. В первую очередь Мефодий заинтересовался системой учетных записей, о которой упоминалось сразу в нескольких предыдущих лекциях. Итак, существует два файла, доступных для чтения всем пользователям: /etc/passwd, хранящий учетные данные пользователей, и /etc/group, определяющий членство пользователей в группах (во всех, кроме группы по умолчанию):
methody@localhost:~ $ cat /etc/passwd root:x:0:0:System Administrator:/root:/bin/bash bin:x:1:1:bin:/:/dev/null daemon:x:2:2:daemon:/:/dev/null adm:x:3:4:adm:/var/adm:/dev/null lp:x:4:7:lp:/var/spool/lpd:/dev/null . . . nobody:x:99:99:Nobody:/var/nobody:/dev/null shogun:x:400:400:Лев Гуревич:/home/shogun:/bin/zsh methody:x:503:503:Мефодий Кашин:/home/methody:/bin/bash methody@localhost:~ $ cat /etc/group root:x:0:root bin:x:1:root,bin,daemon daemon:x:2:root,bin,daemon sys:x:3:root,bin,adm adm:x:4:root,adm,daemon,shogun wheel:x:10:root,shogun . . . proc:x:19:root,shogun shogun:x:400: methody:x:503:
Пример 12.6. Файлы /etc/passwd и /etc/group (html, txt)
Оба файла состоят из строк, поля которых разделяются двоеточиями. В файле passwd – семь полей. Первое из них определяет входное имя пользователя – то самое, что вводится в ответ на "login: ". Второе поле в ранних версиях UNIX использовалось для хранения ключа пароля. В Linux пользовательские пароли не хранятся нигде – ни в явном виде, ни в зашифрованном. Вместо этого хранится ключ (hash) пароля – комбинация символов, однозначно соответствующая паролю, из которой, однако, сам пароль получить нельзя. Иными словами, существует алгоритм превращения пароля в ключ, а алгоритма превращения ключа в пароль нет. Когда пользователь регистрируется в системе, из введенного им пароля изготавливается еще один ключ. Если он совпадает с тем, что хранится в учетной записи, значит, пароль правильный.
Авторы UNIX предполагали, что, раз пароль из ключа получить нельзя, ключ можно выставлять на всеобщее обозрение, однако выяснилось, что, узнав ключ, пароль можно попросту подобрать на очень мощной машине или в предположении, что пароль – это английское слово, год рождения, имя любимой кошки и т. п. Если подбор пароля сопровождается неудачными попытками входа в систему, это отражается в системных журналах и может быть легко замечено. А завладев ключом, злоумышленник сможет заняться подбором пароля втихомолку на каком-нибудь суперкомпьютере. В конце концов, ключ не нужен никому, кроме подсистемы идентификации, поэтому его вместе с другими полями учетной записи, о которых всем знать не обязательно, из /etc/passwd перенесли в "теневой" файл учетных записей – /etc/shadow. На месте ключа в Linux должна быть буква "x"; если там стоит что-то другое, идентификация пользователя не сработает, и он не сможет войти в систему.
Третье и четвертое поля passwd – идентификатор пользователя и идентификатор группы по умолчанию. Как уже говорилось в лекции 6, именно идентификатор пользователя, а не его входное имя, однозначно
определяет пользователя в системе и его права. Можно создать несколько учетных записей с одинаковыми UID, которые различаются другими полями. Тогда при регистрации в системе под именами из этих записей пользователи могут получать разные домашние каталоги и командные оболочки, разное членство в группах, но иметь один и тот же UID. Пятое поле отводится под "полное имя" пользователя; это единственное поле passwd, содержимое которого ни на что не влияет. Наконец, шестое и седьмое поля содержат домашний каталог и стартовый командный интерпретатор пользователя. Если седьмое поле пусто, подразумевается /bin/sh, а если его содержимое не встречается в файле /etc/shells, содержащем допустимые командные интерпретаторы, неизбежны трудности при идентификации пользователя.
Строки файла /etc/group состоят из четырех полей, причем второе – ключ группового пароля – обычно не используется. Первое поле – это имя группы, третье – это идентификатор группы, а четвертое – это список входных имен пользователей, которые в эту группу входят (более точно – для которых эта группа является дополнительной, так как группа по умолчанию указывается в /etc/passwd, хотя никто не мешает продублировать группу по умолчанию и в /etc/group). Таким образом, определение членства пользователя в группах зависит не от его UID, а от входного имени.
Упомянутый выше файл /etc/shadow, доступ к которому имеет только суперпользователь, также состоит из полей, разделяемых двоеточиями. Помимо входного имени и ключа пароля там указываются различные временные характеристики учетной записи: нижняя и верхняя граница времени жизни пароля, самой учетной записи, дата последнего изменения и т. п. Ключ пароля (второе поле) указывается в одном из поддерживаемых форматов, а если формат не опознан, вся учетная запись считается недействительной. Поэтому один из способов запретить регистрацию пользователя в системе – добавить один символ (например, "!") прямо в поле ключа, отчего все поле становится синтаксически неправильным. Вновь разрешить пользователю входить в систему можно, удалив из поля лишний символ. Именно так работает (с ключами "-L", lock, и "-U", unlock) утилита usermod, изменяющая учетную запись. С помощью этой утилиты можно отредактировать и все остальные поля как passwd, так и shadow.
Добавить и удалить пользователя или группу можно с помощью утилит useradd, userdel, groupadd и groupdel соответственно. Не стоит пользоваться текстовым редактором, так как он не гарантирует атомарности операции добавления/удаления, хотя бы потому, что изменению подлежат сразу два файла – passwd и shadow. Даже если необходимо отредактировать /etc/passwd или /etc/group (например, для добавления пользователя в группу или удаления его оттуда), стоит запускать не просто редактор, а vipw или vigr (именно их поведение, позволяющее соблюсти атомарность, копирует утилита visudo, описанная ранее):
Пример 12.7. Добавление и удаление пользователя (html, txt)
Здесь был добавлен пользователь incognito, группа по умолчанию – users, член групп proc и cdrom, полное имя – "Incognito". Стоит заметить, что пароль для этой учетной записи установлен не был (чтобы создать пароль, стоило запустить команду passwd incognito), и, даже если бы пользователя тут же не удалили (userdel -r удаляет также и домашний каталог, и почтовый ящик), зарегистрироваться в системе под именем incognito было бы все равно невозможно.
wvdialrc Scanning your serial ports
| [root@localhost root]# wvdialconf Usage: wvdialconf (create/update a wvdial.conf file automatically) [root@localhost root]# wvdialconf . wvdialrc Scanning your serial ports for a modem. Port Scan<*1>: Scanning ttyS4 first, /dev/modem is a link to it. . . . ttyS4<*1>: Modem Identifier: ATI -- Xircom CardBus 10/100+Modem 56 (Revision 2.40) . . . ttyS4<*1>: ATQ0 V1 E1 S0=0 &C1 &D2 +FCLASS=0 -- OK ircomm0<*1>: ATQ0 V1 E1 -- failed at 9600 and 19200 baud. . . . ircomm9<*1>: ATQ0 V1 E1 -- failed at 9600 and 19200 baud. Port Scan<*1>: LT0 . . . ttyS0<*1>: ATQ0 V1 E1 -- and failed too at 115200, giving up. . . . ttyS1<*1>: ATQ0 V1 E1 -- and failed too at 115200, giving up. Port Scan<*1>: S2 S3 S5 S6 S7 S8 S10 . . . Port Scan<*1>: USB11 USB12 USB13 USB14 USB15 Found a modem on /dev/ttyS4, using link /dev/modem in config. Modem configuration written to .wvdialrc. ttyS4: Speed 115200; init "ATQ0 V1 E1 S0=0 &C1 &D2 +FCLASS=0" |
| Пример 12.1. Кудесник wvdialconf |
| Закрыть окно |
| methody@localhost:~ $ cat .vimrc so $VIMRUNTIME/vimrc_example.vim " Some mappings map :wall!^M map! ^O:wall!^M " Tune up set shiftwidth=2 tabstop=8 history=200 viminfo=' 50 set showmode showmatch showcmd ruler modeline set autoindent ignorecase smartcase set nohlsearch noincsearch set dir=/var/tmp set wildmode=list:longest,full set wildmenu " Colouring syntax on colorscheme desert |
| Пример 12.2. Настройки редактора vim |
| Закрыть окно |
| methody@localhost:~ $ cat .i18n LANG=ru_RU.KOI8-R LANGUAGE=ru_RU.KOI8-R SYSFONTACM=koi8-r SYSFONT=UniCyr_8x16 DICTIONARY=russian MPAGE="-CKOI8-R" export DICTIONARY MPAGE |
| Пример 12.3. Файл настройки языковых особенностей |
| Закрыть окно |
| root@localhost:~> cat .wvdialrc [Dialer Defaults] Modem = /dev/modem Baud = 115200 Init1 = ATZ Init2 = ATQ0 L0 M4 V1 E1 S0=0 &C1 &D2 +FCLASS=0 Auto DNS = on Modem Type = Analog Modem [Dialer hotspace] Phone = 0123456 Username = fireman Password = Fire!Fire! TOnline = true [Dialer warlock] Phone = 0246813 Username = cop-120 Password = gimmethegun Force Address=10.0.0.120 |
| Пример 12.4. Секционированный конфигурационный файл |
| Закрыть окно |
| methody@localhost:~ $ cat /etc/man.conf . . . # NOCACHE keeps man from creating cache pages ("cat pages") # (generally one enables/disable cat page creation by # creating/deleting the directory they would live in – man # never does mkdir) # # NOCACHE # The command "man -a xyzzy" will show all man pages for xyzzy. # When CMP is defined man will try to avoid showing the same # text twice. (But compressed pages compare unequal.) # CMP /usr/bin/cmp -s . . . |
| Пример 12.5. Самодокументированный конфигурационный файл |
| Закрыть окно |
| methody@localhost:~ $ cat /etc/passwd root:x:0:0:System Administrator:/root:/bin/bash bin:x:1:1:bin:/:/dev/null daemon:x:2:2:daemon:/:/dev/null adm:x:3:4:adm:/var/adm:/dev/null lp:x:4:7:lp:/var/spool/lpd:/dev/null . . . nobody:x:99:99:Nobody:/var/nobody:/dev/null shogun:x:400:400:Лев Гуревич:/home/shogun:/bin/zsh methody:x:503:503:Мефодий Кашин:/home/methody:/bin/bash methody@localhost:~ $ cat /etc/group root:x:0:root bin:x:1:root,bin,daemon daemon:x:2:root,bin,daemon sys:x:3:root,bin,adm adm:x:4:root,adm,daemon,shogun wheel:x:10:root,shogun . . . proc:x:19:root,shogun shogun:x:400: methody:x:503: |
| Пример 12. 6. Файлы /etc/passwd и /etc/group |
| Закрыть окно |
| [root@localhost root]# useradd -g users -G proc,cdrom -c "Incognito" incognito [root@localhost root]# id incognito uid=504(incognito) gid=100(users) groups=100(users),19(proc),22(cdrom) [root@localhost root]# userdel -r incognito [root@localhost root]# id incognito id: incognito: No such user |
| Пример 12.7. Добавление и удаление пользователя |
| Закрыть окно |
| [root@localhost root]# ls /etc/pam.d chpasswd groupdel other system-auth userdel chpasswd-newusers groupmod passwd system-auth- use_first_pass usermod crond login sshd user-group-mod groupadd newusers su useradd |
| Пример 12.8. Подключаемые модули идентификации (PAM) |
| Закрыть окно |
| [root@localhost root]# cat /etc/pam.d/login auth include system-auth auth required pam_nologin.so account include system-auth password include system-auth session include system-auth session optional pam_console.so [root@localhost root]# cat /etc/pam.d/system-auth auth required pam_tcb.so shadow count= 8 nullok account required pam_tcb.so shadow password required pam_tcb.so use_authtok shadow count=8 write_to=tcb session required pam_tcb.so |
| Пример 12.9. Настройка PAM для login |
| Закрыть окно |
| [root@localhost root]# cat /etc/syslog.conf *.notice;mail.err;authpriv.err /var/log/messages authpriv.*;auth.* /var/log/security.log *.emerg * *.* /dev/tty12 mail.info /var/log/maillog |
| Пример 12.10. Настройка системных журналов |
| Закрыть окно |
| [root@localhost root]# cat /etc/crontab #minute (0-59), #| hour (0-23), #| | day of the month (1-31), #| | | month of the year (1-12), #| | | | day of the week (0-6 with 0=Sunday). #| | | | | user #| | | | | | commands 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly |
| Пример 12.11. Настройка cron |
| Закрыть окно |
| [root@localhost root]# ls /etc/cron. daily 000anacron logrotate makewhatis osec stmpclean updatedb |
| Пример 12.12. Сценарии, запускаемые ежедневно |
| Закрыть окно |
| [root@localhost root]# ls -l /var/log/syslog/messages* -rw-r----- 1 root adm 292654 Dec 15 14:01 /var/log/syslog/messages -rw-r----- 1 root adm 34452 Dec 13 01:09 /var/log/syslog/messages.1.bz2 -rw-r----- 1 root adm 35892 Dec 6 09:38 /var/log/syslog/messages.2.bz2 -rw-r----- 1 root adm 60806 Nov 28 10:59 /var/log/syslog/messages.3.bz2 -rw-r----- 1 root adm 61063 Nov 21 10:47 /var/log/syslog/messages.4.bz2 -rw-r----- 1 root adm 60079 Nov 14 21:18 /var/log/syslog/messages.5.bz2 |
| Пример 12.13. Системный журнал messages |
| Закрыть окно |
| methody@localhost:~ $ ls bin cat.info cat. stderr Documents examples grep.info textfile tmp methody@localhost:~ $ ls -AF .alias .bashrc .emacs .inputrc~ textfile .Xauthority .bash_history bin/ examples/ .lpoptions tmp/ .xsession.d/ .bash_logout cat.info grep.info .pinerc .viminfo .bash_profile cat.stderr .i18n .pyhistory .vimrc .bash_profile~ Documents/ .inputrc .pythonstartup .vimrc~ methody@localhost:~ $ rm .*~ |
| Пример 12.14. Конфигурационные файлы в домашнем каталоге |
| Закрыть окно |
| methody@localhost:~ $ cat . pythonstartup import atexit, os, readline, rlcompleter historyPath = os.path.expanduser("~/.pyhistory") def save_history(historyPath=historyPath): import readline readline.write_history_file(historyPath) if os.path.exists(historyPath): readline.read_history_file(historyPath) atexit.register(save_history) del os, atexit, readline, rlcompleter, save_history, historyPath |
| Пример 12.15. Стартовый файл интерпретатора Python |
| Закрыть окно |
Проектирование свойств системы
Операционная система, позволяющая задействовать все возможности компьютера, резко отличается от специализированного программного обеспечения огромным числом так называемых "вариантов использования" (use cases) и обширнейшими возможностями тонкой настройки для решения задач конкретного пользователя наилучшим способом. Достаточно сравнить какую-нибудь игровую приставку (например, PlayStation2) под управлением собственной операционной системы и ее же под управлением Linux. Вычислительная и мультимедийная мощность такого компьютера весьма высока (известно, что именно компьютерные игры определяют сейчас ресурсопотребление персонального компьютера). Однако способы управления одной и другой системами настолько различны, что неподготовленный человек просто теряется при виде возможностей Linux: на какие кнопки нажимать? А кнопок-то и нет...
Можно попытаться описать операционную систему как большой и сложный универсальный инструмент для решения любых задач. Предполагается, что пользователь, прочтя документацию, в которой описывается, как работает система и как применять ее в различных ситуациях, сможет решать и свои задачи. Правда, для этого ему придется прочесть большую часть документации по системе (в том числе и технической) и перепрограммировать некоторые части системы сообразно своим нуждам. На такой подвиг способны немногие, времени это займет немало, да и вероятность ошибки (которая тем выше, чем сложнее средства управления системой) при таком подходе недопустимо велика. Сами утилиты или службы Linux, каждую из которых можно "окинуть взором" и понять, что она умеет и чего в ней не хватает, разрабатываются именно теми из пользователей, у которых хватает времени, знаний и навыков на такое полное освоение (см. лекции 17 и 18). Вывод: пользователь – не разработчик, ему все-таки важнее быстро и качественно решить задачу, чем долго совершенствовать инструмент решения.
Можно пойти обратным путем: попытаться предусмотреть все основные
способы использования операционной системы на всех основных пользовательских задачах, и на каждый такой способ создать (запрограммировать) отдельную часть, управляемую "кнопкой" или утилитой. Эту часть обычно называют "решением" (solution), и в документации пишут, что должно быть "на входе" системы, и что получается "на выходе" после применения решения. Если пользователь не умеет сам поставить задачу, или делает это в неопределенной форме ("хочу, чтобы был текст", "хочу, чтобы играла музыка"), этот способ работает превосходно: та же игровая приставка – это отличное решение крайне неопределенной задачи "хочу без толку потратить время". Однако стоит пользователю захотеть чего-то конкретного, начинаются трудности. Трудности могут быстро стать непреодолимыми, как только для этого "конкретного" не окажется готового решения: внутренняя структура систем, ориентированных на "решения", столь сложна и столь плохо документирована, что сделать что-либо вручную, скорее всего, не удастся. Вывод: пользователь, понимающий суть собственных задач, – не "клиент", он должен иметь возможность быстро и качественно решать задачи самостоятельно, а не выбирать из готовых "решений" то, которое нанесет меньше вреда.
Что же нужно идеальному – достаточно подготовленному, чтобы действовать самостоятельно, и достаточно занятому, чтобы не переделывать систему – пользователю? По-видимому, механизм, с помощью которого можно сформулировать и придать операционной системе все требуемые свойства, имея возможность описывать решение задачи, по крайней мере, на том же уровне конкретности, на котором было поставлено ее условие. Большая часть других, не нужных для решения собственных задач пользователя, свойств должны быть "стандартными" и не требовать его вмешательства.
Профиль системы
Так возникает идея разделить систему на два подмножества: профиль и реализацию. Все, что не потребует вмешательства пользователя, необходимо запрограммировать и применять в готовом виде в качестве составных частей реализации. В Linux этому соответствуют программы и подпрограммы: ядро, модули, демоны, утилиты; используемые ими библиотеки и прочие разделяемые файлы и т. п. Реализация – это монолитная, неизменяемая часть системы, устроенная по типу "решений" основных задач, только задачи эти, как правило, не совпадают с задачами пользователей, а только помогают решать их, то есть служат как бы строительным материалом, деталями и инструментами сборки "больших" решений.
Все, чего может коснуться рука человека, из реализации переносится в профиль системы. Профиль задает поведение реализации на данных пользователя и должен быть устроен так, чтобы пользователь мог его беспрепятственно изменять, если понадобится. С одной стороны, это может быть вариант "высокоуровневого программирования", когда пользователь описывает алгоритм решения и структуру используемых данных на некотором высокоуровневом языке (специализированном или общем, например, на shell). С другой стороны, задание свойств может превращаться в указание модификаторов поведения, когда пользователь просто перечисляет необходимые параметры работы программы, которые изменяют ее заранее известную, но достаточно общую функциональность.
Таким образом система полностью описывается в виде набора необходимых компонентов реализации, активизированных (запущенных) с определенными профилями, вкупе с текущим состоянием каждого компонента. Поскольку компонент реализации не может изменяться, а его текущее состояние, наоборот, меняется постоянно и не управляется пользователем, можно считать, что систему задает ее профиль. Это означает, что для того, чтобы продублировать работу системы на другом компьютере, достаточно установить там стандартную реализацию и перенести профиль (обычно занимающий несравненно меньше места) и пользовательское наполнение. Наполнение (файлы пользователей, содержимое www-страниц и т. п.) может занимать много места, но оно входит в понятие "задача пользователя", поэтому забывать о нем нельзя.
Профиль. Изменяемая часть системы, определяющая ее поведение во время работы.
Как проще всего создать профиль если не всей системы, то хотя бы ее компонента (программы)? Один из вариантов такой: снабдить программу функцией "сохранить настройки", тогда можно будет эту программу запустить, любым способом добиться ее работоспособности, а после зафиксировать достигнутое состояние с помощью этой функции. При этом поначалу совершенно неважно, как выглядят эти настройки: программа-то заработала, значит, цель достигнута (проницательный Мефодий немедленно заметил, что название функции "сохранить настройки" как-то подозрительно похоже на название кнопки).
Зачастую для того, чтобы собрать более или менее отвечающий требованиям пользователя профиль, задействуется больше ресурсов, чем для работы самой программы. Утилита автоматической настройки выглядит эдаким шаманом, или кудесником, который, задав всего несколько вопросов человеку, непонятным образом приводит систему в работоспособное состояние. Такая подсистема и называется "wizard", причем в русском переводе ее отчего-то стесняются называть "шаманом", а величают уважительно "мастером".
Вот пример поведения обычного шамана-настройщика (пакет wvdial, заведующий модемным подключением к Internet):
Пример 12.1. Кудесник wvdialconf (html, txt)
Ни о каких наводящих вопросах даже речи не зашло! Программа проверила более полусотни устройств, не модемы ли они, но нашла всего одно – /dev/ttyS4. Его настройки определились автоматически (и хорошо, потому что Мефодий не знает, что такое "ATQ0 V1 E1 S0=0 &C1 &D2 +FCLASS=0"). Профиль (а wvdialrc создает именно профиль) лежит теперь в файле .wvdialrc, так что программа wvdial начнет работать с модемом, нуждаясь только в пользовательских настройках (входное имя, пароль и т. п.).
Яркий пример того, как элементы реализации связываются профилем в единую подсистему для решения определенной задачи – командная строка и сценарии командного интерпретатора. Здесь утилиты играют роль элементов реализации, их параметры – роль "настроечной" части профиля, а способ их объединения в сценарий – "программируемой" части профиля. Скажем, команда find /etc -type f 2> /dev/null | xargs -n1 file | cut -d: -f2 | sort | uniq -c задействует шесть утилит системы: командную оболочку, find, xargs, cut, sort и uniq, причем четыре из них запускаются с измененным профилем1). Командная оболочка дополнительно программируется для создания конвейера между командами.
"Прокручивание" системных журналов
Еще изучая работу syslog, Мефодий не расставался с мыслью, что файл, в котором записывается системный журнал, постоянно растет. Это значит, что каков бы ни был размер файловой системы /var, она в конце концов заполнится журналами под завязку – если как-то их не укорачивать. К сожалению, в Linux укоротить файл от начала, отрезав самые старые записи, нельзя, как нельзя и добавлять новые записи в начало файла. Эти операции легко реализовать с помощью копирования нужной области в новый файл и последующего переименования, но, во-первых, соблюсти атомарность таких составных операций нелегко, а во-вторых, они требуют вдвое больше места в файловой системе на время работы (и, стало быть, каких-то аварийных процедур на случай нехватки места).
Поэтому в Linux принят другой, существенно менее ресурсоемкий алгоритм, позволяющий избежать переполнения /var: так называемое "прокручивание" системных журналов. Суть алгоритма в следующем: когда настает пора укоротить журнал (например, раз в неделю или если файл журнала достиг определенного размера), этот файл переименовывают, и открывают новый пустой файл с тем же именем. Если хранить несколько
(скажем, семь) переименованных старых файлов, с ними уже можно производить операцию "отбрасывания старого": самый старый – седьмой – файл удаляется, шестой переименовывается в седьмой, пятый – в шестой, и т. д. до первого (моложе которого только текущий журнал), который переименовывается во второй. Только тогда можно переименовать текущий журнал в "первый старый" и открыть новый. Получается очередь устаревающих файлов, пополняемая с одной стороны и усекаемая с другой.
Как правило, имя "первого старого" журнала получается путем добавления к имени журнала суффикса ".1", второго – ".2" и т. д.:
Пример 12.13. Системный журнал messages (html, txt)
Прокручиванием системных журналов занимается утилита logrotate, которая тоже управляется и конфигурационным файлом /etc/logrotate.conf, и ".d"-каталогом /etc/logrotate.d/. Согласно настройкам, старые файлы можно сжимать упаковщиками bzip2 (как в примере) или gzip, можно задавать им определенные права доступа, можно посылать сигнал некоторой службе (чтобы она заметила подмену журнала, если она сама, а не syslogd занимается его пополнением) и т. п.
Выполнение действий по расписанию
Другой пример типичной для Linux службы, управляемой конфигурационным файлом, – демон cron1), регулярно выполняющий в заданное время заданные действия. Время от времени в системе необходимо обновлять разнообразные файлы, например, базы данных антивирусов (вирусов в Linux нет, а антивирусы есть!), базу данных whatis или список всех доступных на чтение файлов системы, locatedb (поискать по этому списку можно командой locate); нужно собирать статистику по работе системы, анализировать цельность системы (этим занимаются службы OSec, TripWire или AIDE) и производить множество других регулярных действий. Всем этим и занимается демон cron.
Конфигурационный файл демона cron называется /etc/crontab.
[root@localhost root]# cat /etc/crontab #minute (0-59), #| hour (0-23), #| | day of the month (1-31), #| | | month of the year (1-12), #| | | | day of the week (0-6 with 0=Sunday). #| | | | | user #| | | | | | commands 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly
Пример 12.11. Настройка cron (html, txt)
Первые пять полей этого файла определяют время запуска команды: минуту, час, число месяца, месяц и день недели. Символ "*" означает, что соответствующая часть даты не учитывается. Шестое поле – имя пользователя, от лица которого запускается команда, указанная в остальных полях строки. Так, в примере команда run-parts /etc/cron.weekly будет запускаться в 4 часа 22 минуты каждое воскресенье (нулевой день) любого числа любого месяца. Как видно из примера, обычно /etc/crontab невелик: чаще всего он состоит из почасового, поденного, понедельного и помесячного запуска специального сценария (в примере – run-parts). Этот сценарий реализует упрощенную схему ".d", он попросту запускает отсортированные в лексикографическом порядке2) сценарии из соответствующего каталога (например, из /etc/cron.daily):
[root@localhost root]# ls /etc/cron.daily 000anacron logrotate makewhatis osec stmpclean updatedb
Пример 12.12. Сценарии, запускаемые ежедневно (html, txt)
Вот что происходит каждый день на машине Мефодия: запуск anacron и "прокручивание" системных журналов (об этом речь пойдет далее), обновление базы whatis, проверка цельности системы с помощью osec, прореживание старых и неиспользуемых файлов в /tmp (утилита stmpclean) и, наконец, обновление базы updatedb.
Пользователям системы можно разрешить иметь собственные расписания, также обрабатываемые демоном cron. Эти расписания имеют тот же синтаксис, что и crontab, только шестое поле ("user") в них отсутствует. Редактировать пользовательские таблицы рекомендуется с помощью команды crontab -e (чтобы не подсунуть демону синтаксически неверный файл). Сами таблицы могут храниться, в зависимости от версии и настроек cron, в /var/spool/cron/crontabs, /var/spool/cron, /var/cron/tabs или еще где-нибудь.
Служба anacron появилась в Linux-системах в то время, когда их начали активно использовать на персональных рабочих станциях. Такие станции, в отличие от серверов, не обязаны работать круглосуточно. Скорее всего, на ночь, на праздники и на время отпуска их выключают. Это значит, что все настройки cron надо менять в соответствии с графиком включений/выключений (иначе cron.daily никогда не выполнится в четыре часа ночи) – или запускать отдельную службу, которая будет выполнять некоторые задачи не по расписанию, а потому что их давно уже пора
запустить3). Дополнительно anacron рассчитывает запуск задач так, чтобы не перегрузить компьютер работой, если их накопилось слишком много. Конфигурационный файл anacron называется /etc/anacrontab.
Архив файлов
На первый взгляд, программа состоит из одного – исполняемого файла: запускаем файл, получаем работающую программу. Однако во время работы даже самая простая программа использует другие файлы, содержащие различные ресурсы: библиотеки, конфигурационные файлы, файлы-дырки и даже запускает другие программы. Чтобы программа действительно заработала, необходимо помимо главного исполняемого файла обеспечить наличие в системе всех нужных файлов с ресурсами.
Понятно, что при установке или удалении программы следует позаботиться и обо всех используемых ею файлах (которых может быть даже очень много). Это – первая задача пакетирования: все файлы, используемые программой, объединяются в один файл – архив. Это позволяет не копировать при установке программы все файлы по отдельности, а потом не удалять их таким же способом, а работать со всеми данными программы как с единым целым – устанавливать и удалять один пакет.
Файловый архив. Дерево каталогов, представленное в виде единого файла, состоящего из содержимого всех файлов в этом дереве и информации об имени и атрибутах каждого файла.
Нет жесткого требования, чтобы один пакет содержал только одну программу. В пакет естественно объединять такие ресурсы, с которыми удобно работать как с единым целым. Это может быть отдельная программа или набор утилит (например, coreutils, основные утилиты, унаследованные Linux от UNIX) или модуль с дополнительными возможностями программы, или общие для нескольких программ ресурсы. В процессе развития и/или устаревания программного обеспечения выделение некоторых задач в отдельный пакет может приобретать или терять смысл, поэтому способ объединения ресурсов в пакеты – это не что-то раз и навсегда выбранное: пакеты могут разделяться и сливаться.
Самый простой и традиционный для Linux способ объединить несколько файлов в один – использовать утилиту tar1) Мефодий, написав несколько программ и сценариев, решил собрать их в одном файловом архиве, чтобы их удобнее было переносить на все системы, в которых ему случается работать. Для этого Мефодий создал архив со всем содержимым своего подкаталога bin/:
methody@localhost:~ $ tar -cf methody.progs.tar bin/ methody@localhost:~ $ tar -tf methody.progs.tar bin/ bin/loop bin/script bin/to.sort bin/two
Пример 13.1. Создание файлового архива при помощи tar (html, txt)
Первый параметр tar состоит из двух частей: операция, которую следует произвести над архивом, в данном случае "c" (create, создать), и ключ "f", который указывает, что архив следует создать в файле, имя файла архива – следующий параметр. Имя архива может быть любым, но Гуревич посоветовал снабдить его расширением ".tar", чтобы потом не путаться. После имени архива следуют имена файлов и каталогов, которые следует запаковать.2)
Чтобы проверить, какие файлы попали в архив, Мефодий просмотрел содержимое получившегося архива командой "tar -tf имя_архива" ("t" – просмотреть, "f" использовать файл, указанный следующим параметром). Тут Мефодий обратил внимание на два обстоятельства. Во-первых, в архиве имена файлов сохранились вместе с путем. Во-вторых,все пути, сохраненные в архиве – относительные.
При распаковке архива tar файлы извлекаются вместе с путем, недостающие подкаталоги создаются по мере необходимости. Все пути tar считает относительными, начиная от своего рабочего каталога. Если теперь Мефодий распакует свой архив (командой "tar xf имя_архива"),то в рабочем каталоге будет создан подкаталог "bin/" и в него будут записаны все файлы из архива:
methody@localhost:~ $ tar -xvf methody.progs.tar bin/ bin/loop bin/script bin/to.sort bin/two
Пример 13.2. Распаковка архива (html, txt)
Ключ "v" велит tar быть "разговорчивым" (verbose), т. е. выводить больше диагностических сообщений, и благодаря этому tar при распаковке выводит имена (с путем) всех записываемых файлов. Если в рабочем каталоге уже есть файл, который tar собирается создать при распаковке, то этот файл будет попросту заменен файлом из архива. Так, когда Мефодий распаковал свой архив, подкаталог "bin/" со всем его содержимым заменился на подкаталог из архива. В данной ситуации это нестрашно, поскольку в архиве файлы такие же, но вот если бы Мефодий перед распаковкой изменил какие-то из своих файлов в "bin/", он лишился бы всех изменений.
Библиотеки
Мефодию помешала установить пакет самая типичная зависимость– на библиотеку>. Библиотеки возникают оттого, что все программы, как бы они ни отличались друг от друга, нуждаются в выполнении одних и тех же операций: вводе и выводе, получении доступа к ресурсам системы (памяти, процессорному времени, файлам), вычислениях, работе с сетью, рисовании окошек, кнопок, меню и т. п. Для выполнения таких операций используются небольшие подпрограммы – функции. Любые функции, необходимые более чем одной программе, есть смысл не включать в текст каждой программы, а собирать в отдельных библиотеках. Тогда программа сможет использовать не собственную подпрограмму, а готовую функцию из библиотеки. Поскольку библиотеки нужны нескольким программам, они обычно оформляются в виде отдельного пакета. Если библиотека не будет установлена, использующая ее программа просто не будет работать.
Библиотеки подвержены тем же изменениям с течением времени, что и все прочие программы: исправлению обнаруженных ошибок, модернизации, оптимизации и пр. Поэтому версии библиотек должны быть согласованы с версией программного обеспечения. Например, программа может отказаться работать даже при наличии библиотеки, если эта библиотека слишком старая либо слишком новая по сравнению с самой программой.
Цена удобства
Удобство, которое получает пользователь при работе с пакетами, не приходит само по себе, а достигается человеческим трудом: пакеты должен создавать человек, его работа называется "сопровождающий" ("package maintainer" или "packager"). В обязанности сопровождающего пакет входит подготовка файлового архива, необходимых для установки и удаления сценариев и прочей информации о пакете и его содержимом, и объединение их в одном файле-пакете3). Узнать, кто и когда создал пакет, получить краткую справку о программном обеспечении, которое в нем содержится, можно с помощью команды "rpm -qi имя_пакета":
Пример 13.7. Описание пакета (html, txt)
Нужно принимать во внимание, что любой пакет, содержащий программное обеспечение для Linux, не является универсальным. Если у вас есть такой пакет, это еще не означает, что его можно установить в вашей системе. Дело в том, что разные дистрибутивы Linux различаются именно тем, каким образом программное обеспечение организовано в систему (о дистрибутивах речь пойдет в лекции 18). Дистрибутивы могут различаться размещением файлов и процедурами, предусмотренными для интеграции в систему программного обеспечения, не говоря уже о том, что в разных дистрибутивах используется разный формат пакетов. Это значит, что пакет, подготовленный в расчете на один дистрибутив, может оказаться несовместимым с другим. Чтобы в вашем дистрибутиве появилась некоторая программа, кто-то должен подготовить и сделать доступным соответствующий пакет.
Пакет. Ресурсы, необходимые для установки и интеграции в систему некоторого компонента (архив файлов, до- и послеустановочные сценарии, информация о пакете и его сопровождающем), объединенные в одном файле.
Несмотря на некоторые различия, дистрибутивы Linux представляют собой варианты одной и той же системы, поэтому в конечном итоге любую программу, работающую в одном дистрибутиве, можно "приспособить" к любому другому. Только для этого нужно располагать исходными текстами соответствующей программы. До сих пор речь шла только о так называемых двоичных пакетах, в которых программы содержатся в виде уже скомпилированных двоичных (исполняемых) файлов, в таком виде программа может зависеть от некоторых свойств системы и работать не везде. Чтобы получить работающую программу в системе, нужно установить именно двоичный пакет. Пакет, впрочем, может содержать и исходные тексты программ, такие пакеты называются исходными. Доступность исходных кодов – обязательное условие распространения большей части программного обеспечения для Linux (см. лекцию 17). Если получилось так, что никто не подготовил пакет с нужной вам программой для вашего дистрибутива, можно установить исходный пакет и скомпилировать программу самостоятельно 4). При успешной компиляции из исходного пакета получается соответствующий двоичный, который уже можно установить в системе.
1)
появился намного раньше Linux и изначально служил для создания файловых архивов на магнитной ленте. Отсюда и его название – tape archiver, "архиватор для (магнитных) лент". В настоящее время tar присутствует в любой UNIX-подобной системе и позволяет работать с файловыми архивами на любых носителях.
2)
С каждым указанным каталогом работает рекурсивно, т. е. запаковывает все содержащиеся в нем файлы и подкаталоги.
3)
Что логично, поскольку в системе может быть установлена только одна версия данного пакета. См. подробнее раздел "Конфликты и альтернативы".
4)
Естественно, кроме тех файлов, которые созданы пользователями.
5)
Функции по созданию пакета в формате rpm также выполняет программа rpm.
6)
Слухи о том, что для сборки программы из исходных текстов не обязательно даже знать, что такое "компилятор", далеки от действительности.
7)
Для установки и удаления пакетов нужны права администратора – это серьезные изменения в системе.
8)
Имеет смысл исключать из понятия зависимости использование наиболее стандартных ресурсов, без которых немыслима система Linux как таковая. К таким ресурсам можно отнести системные вызовы и некоторые стандартные файлы, вроде /dev/null.
|
| © 2003-2007 INTUIT.ru. Все права защищены. |
Цепочки зависимостей
Понятие зависимости включает не только зависимость программы от библиотек. Вообще говоря, зависимость возникает там, где программное обеспечение использует любой не поставляемый непосредственно с ним ресурс2). Это могут быть и утилиты, которые запускаются при работе самой программы или во включенных в пакет сценариях, программа-интерпретатор для исполнения этих сценариев и даже определенные файлы, которые должны присутствовать для правильной работы программы (например, утилита passwd предполагает, что существует файл /etc/passwd).
Зависимость может быть и небезусловной. Например, в некоторых случаях нужно обеспечить наличие ресурса не к моменту запуска программы, а прямо к моменту установки пакета. Так, для выполнения доустановочного сценария нужна программа-интерпретатор. В некоторых случаях требуется ресурс строго определенной версии – ни больше, ни меньше. Бывают случаи, когда зависимость имеет обобщенную форму, например, почтовому клиенту (программе для чтения и написания электронной почты) может требоваться служба доставки электронной почты.В Linux такую услугу предоставляют несколько разных программ, и любая из них удовлетворит зависимость.
Разобравшись с понятием зависимости, Мефодий набрался решимости установить-таки нужный ему пакет, установив все, что он потребует. Но не тут-то было: взявшись устанавливать библиотеки, Мефодий выяснил, что каждой из них требуются какие-то еще пакеты, отсутствующие в системе, у каждого из них тоже есть зависимости и т. п. – один-единственный пакет повлек за собой снежный ком других, вытягивая их по цепочкам зависимостей.
Доставка
Важная задача, которую не решает установщик пакетов – доставка файла пакета в систему для последующей установки. Архивы пакетов обычно не хранятся в самой системе: они слишком велики (тысячи пакетов) и должны регулярно обновляться (выход обновлений программ, т. е. новых версий пакетов). Поэтому для установки обычно требуется сначала скопировать необходимые файлы с того носителя, где они хранятся (это либо установочные диски дистрибутива, либо хранилища в сети Интернет).
Чтобы APT мог работать с пакетами, они должны содержаться в организованном по специальным правилам хранилище – репозитории. Список доступных APT репозиториев хранится в файле /etc/apt/sources.list, для каждого репозитория указан способ доступа (например, "cdrom:", "ftp:", "file:" и др.) и адрес:
rpm cdrom:[SomeLinux CD]/ RPM contrib main rpm [sme] ftp://updates.somelinux.com 2.4/i586 updates
Пример 13.12. Файл sources.list (html, txt)
После каждого изменения файла /etc/apt/sources.list нужно обновлять кеш APT, в котором хранятся сведения о доступных пакетах,командой apt-get update. Для того чтобы добавить в кеш информацию о пакетах, доступных на CD, следует использовать команду "apt-cdrom add", а не редактировать sources.list вручную.
APT позволяет и просто доставить пакет в систему, не устанавливая его. Так, например, всегда происходит с исходными пакетами, которые просто копируются из репозитория в определенный каталог системы по команде "apt-get source имя_пакета".
Формат пакета
Помимо хранения архива файлов у пакета есть и другие задачи (они обсуждаются в двух следующих разделах), поэтому для пакета в Linux не очень подходит обычный файловый архив, наподобие .tar, а нужен специальный формат. Таких форматов в Linux бывает несколько (краткое перечисление и характеристика – в разделе "Установщики пакетов"), в системе Мефодия используется один из наиболее распространенных – rpm, поэтому все примеры в данной лекции будут с его участием. Для работы с пакетами в специальном формате нужна специальная программа-установщик, которая так же и называется – rpm: она занимается установкой, удалением, обновлением и проверкой пакетов.
Пакет в формате rpm – это единый файл со всеми необходимыми данными. Существуют определенные (хотя и не очень жесткие и последовательные) соглашения относительно названий файлов-пакетов. Например, rpm-файл, содержащий комплект стандартных утилит coreutils, в системе Мефодия называется coreutils-5.2.1-some5.rpm: сначала – имя пакета, затем через дефис – служебная информация о номерах версий программного обеспечения и самого пакета.
Изменение настроек системы
Для полноценной регистрации пакета в системе обычно недостаточно, чтобы система хранила список файлов, принадлежащих пакету. При установке, удалении или обновлении пакета часто требуется выполнить ряд операций, чтобы обновить сведения о пакете, адаптировать настройки – как самого пакета к уже имеющимся в системе, так и наоборот. К тому же некоторые изменения в системе, например, добавление и удаление псевдопользователя, не сводятся к добавлению и удалению файлов, и вдобавок зависят от текущего состояния системы. Получается, что регистрация в системе – дело не только системы, но и самого пакета. Поэтому в каждом пакете должны храниться сведения о том, какие действия следует выполнять в ходе различных операций с ним – в этом состоит третья задача пакетирования.
Списки необходимых действий представлены в пакете в виде сценариев. Эти сценарии привязаны к процедурам установки и удаления пакета, причем могут быть вызваны по необходимости как до, так и после соответствующей процедуры. В результате процедуры установки и удаления пакета выглядят так:
выполнение предшествующих установке/удалению сценариев;копирование файлов из архива в систему или удаление файлов из системы;выполнение следующих за установкой/удалением сценариев.methody@localhost:~ $ rpm -q --scripts coreutils preinstall scriptlet (through /bin/sh): # Remove info pages from fileutils, textutils and sh-utils. for f in /usr/share/info/{fileutils,textutils,sh-utils}.info*; do [ -f "$f" ] || continue RPM_INSTALL_ARG1=0 /usr/sbin/uninstall_info "$f" ||: done postinstall scriptlet (through /bin/sh): /usr/sbin/install_info coreutils.info preuninstall scriptlet (through /bin/sh): /usr/sbin/uninstall_info coreutils.info
Пример 13.6. Просмотр сценариев в пакете (html, txt)
Мефодий выяснил, что сценарии в пакете coreutils запускаются перед началом установки (preinstall), после установки (postinstall) и перед удалением (preuninstall), они выполняются стандартным командным интерпретатором (/bin/sh). Все эти сценарии нужны для того, чтобы зарегистрировать в системе info установленную пакетом документацию или удалить эту документацию из системы (командами /usr/sbin/install_info и /usr/sbin/uninstall_info соответственно). Поскольку info строит общее оглавление всей имеющейся в системе документации, простого копирования файлов было бы недостаточно.
В результате подобных операций по интеграции пакета в систему могут быть изменены или удалены файлы, не принадлежащие данному пакету, и созданы новые файлы. Если программа, содержащаяся в пакете,пользуется услугами какой-нибудь уже установленной службы (например, syslogd), может понадобиться регистрация этой программы в конфигурационных файлах службы. Конечно, изменение "чужих" файлов в процессе установки пакета нежелательно: впоследствии, удаляя пакет, потребуется вернуть файл в исходное состояние, что не всегда возможно (например, после вдумчивого редактирования администратором). Избежать редактирования конфигурационных файлов позволяет схема ".d",описанная в лекции 10.
Конфликты и альтернативы
В противоположность зависимости, когда пакет не может быть установлен при отсутствии некоторого другого, конфликт пакетов – это ситуация, когда пакет не может быть установлен при наличии некоторого другого, т. е. они несовместимы в рамках одной системы. Одна из причин возникновения конфликтов уже упоминалась выше – в пакетах есть файлы с совпадающими именами. Самый распространенный источник конфликтов – программы, которые предоставляют разные реализации одной и той же функциональности системы (например, службы доставки электронной почты или печати, программы проверки орфографии, компиляторы и т. п.). Можно было бы, конечно, просто назвать конфликтующие файлы по-разному, но и тогда путаница неизбежна: если, допустим, старый компилятор Си называется gcc2.96, а новый – gcc3.3, то что запускается по стандартной команде gcc? В каждом пакете должна содержаться информация о том, с какими пакетами он конфликтует. Конфликт пакетов может быть разрешен очень просто: следует удалить один из конфликтных пакетов, после чего свободно устанавливать другой.
Каждый пакет, помимо имени, обозначен и номером версии, указывающим степень обновленности содержащегося в пакете программного обеспечения и самого пакета. В системе одновременно может быть установлена только одна версия любого пакета, со всеми остальными версиями она конфликтует. Такой подход вполне понятен, поскольку файлы в пакете имеют строго определенный путь, по которому они должны быть размещены в файловой системе. Поэтому при использовании пакетов не должно (и не может) возникнуть ситуации, когда одна и та же программа установлена в разных местах файловой системы.
Однако не все функции в системе должны эксклюзивно выполняться одной программой. Например, в системе может быть установлено сколько угодно текстовых редакторов и даже несколько разных реализаций одного редактора, например, Vi (Vim и NVi). Пакеты Vim и NVi не конфликтуют друг с другом, но оба с равным основанием могут быть вызваны по команде vi. Чтобы определить, какой именно из них запускать как vi, во многих дистрибутивах Linux (в частности, в том, который использует Мефодий) применяется механизм альтернатив. Альтернативы– это система символьных ссылок на принадлежащие пакетам файлы. Однотипные файлы из пакетов называются по-разному, а символьная ссылка, к которой обращается пользователь, указывает на один из них. Например, файл /usr/bin/vi будет символьной ссылкой либо на /usr/bin/vim, либо на /usr/bin/nvi (то же самое относится и к руководствам по этим редакторам). При установке и удалении любого из пакетов с одной из альтернативных программ символьная ссылка автоматически обновляется. На какую из них будет указывать ссылка, решается на основании веса каждого пакета. Вес – это условное число, выбирается та альтернатива из установленных, у которой наибольший вес. Пользователь может вмешаться в выбор альтернатив и вручную. Все необходимые утилиты для работы с альтернативами предоставляет пакет alternatives.
Контроль целостности
Поскольку менеджер пакетов умеет строить цепочки зависимостей пакетов друг от друга, с его помощью всегда можно определить, все ли зависимости удовлетворены у пакетов, установленных в системе. Система,в которой нет пакетов с неудовлетворенными зависимостями, называется целостной. Если целостность нарушена, это означает, что часть установленного в системе программного обеспечения попросту неработоспособна или работает некорректно.
Целостность системы может нарушиться в момент каких-то изменений в ее составе: при установке, удалении или обновлении части пакетов или всей системы. Если для всех этих операций использовать менеджер пакетов, то целостность системы не должна нарушиться. Хотя иногда даже менеджеру пакетов бывает сложно найти правильное решение, чтобы удовлетворить все зависимости и устранить конфликты. При наличии менеджера пакетов механизм зависимостей можно обернуть и на пользу человеку. Так, можно создать пакет, в котором есть только зависимости и нет никаких ресурсов – такой пакет называется виртуальным. Это бывает полезно в том случае, когда нужно упростить пользователю установку полной среды для выполнения какой-либо задачи. Необходимые для этого пакеты могут напрямую не зависеть друг от друга, но чтобы установить их все за один шаг, пользователю будет достаточно установить один –виртуальный – пакет. Таким виртуальным пакетом оказался сам пакет python в примере, и еще один – python-strict:
[root@localhost shogun]# rpm -ql python (не содержит файлов) [root@localhost shogun]# rpm -ql python-strict (не содержит файлов)
Пример 13.11. Виртуальные пакеты не содержат файлов (html, txt)
Именно поэтому apt "получил" 15 пакетов (включая два виртуальных), а "совершил изменения" только для 13-ти.
Менеджеры пакетов
Установщики пакетов делают атомарными (одношаговыми) операции с отдельными пакетами: вместо копирования множества файлов и запуска нескольких сценариев пользователь вводит одну команду "установить/удалить пакет". Атомарная с точки зрения пользователя операция – добавление в систему одного нового компонента может состоять из нескольких (и даже многих) операций над пакетами. Мефодий уже столкнулся с подобным случаем, изучая на собственном опыте понятие "цепочка зависимостей". Здесь установщики пакетов никак не могут облегчить работу пользователя. Чтобы сделать процедуру установки, удаления и обновления компонента системы атомарной, были разработаны менеджеры пакетов. Менеджер пакетов – это программа, вычисляющая весь комплекс операций над отдельными пакетами, который нужно произвести для установки/удаления нового компонента (пакета), и сама запускает установщик пакетов необходимое количество раз с соответствующими параметрами. Кроме того, менеджер пакетов хранит информацию не только о пакетах, уже установленных в системе, но и обо всех, которые доступны для установки с какого-либо носителя или по Сети (подробнее об этом в разделе "Доставка").
Менеджер пакетов. Программа, выполняющая установку, удаление или обновление любого пакета или группы пакетов и автоматически выполняющая все необходимые для этого процедуры (доставку пакетов из удаленных репозиториев, вычисление зависимостей и установку требуемых по ним пакетов, удаление замещаемых пакетов и т. п.).
Наиболее известный и популярный менеджер пакетов называется APT (Advanced Package Tool). Первоначально он был разработан в рамках дистрибутива Debian и работал только с установщиком пакетов dpkg, впоследствии для других дистрибутивов была разработана версия, работающая с rpm. В дистрибутиве Мефодия также используется APT.
Чтобы установить пакет, прежде всего нужно узнать о его существовании. Пакетов для каждого дистрибутива Linux доступны тысячи и даже десятки тысяч, и ориентироваться в них непросто. APT предоставляет возможность поиска нужного среди доступных пакетов, для этого используется утилита apt-cache. В каждом пакете обязательно имеется краткая аннотация (в одну строку) и небольшое описание содержащихся в пакете ресурсов (не длиннее нескольких абзацев). По команде "apt-cache search подстрока" APT найдет и выведет список из имен и аннотаций пакетов, где в имени, аннотации или описании нашлась указанная подстрока:
Пример 13.9. Поиск пакетов в APT (html, txt)
Для установки и удаления пакетов предназначена утилита apt-get, а команда установки выглядит совсем просто: "apt-get install имя_пакета", причем не нужно указывать никаких сведений о версии и местонахождении пакета: APT сам найдет и установит самую последнюю из доступных версий:
Пример 13.10. Установка пакета с помощью APT (html, txt)
Процедуру установки APT выполняет в несколько этапов: сначала он ищет запрошенный пакет в списках доступных, найдя, рассчитывает, какие пакеты следует установить, чтобы удовлетворить его зависимости, после чего получает файлы всех нужных пакетов (в данном случае APT нашел нужные пакеты на диске CD-ROM) и запускает установщик пакетов последовательно для установки всего необходимого. Аналогично, чтобы удалить пакет, достаточно выполнить команду "apt-get remove имя_пакета".
Кроме APT, есть еще несколько менеджеров пакетов. Большинство из них специфичны для определенного дистрибутива, как, например,emerge для Gentoo или YaST для SuSE. Их задачи и возможности примерно совпадают с APT.
Обновление
Программное обеспечение в мире Linux (и не только) постоянно обновляется: исправляются ошибки, расширяются возможности. Разработчики каждого дистрибутива по мере выхода новых версий программ готовят новые версии соответствующих пакетов и делают их доступными в своем репозитории (репозитории, отражающие наиболее современное состояние программного обеспечения, доступны через Internet). Пользователю имеет смысл не отставать от обновлений программного обеспечения, потому что новые версии программ – это и большая надежность работы системы, и новые возможности.
Менеджеры пакетов позволяют выполнять комплексные обновления всей системы. В APT эту процедуру можно выполнить одной командой: "apt-get dist-upgrade". Эта процедура сначала исследует содержимое всех доступных репозиториев и находит там все пакеты более поздних версий, чем соответствующие пакеты, установленные в системе. После этого вычисляется объем обновления: должна быть удалена связанная область зависящих друг от друга устаревших пакетов и заменена соответствующей областью более новых версий. Сложные ситуации могут возникать в том случае, если изменилось распределение ресурсов по пакетам: пакеты были разделены или объединены – здесь может потребоваться вмешательство пользователя.
Тот род обновлений системы, который нужно выполнять регулярно и обязательно – это обновления, связанные с безопасностью (security updates). Когда в программе обнаруживают и исправляют серьезные ошибки, угрожающие безопасности всей системы, разработчики дистрибутивов обычно заботятся о том, чтобы соответствующие обновления дошли до пользователя. Обычно присутствует отдельный репозиторий с обновлениями, существенными для безопасности.
Пакеты
Пригодная для работы пользователя система состоит из множества (сотен и тысяч) программ и утилит. В Linux каждый компонент системы представлен в виде пакета. Все операции, связанные с изменением состава системы – установка, удаление, проверка, обновление компонентов, –производятся над пакетами. В целом, пакет – это средство сделать так, чтобы пользователь-администратор, изменяя или обновляя программное наполнение системы, работал не с файлами (имена которых ему подчас неизвестны), а с определенными функциями самой системы: например,добавлял в нее не "500 файлов", а "WWW-сервер apache".
Создание файлового архива при помощи
| methody@localhost:~ $ tar -cf methody.progs.tar bin/ methody@localhost:~ $ tar -tf methody.progs.tar bin/ bin/loop bin/script bin/to.sort bin/two |
| Пример 13.1. Создание файлового архива при помощи tar |
| Закрыть окно |
| methody@localhost:~ $ tar -xvf methody.progs. tar bin/ bin/loop bin/script bin/to.sort bin/two |
| Пример 13.2. Распаковка архива |
| Закрыть окно |
| methody@localhost:~ $ rpm -qa | grep coreutils coreutils-5.2.1-some5 methody@localhost:~ $ rpm -ql coreutils | grep bin /bin/basename /bin/cat /bin/chgrp /bin/chmod . . . |
| Пример 13.3. Какие файлы принадлежат пакету? |
| Закрыть окно |
| methody@localhost:~ $ rpm -qf /etc/passwd setup-2.2.5-some1 |
| Пример 13.4. Какому пакету принадлежит файл? |
| Закрыть окно |
| methody@localhost:~ $ rpm - V setup S.5....T c /etc/X11/fs/config S.5....T c /etc/exports S.5....T c /etc/fstab S.5....T c /etc/printcap ..?..... c /etc/securetty |
| Пример 13.5. Что изменилось в пакете? |
| Закрыть окно |
| methody@localhost:~ $ rpm -q --scripts coreutils preinstall scriptlet (through /bin/sh): # Remove info pages from fileutils, textutils and sh-utils. for f in /usr/share/info/{fileutils,textutils,sh-utils}.info*; do [ -f "$f" ] || continue RPM_INSTALL_ARG1=0 /usr/sbin/uninstall_info "$f" ||: done postinstall scriptlet (through /bin/sh): /usr/sbin/install_info coreutils.info preuninstall scriptlet (through /bin/sh): /usr/sbin/uninstall_info coreutils.info |
| Пример 13.6. Просмотр сценариев в пакете |
| Закрыть окно |
| methody@localhost:~ $ rpm -qi setup Name : setup Relocations: (not relocateable) Version : 2.2. 5 Vendor: Some Linux Team Release : some1 Build Date: Чтв 29 Янв 2004 18:08:05 Install date: Пнд 23 Авг 2004 15:08:45 Build Host: shogun.somelinux.org Group : Система/Настройка/Прочее Source RPM: setup-2.2.5-some1.src.rpm Size : 39969 License: GPL Packager : Leon B. Gourievitch Summary : Initial set of configuration files Description : Initial set of configuration files to be placed into /etc. |
| Пример 13.7. Описание пакета |
| Закрыть окно |
| [root@localhost RPMS.local]# rpm -i xsltproc-1.0.32-some1.i586. rpm ошибка: неудовлетворенные зависимости: libxslt = 1.0.32-some1 нужен для xsltproc-1.0.32-some1 [root@localhost RPMS.local]# |
| Пример 13.8. Пакет не установлен из-за неудовлетворенных зависимостей |
| Закрыть окно |
| [root@localhost shogun]# apt-cache search python | wc 146 1158 8994 [root@localhost shogun]# apt-cache search python | grep "programming" python – An interpreted, interactive object-oriented programming language |
| Пример 13.9. Поиск пакетов в APT |
| Закрыть окно |
| [root@localhost shogun]# apt- get install python Чтение списков пакетов... Завершено Построение дерева зависимостей... Завершено Следующие дополнительные пакеты будут установлены: libpython libgdbm libgmp python-base python-modules python-modules-bsddb python-modules-compiler python-modules-curses python-modules-email python-modules-encodings python-modules-hotshot python-modules-logging python-modules-xml python-strict Следующие НОВЫЕ пакеты будут установлены: libpython libgdbm libgmp python python-base python-modules python-modules-bsddb python-modules-compiler python-modules-curses python-modules-email python-modules-encodings python-modules-hotshot python-modules-logging python-modules-xml python-strict 0 будет обновлено, 15 новых установлено, 0 пакетов будет удалено и 0 не будет обновлено. Необходимо получить 0B/4466kB архивов. После распаковки потребуется дополнительно 16,9MB дискового пространства. Продолжить? [Y/n] y Получено: 1 cdrom://SomeLinux CD RPM/main libpython 2.3.3-some2 [17,4kB] Получено: 2 cdrom://SomeLinux CD RPM/main libgdbm 1.8.3-some3 [25,6kB] Получено: 3 cdrom://SomeLinux CD RPM/main libgmp 4.1.2-some3 [153kB] . . . Получено: 14 cdrom://SomeLinux CD RPM/main python-base 2.3.3-some12 [782kB] Получено: 15 cdrom://SomeLinux CD RPM/main python 2.3.3-some12 [11,5kB] Получено 4466kB за 0s (19,5MB/s). Совершаем изменения... Preparing... ######################################### [100%] 1: libpython ######################################### [ 6%] 2: libgdbm ######################################### [ 13%] 3: libgmp ######################################### [ 20%] 4: python-base ######################################### [ 26%] . . . 13: python-modules-logging ######################################### [ 86%] Завершено. |
| Пример 13.10. Установка пакета с помощью APT |
| Закрыть окно |
| [root@localhost shogun]# rpm -ql python (не содержит файлов) [root@localhost shogun]# rpm -ql python-strict (не содержит файлов) |
| Пример 13.11. Виртуальные пакеты не содержат файлов |
| Закрыть окно |
| rpm cdrom:[SomeLinux CD]/ RPM contrib main rpm [sme] ftp://updates.somelinux.com 2.4/i586 updates |
| Пример 13.12. Файл sources.list |
| Закрыть окно |
Регистрация в системе
Итак, пакет с компонентом системы – это в первую очередь файловый архив, в котором хранятся все необходимые файлы вместе с путями к ним (т. е. каталогами). Когда компонентов много, нужно сделать так, чтобы в разных пакетах не оказалось файлов с одинаковым именем и путем,чтобы файл, принадлежащий одному пакету, не мог быть заменен файлом другого пакета при установке. Отслеживать такого рода конфликты пакетов – вторая задача пакетирования.
Чтобы предупреждать конфликты, в системе должна храниться информация обо всех уже установленных пакетах и принадлежащих им файлах. Когда точно известно, какие файлы принадлежат пакету, можно полностью удалить пакет, не оставив и не удалив при этом ничего лишнего.Такой подход препятствует образованию в системе "мусора" – бесполезных файлов, оставшихся от удаленных программ – и делает операцию установки/удаления пакета полностью обратимой.
Rpm хранит информацию обо всех установленных в системе пакетах и принадлежащих им файлах и может выдать эту информацию по запросу пользователя. Почитав руководство по rpm, Мефодий выяснил, что список всех установленных в системе пакетов (скорее всего, очень длинный, в несколько тысяч строк) можно получить командой "rpm -qa",список всех файлов, принадлежащих пакету, – командой "rpm -ql имя_пакета". Он решил проверить, есть ли в его системе уже известный ему по предыдущим лекциям пакет coreutils и узнать, какие утилиты ему принадлежат:
methody@localhost:~ $ rpm -qa | grep coreutils coreutils-5.2.1-some5 methody@localhost:~ $ rpm -ql coreutils | grep bin /bin/basename /bin/cat /bin/chgrp /bin/chmod . . .
Пример 13.3. Какие файлы принадлежат пакету? (html, txt)
Мефодий получил довольно длинный список имен файлов, среди которых встретил многие из уже знакомых ему утилит и кое-какие незнакомые. Причем запрашивая список файлов, Мефодий использовал только имя пакета, без версии – rpm позволяет обращаться так к любому из установленных пакетов1).
Можно выполнить и обратную процедуру – выяснить про любой файл, какому пакету он принадлежит:
methody@localhost:~ $ rpm -qf /etc/passwd setup-2.2.5-some1
Пример 13.4. Какому пакету принадлежит файл? (html, txt)
Файлы, принадлежащие пакету, могут быть не только удалены, но и изменены. Это может быть сделано сознательно (например, отредактирован конфигурационный файл), и в таком случае при обновлении или удалении пакета измененный файл нужно сохранить, потому что в нем содержится результат работы, проделанной администратором. Для этого система должна уметь определять, что принадлежащий пакету файл изменился. Для этого в пакете должна храниться информация обо всех файлах архива: размер, атрибуты, контрольная сумма – в этом случае процедура проверки сможет убедиться в соответствии атрибутов файла в пакете атрибутам установленного в системе файла. Мефодий может проверить, что изменилось в пакете командой "rpm -V имя_пакета":
methody@localhost:~ $ rpm -V setup S.5....T c /etc/X11/fs/config S.5....T c /etc/exports S.5....T c /etc/fstab S.5....T c /etc/printcap ..?..... c /etc/securetty
Пример 13.5. Что изменилось в пакете? (html, txt)
Мефодий получил список изменившихся с момента установки пакета файлов. Видимо, все это – конфигурационные файлы, отредактированные администратором системы. Мефодий догадался, что комбинация цифр, букв и точек – это список атрибутов, по которым rpm сравнивал установленные файлы с данными пакета, однако чтобы разобраться, что именно означает каждая буква, ему придется внимательнее читать руководство.
Система Linux раскладывается на компоненты без остатка: каждый файл в Linux принадлежит какому-нибудь (и только одному!) пакету2). Это позволяет свести любые изменения в составе системы к операциям над пакетами – от начальной установки до сложных комплексных обновлений. В этом случае для всех изменений будет использоваться одна и та же программа-установщик, например, rpm.
Пример 13.4. Какому пакету принадлежит файл?
Файлы, принадлежащие пакету, могут быть не только удалены, но и изменены. Это может быть сделано сознательно (например, отредактирован конфигурационный файл), и в таком случае при обновлении или удалении пакета измененный файл нужно сохранить, потому что в нем содержится результат работы, проделанной администратором. Для этого система должна уметь определять, что принадлежащий пакету файл изменился. Для этого в пакете должна храниться информация обо всех файлах архива: размер, атрибуты, контрольная сумма – в этом случае процедура проверки сможет убедиться в соответствии атрибутов файла в пакете атрибутам установленного в системе файла. Мефодий может проверить, что изменилось в пакете командой "rpm -V имя_пакета":
methody@localhost:~ $ rpm -V setup S.5....T c /etc/X11/fs/config S.5....T c /etc/exports S.5....T c /etc/fstab S.5....T c /etc/printcap ..?..... c /etc/securetty
Пример 13.5. Что изменилось в пакете?
Мефодий получил список изменившихся с момента установки пакета файлов. Видимо, все это – конфигурационные файлы, отредактированные администратором системы. Мефодий догадался, что комбинация цифр, букв и точек – это список атрибутов, по которым rpm сравнивал установленные файлы с данными пакета, однако чтобы разобраться, что именно означает каждая буква, ему придется внимательнее читать руководство.
Система Linux раскладывается на компоненты без остатка: каждый файл в Linux принадлежит какому-нибудь (и только одному!) пакету4). Это позволяет свести любые изменения в составе системы к операциям над пакетами – от начальной установки до сложных комплексных обновлений. В этом случае для всех изменений будет использоваться одна и та же программа-установщик, например, rpm.
Установщики пакетов
Для выполнения всех операций над пакетами требуется специальная программа – установщик пакетов. В ее задачи входит весь цикл работ с пакетом: от создания пакета (компиляции исходного пакета> в двоичный), до его установки, удаления, обновления, а также хранение и вывод по запросу пользователя или системы информации об установленных и неустановленных пакетах, принадлежащих им файлах и т. п.
В Linux формат пакетов не унифицирован, распространено несколько различных форматов, и для каждого из них требуется собственный установщик пакетов. Наиболее известны уже описанный rpm, dpkg, используемый в Debian (см. подробнее лекцию 18), а также пакеты в формате tgz (он же tar.gz – файловый архив tar, сжатый упаковщиком gzip, GNU Zip), то есть обычные файловые архивы, где вся необходимая в пакете метаинформация упакована в виде файлов наряду с файлами программного обеспечения. Установщики пакетов различаются не только форматом пакетов, с которыми они работают, но и кругом возможностей, внутренним форматом хранения информации и т. д.
Установщик пакетов. Программа, выполняющая основные операции с пакетами: установку, удаление, проверку, вывод информации о пакетах.
В рамках этой лекции мы ограничимся обсуждением только одного из установщиков пакетов – rpm (Red Hat Package Manager). Он первоначально возник в дистрибутиве RedHat, но в настоящее время используется и во многих других дистрибутивах. Пожалуй, сейчас его можно назвать самым распространенным форматом: авторы программ для Linux обычно выкладывают свои программы в Internet в виде файловых архивов tgz и пакетов rpm.
Обратной стороной популярности rpm является его нестандартность. Под расширением .rpm довольно редко оказывается канонический формат, разрабатываемый RedHat. В формате rpm усматривают много недостатков и недоделок, поэтому распространено множество усовершенствованных и дополненных версий rpm, и, соответственно, пакетов,ориентированных на какую-нибудь из этих версий, но носящих все то же расширение. На практике это означает, что разные версии rpm не полностью совместимы между собой, поэтому даже если в вашей системе используется rpm, из этого совершенно не следует, что вы сможете установить любой найденный в Internet пакет в этом формате.
Случай rpm – только самое яркое проявление более общей проблемы: в общем случае ни в одном дистрибутиве нельзя без потерь, помех или ручного вмешательства установить пакет, не разработанный специально для данного дистрибутива. В следующем разделе ("Менеджеры пакетов") изложены некоторые соображения, почему это нежелательно, и почему следует по возможности пользоваться именно "родными" пакетами,а если их нет – создавать их самостоятельно.
Другая проблема установщиков пакетов заключается в том, что они годятся только для установки/удаления отдельных пакетов, но не предназначены для доставки пакетов в системы (пользователь сам должен найти и скачать нужный пакет, а также указать местоположение файла пакета установщику в командной строке). Кроме того, установщик работает с каждым пакетом по отдельности: он может указать, что не удовлетворены некоторые зависимости, или имеют место конфликты, но не в состоянии в ходе процедуры установки ни установить все необходимые пакеты по цепочке зависимостей, ни удалить конфликтующие – пользователь должен делать это вручную. Установщики пакетов не предоставляют также никаких средств по автоматизации обновления системы.
Зависимости
Мефодий нашел в Internet пакет с заинтересовавшей его программой в подходящем формате rpm и решил попробовать его установить1):
[root@localhost RPMS.local]# rpm -i xsltproc-1.0.32-some1.i586.rpm ошибка: неудовлетворенные зависимости: libxslt = 1.0.32-some1 нужен для xsltproc-1.0.32-some1 [root@localhost RPMS.local]#
Пример 13.8. Пакет не установлен из-за неудовлетворенных зависимостей (html, txt)
Однако rpm отказался выполнять установку, ссылаясь на зависимость от другого пакета. Здесь Мефодий впервые столкнулся с тем, что пакеты – не всегда (точнее, почти никогда) бывают независимы от имеющейся системы. В разделе "Архив файлов" уже говорилось о том, что для работы программы нужны различные ресурсы, причем несколько программ могут нуждаться в одном и том же ресурсе. В последнем случае общий ресурс может оказаться в отдельном собственном пакете (чтобы не включать его сразу в несколько), и этот пакет должен быть установлен в системе, чтобы заработали нуждающиеся в нем программы. Потребность пакета в ресурсах, находящихся в другом пакете, называют зависимостью этого пакета от другого. В процедуре установки rpm проверяет,все ли зависимости устанавливаемого пакета удовлетворены (т. е. все ли необходимые пакеты уже установлены в системе), и если чего-то не хватает – прекращает установку. Именно с такой ситуацией и столкнулся Мефодий.
Зависимость пакетов. Ситуация, при которой пакет не может быть установлен в систему, если в ней не установлен хотя бы один из некоторого множества пакетов. Аналогично, пакет не может быть удален из системы до тех пор, пока в ней установлен хотя бы один зависящий от него пакет.
